




前言:
因为平常上课还有导师布置了很多课题上面的任务,导致每天在项目的时间很少、很零碎,所以停更了每天的学习日记,并且之前看到了牛客的博主程序员牛肉的经验分享所以也想写一下这种万字总结,文章构成的一些结构和逻辑也做了他的一些参考,特此声明一下。我会逐一介绍外卖项目的整体架构和所用的技术以及我个人的一些思考。
项目介绍:
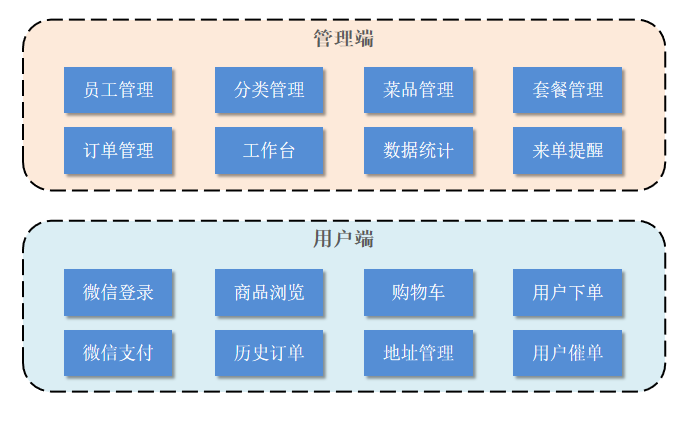
苍穹外卖项目是专门为餐饮企业定制的一款软件产品。包括 系统后台管理端 和 小程序端应用 两部分。其中系统管理后台主要提供给餐饮企业内部员工使用,可以对餐厅的分类、菜品、套餐、订单、员工等进行管理维护,对餐厅的各类数据进行统计,同时也可进行来单语音播报功能。小程序端主要提供给消费者使用,可以在线浏览菜品、添加购物车、下单、支付、催单等。
后台管理端
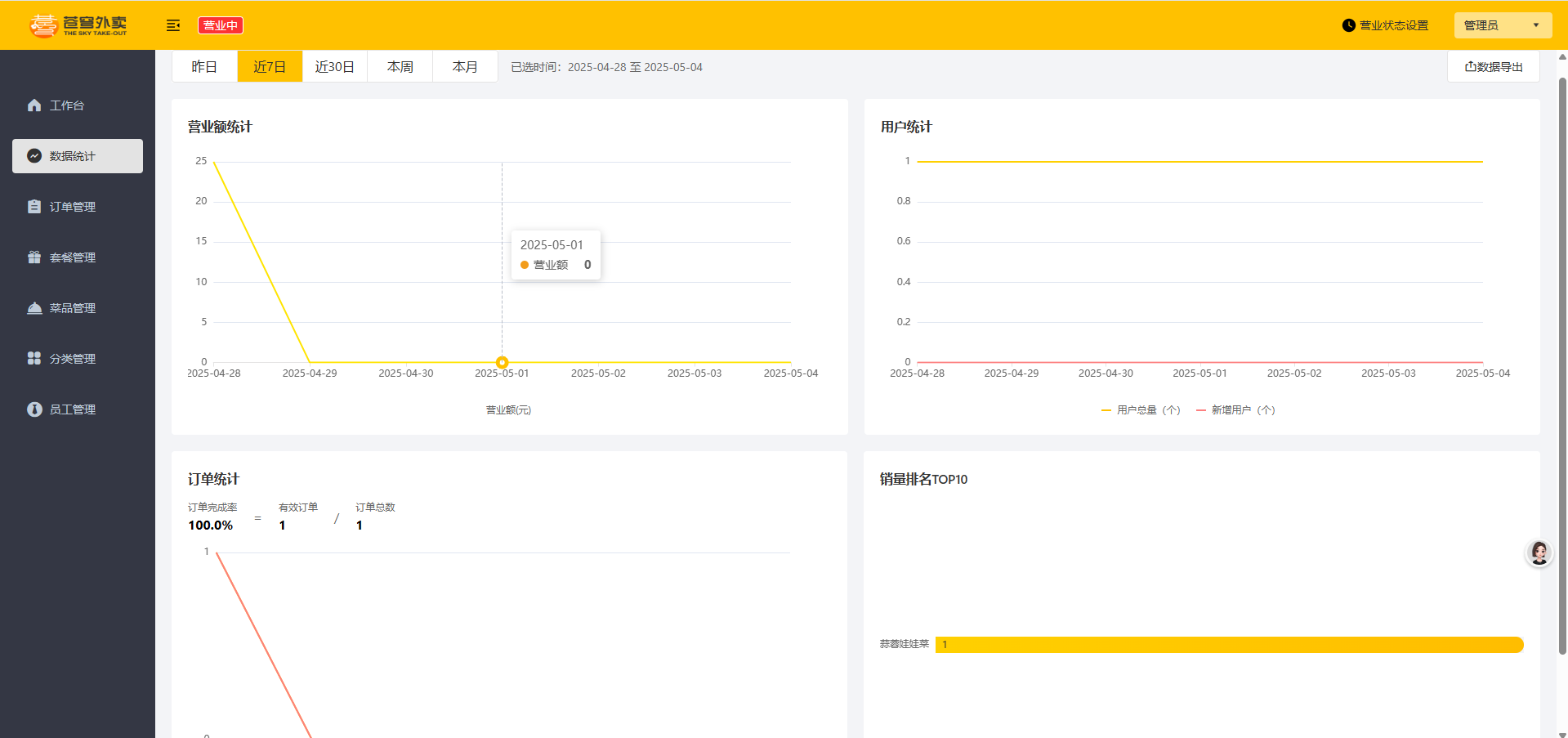
用户小程序端
 PS: 有些照片不显示是因为这些照片没有上传到我本人的阿里云OSS中。
PS: 有些照片不显示是因为这些照片没有上传到我本人的阿里云OSS中。
业务板块介绍:
技术选型:
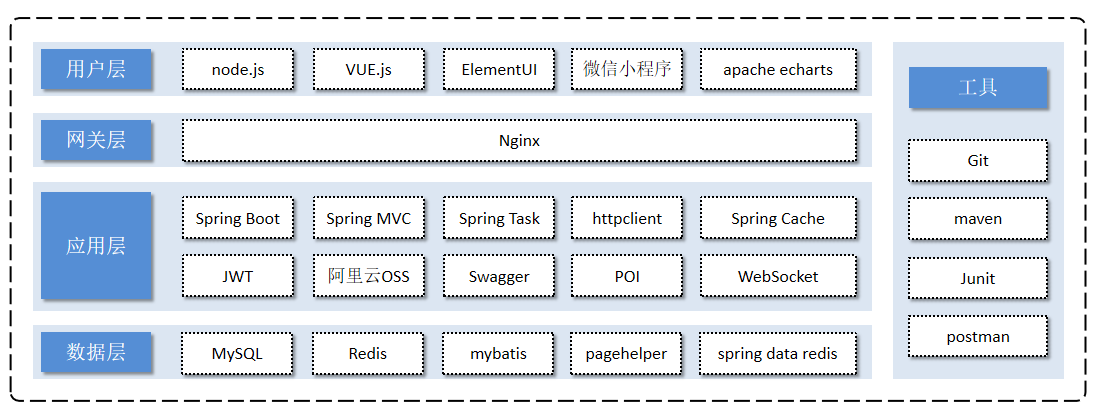
用户层:
本项目在构建前端页面时,用到了H5、Vue.js、ElementUI、apache echarts等技术。而在构建移动端时,用到的是微信小程序。
网关层:
Nginx:主要功能是充当Http服务器,可用于部署静态资源,访问性能高。Nginx有两个重要的作用:反向代理和负载均衡。反向代理是指代理服务器接受互联网上的请求,然后把请求转发给内部网络的服务器,并将内部服务器的响应返回给互联网用户。负载均衡就是比如多个用户同时访问网站,负载均衡就会把这些访问请求合理的分配到不同的服务器上,避免单个服务器压力过大。
应用层:
SpringBoot:他能快速的搭建Spring项目,让Spring鲜蘑菇配置开发更加简单。
SpringMVC:作为Spring框架的模块,与Spring无缝集成,无需中间整合层。
Spring Task:由Spring提供的定时任务框架,可以设置任务在指定时间或者间隔执行。
httpclient:主要作用是发送http请求,实现与其他服务器交互。
Spring Cache:由Spring提供的数据缓存框架,能缓存数据来提高系统的性能。比如缓存经常查询且不常变化的数据库数据,以减少数据库的IO操作。
JWT:令牌技术,用于应用程序用户身份验证的标记,通过验证标记确认用户身份。例如在用户登录后,服务器会生成一个JWT令牌给客户端,后续的客户端请求会携带此标记来验证身份。
阿里云OSS:对象存储服务,在项目中主要存储图片和文件到阿里云OSS中。
Swagger:能自动为开发人员生成接口文档,并对接口进行测试。
POI:封装了对Excel表格常用操作,可实现Excel的读写等功能。
WebSocket:一种通信网络协议,简化客户端和服务器间数据交换,容许客户端和服务器进行持久化连接,并且与请求—响应有所不同,WebSocket实现了客户端与服务器的双向通信。
数据层:
MySQL:关系型数据库,以二维表的形式来存储数据,数据是直接存储的磁盘当中的。
Redis:基于key—value格式存储的内存数据库,访问速度快,在很多项目中常被用来作为缓存,减少后端数据库的频繁访问。
Mybatis:是一款持久层框架,在本项目里,用他来处理数据持久化相关操作,比如数据库的增删改查,平且可以方便地将java对象与数据库表进行映射。
pagehelper:是一个用于实现分页功能的插件,可以方便的对查询出来的数据进行分页处理。以注解的方式使用,简化了分页的相关操作。
spring data redis:简化java代码操作Redis的API。
工具:
git:版本控制工具,主要用于在团队协作开发项目时,对项目中的代码进行有效的管理,比如记录代码的修改历史、方便不同成员协作开发、回溯到之前的代码版本等。
maven:项目构建工具、能帮助开发者管理项目的依赖关系,自动编译、测试、打包项目等。
junit:单元测试工具,开发人员功能实现完毕后,需要通过junit对功能进行单元测试。
postman: 接口测工具,模拟用户发起的各类HTTP请求,获取对应的响应结果。
后端初始环境介绍:
sky-common层:
模块中存放的是一些公共类,可以供其他模块使用。
| 包名 | 作用 |
| constant | 封装各种常量类,代替硬编码 |
| context | 封装基础上下文类 |
| enumeration | 封装各种枚举类 |
| exception | 封装各种异常类 |
| json | 处理json转换的类 |
| properties | 存放Spring boot的相关配置的类 |
| result | 封装各种返回结果的类 |
| utils | 封装各种工具类 |
sky-pojo层:
模块中存放的是一些 entity、DTO、VO.
| 名称 | 说明 |
| dto | 提供实体,封装前端发送给后端的数据,方便后端处理 |
| entity | 提供各种实体类,例如员工类 |
| vo | 提供实体,封装后端发送给前端的数据,方便前端处理 |
sky-server层:
模块中存放的是 配置文件、配置类、拦截器、controller、service、mapper、启动类等.
| 包名 | 作用 |
| annotation | 存放自定义注解 |
| aspect | 存放各种切面 |
| config | 存放各种配置类 |
| controller | 存放各种处理前端请求的方法,向下还细分为管理端,用户端,通用端 |
| handler | 封装和处理异步任务,事件或消息。 |
| interceptor | 存放拦截器,按照指定条件拦截前端请求 |
| mapper | 存放mapper接口 |
| service | 存放service类 |
| Task | 任务类,存放各种任务 |
| websocket | 封装websocket,简化websocket的使用。 |
项目所用技术:
JWT令牌加密技术:
JWT是JSON Web Token的简称。简单来说是一个JSON对象,在这个对象中包含一些关键的属性声明,JWT最关键的特性是:如果要去验证JWT令牌是否有效,我们只需要检查JWT令牌本身就可以,而不需要依赖任何其它服务,也不需要把JWT令牌存储在第三方服务的缓存中,每次都去请求校验,因为JWT令牌自身会携带消息认证码MAC(Message Authentication Code),对JWT包体信息进行签名。
一个JWT令牌通常是由以下三个部分组成:头部(Header)、包体(Payload)和签名(Signature)。

通俗来说,JWT的本质就是一个字符串,它将用户信息保持到一个Json字符串中,然后进行编码得到一个JWT token,并且这个JWT token带有前面信息,接收后可以校验是否被篡改,所以可用于在各方之间安全的将信息作为Json对象传输。主要流程如下:
1、首先,前端通过Web表单将自己的用户名和密码发送到后端的接口,这个过程一般是一个POST请求。
2、后端核对用户名和密码成功后,将包含用户信息的数据作为JWT的Payload,将其与JWT Header分别进行Base64编码拼接后签名,形成一个JWT Token,形成的JWT Token就是一个如同lll.zzz.xxx的字符串
3、后端将JWT Token字符串作为登录成功的结果返回给前端。前端可以将返回的结果保存在浏览器中,退出登录时删除保存的JWT Token即可
4、前端在每次请求时将JWT Token放入HTTP请求头中的Authorization属性中
5、后端检查前端传过来的JWT Token,验证其有效性,比如检查签名是否正确、是否过期、token的接收方是否是自己等等
6、验证通过后,后端解析出JWT Token中包含的用户信息,进行其他逻辑操作(一般是根据用户信息得到权限等),返回结果
在本项目中通过JWT令牌技术实现了:
用户身份认证
在用户登录苍穹外卖系统时,服务器会对用户提交的用户名和密码进行验证。若验证通过,服务器会生成一个 JWT 令牌并返回给客户端。此后,客户端在发起需要身份验证的请求时,要在请求头里携带这个 JWT 令牌。服务器收到请求后,会对令牌进行解析和验证,以此确认请求是否来自合法用户。
信息交换
JWT 令牌能够在客户端和服务器之间安全地传递信息。令牌中可以包含用户的相关信息,像用户 ID、用户名等。服务器在解析令牌后,就能获取这些信息,进而根据这些信息为用户提供对应的服务。
无状态会话管理
苍穹外卖项目采用 JWT 实现无状态会话管理。传统的会话管理方式需要服务器存储会话信息,而 JWT 令牌包含了所有必要的用户信息,服务器无需在本地存储会话状态。这样,服务器在处理请求时,仅需验证令牌的有效性,就可以确定用户身份,从而减轻了服务器的存储压力。
登录生成JWT代码
/**
* 登录
*
* @param employeeLoginDTO
* @return
*/
@PostMapping("/login")
public Result<EmployeeLoginVO> login(@RequestBody EmployeeLoginDTO employeeLoginDTO) {
log.info("员工登录:{}", employeeLoginDTO);
Employee employee = employeeService.login(employeeLoginDTO);
//登录成功后,生成jwt令牌
Map<String, Object> claims = new HashMap<>();
claims.put(JwtClaimsConstant.EMP_ID, employee.getId());
String token = JwtUtil.createJWT(
jwtProperties.getAdminSecretKey(),
jwtProperties.getAdminTtl(),
claims);
EmployeeLoginVO employeeLoginVO = EmployeeLoginVO.builder()
.id(employee.getId())
.userName(employee.getUsername())
.name(employee.getName())
.token(token)
.build();
return Result.success(employeeLoginVO);
}登录验证代码(拦截器)
/**
* 校验jwt
*
* @param request
* @param response
* @param handler
* @return
* @throws Exception
*/
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
//判断当前拦截到的是Controller的方法还是其他资源
if (!(handler instanceof HandlerMethod)) {
//当前拦截到的不是动态方法,直接放行
return true;
}
//1、从请求头中获取令牌
String token = request.getHeader(jwtProperties.getAdminTokenName());
//2、校验令牌
try {
log.info("jwt校验:{}", token);
Claims claims = JwtUtil.parseJWT(jwtProperties.getAdminSecretKey(), token);
Long empId = Long.valueOf(claims.get(JwtClaimsConstant.EMP_ID).toString());
log.info("当前员工id:", empId);
//通过ThreadLocal来存储empId,使得它在同一个线程的其他包中可以使用
BaseContext.setCurrentId(empId);
//3、通过,放行
return true;
} catch (Exception ex) {
//4、不通过,响应401状态码
response.setStatus(401);
return false;
}
}JWT工具包代码(JWT令牌的加密与解密)
/**
* 生成jwt
* 使用Hs256算法, 私匙使用固定秘钥
*
* @param secretKey jwt秘钥
* @param ttlMillis jwt过期时间(毫秒)
* @param claims 设置的信息
* @return
*/
public static String createJWT(String secretKey, long ttlMillis, Map<String, Object> claims) {
// 指定签名的时候使用的签名算法,也就是header那部分
SignatureAlgorithm signatureAlgorithm = SignatureAlgorithm.HS256;
// 生成JWT的时间
long expMillis = System.currentTimeMillis() + ttlMillis;
Date exp = new Date(expMillis);
// 设置jwt的body
JwtBuilder builder = Jwts.builder()
// 如果有私有声明,一定要先设置这个自己创建的私有的声明,这个是给builder的claim赋值,一旦写在标准的声明赋值之后,就是覆盖了那些标准的声明的
.setClaims(claims)
// 设置签名使用的签名算法和签名使用的秘钥
.signWith(signatureAlgorithm, secretKey.getBytes(StandardCharsets.UTF_8))
// 设置过期时间
.setExpiration(exp);
return builder.compact();
}
/**
* Token解密
*
* @param secretKey jwt秘钥 此秘钥一定要保留好在服务端, 不能暴露出去, 否则sign就可以被伪造, 如果对接多个客户端建议改造成多个
* @param token 加密后的token
* @return
*/
public static Claims parseJWT(String secretKey, String token) {
// 得到DefaultJwtParser
Claims claims = Jwts.parser()
// 设置签名的秘钥
.setSigningKey(secretKey.getBytes(StandardCharsets.UTF_8))
// 设置需要解析的jwt
.parseClaimsJws(token).getBody();
return claims;
}Nginx负载均衡和反向代理:
负载均衡:是指将请求分发到多个服务器上处理,以提高系统的可用性和响应速度。Nginx可以通过配置实现这一功能,它能够根据不同的算法(如轮询、最少连接、哈希等)智能地分配客户端请求至后端服务器集群。
1.基于轮询算法的负载均衡
基于轮询算法的负载均衡是指将客户端请求依次分配给不同的目标服务器,每个服务器处理相同数量的请求。这种负载均衡算法实现简单,但是对于服务器的负载分配不够均衡,可能会出现某个服务器负载过高的情况。
2.基于IP Hash算法的负载均衡
基于IP Hash算法的负载均衡是指将客户端请求根据IP地址的Hash值分配给不同的目标服务器,每个客户端请求都会被分配到同一个服务器上,从而保证相同客户端的请求都由同一台服务器处理。
3.基于Least Connections算法的负载均衡
基于Least Connections算法的负载均衡是指将客户端请求分配给当前连接数最少的目标服务器,从而保证服务器的负载分配更加均衡。
要想弄明白反向代理,首先要知道啥是正向代理。
正向代理:是一个位于客户端和目标服务器之间的代理服务器,为了从目标服务器取得内容,客户端向代理服务器发送一个请求并指定目标,软后代理服务器向目标服务器转交请求并获得内容返回给客户端。比如国内访问谷歌,直接访问是不行的,所以就要经过一个能够访问谷歌的正向代理服务器,由代理去获取数据并返回,而此时服务器是不知道我们客户端的任何信息的。
一句话总结:正向代理,就是代理服务器代理了客户端,去和目标服务器进行交互。
反向代理:与正向代理正好相反,反向代理中的代理服务器,代理的是服务器那端。代理服务器接收客户端请求,然后将请求转发给内部网络的服务器,并将从服务器上得到的结果返回给客户端。对于用户而言,反向代理服务器就相当于目标服务器,即用户直接访问反向代理服务器就可以获取到目标服务器的资源。同时,用户不需要知道目标服务器的地址也不会知道。
一句话总结:反向代理,就是代理服务器代理了目标服务器,去和客户端进行交互。
MD5加密登录:
如果我们的员工表中的密码是明文储存的话,安全性太低。所以我们提出了一种解决思路,就是将密码使用MD5加密方式对明文进行加密,来提高安全性。
MD5讯息摘要演算法(英语:MD5 Message-Digest Algorithm),一种被广泛使用的密码杂凑函数,可以产生出一个128位元(16位元组)的散列值(hash value),用于确保信息传输完整一致。不过需要注意的一点是,MD5算法它是不可逆的,也就是说无法从加密后的密文反过来得到原文。其原因是MD5使用的是hash算法,在计算过程中原文的部分信息是丢失的。
本项目实现MD5加密算法思路:
1.修改数据库中明文密码,改为MD5加密后的密文

2.修改Java代码,前端提交的密码进行MD5加密后再跟数据库中密码比对
/**
* 员工登录
*
* @param employeeLoginDTO
* @return
*/
public Employee login(EmployeeLoginDTO employeeLoginDTO) {
String username = employeeLoginDTO.getUsername();
String password = employeeLoginDTO.getPassword();
//1、根据用户名查询数据库中的数据
Employee employee = employeeMapper.getByUsername(username);
//2、处理各种异常情况(用户名不存在、密码不对、账号被锁定)
if (employee == null) {
//账号不存在
throw new AccountNotFoundException(MessageConstant.ACCOUNT_NOT_FOUND);
}
//密码比对
// 对前段传过来的明文密码进行md5加密处理
password = DigestUtils.md5DigestAsHex(password.getBytes());
if (!password.equals(employee.getPassword())) {
//密码错误
throw new PasswordErrorException(MessageConstant.PASSWORD_ERROR);
}
if (employee.getStatus() == StatusConstant.DISABLE) {
//账号被锁定
throw new AccountLockedException(MessageConstant.ACCOUNT_LOCKED);
}
//3、返回实体对象
return employee;
}ThreadLocal:
ThreadLocal其实是一个线程本地变量。ThreadLocal为每一个线程提供了一个单独的存储空间。如果你创建了一个ThreadLocal变量,那么访问这个变量的每个线程都会创建一个这个变量的拷贝副本在本地,多个线程操作这个变量时,实际是操作自己本地内存的变量,从而起到线程隔离的作用,避免了并发场景下的线程安全问题。
如何使用ThreadLocal:
1.定义一个TreadLocal对象,并通过ThreadLocal.withInitial()来初始化对象。
2.创建线程,来分别调用ThreadLocal对象的set()和get()方法来设置值和获取值。
3.清楚变量值,通过ThreadLocal对象的remove()方法来清楚当前线程的变量副本。
public class ThreadLocalExample {
// 定义一个 ThreadLocal 变量
private static ThreadLocal<Integer> threadLocalValue = ThreadLocal.withInitial(() -> 0);
public static void main(String[] args) {
// 创建两个线程
Thread threadA = new Thread(() -> {
threadLocalValue.set(100); // 设置值
System.out.println("Thread A: " + threadLocalValue.get()); // 获取值
threadLocalValue.remove(); // 清除值
});
Thread threadB = new Thread(() -> {
threadLocalValue.set(200); // 设置值
System.out.println("Thread B: " + threadLocalValue.get()); // 获取值
threadLocalValue.remove(); // 清除值
});
// 启动线程
threadA.start();
threadB.start();
}
}在本项目中,通过ThreadLocal实现了如果要表面谁的员工进行了新增和修改,那么就要解析此时登录者的token,把token传入到当前线程的局部变量当中。(我们把Thread的所有方法都封装到context了包中,放在了BaseContext类下)
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
//判断当前拦截到的是Controller的方法还是其他资源
if (!(handler instanceof HandlerMethod)) {
//当前拦截到的不是动态方法,直接放行
return true;
}
//1、从请求头中获取令牌
String token = request.getHeader(jwtProperties.getUserTokenName());
//2、校验令牌
try {
log.info("jwt校验:{}", token);
Claims claims = JwtUtil.parseJWT(jwtProperties.getUserSecretKey(), token);
Long userId = Long.valueOf(claims.get(JwtClaimsConstant.USER_ID).toString());
log.info("当前员工id:", userId);
//通过ThreadLocal来存储empId,使得它在同一个线程的其他包中可以使用
BaseContext.setCurrentId(userId);
//3、通过,放行
return true;
} catch (Exception ex) {
//4、不通过,响应401状态码
response.setStatus(401);
return false;
}
}使用时就调用BaseContext类的接口 (后面因为这段代码在项目中重复写了很多,所有使用了填充字段的方法进行统一的处理)

消息转化器对日期进行格式化处理
当我们前端传来的日期内容格式不定时,如果在日期属性较少的情况下,我们可以直接在日期属性前加上注解进行格式化处理。
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss")
private LocalDateTime createTime;
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss")
private LocalDateTime updateTime;如果在日期属性较多的情况下,我们就可以利用消息转换器统一的对日期进行格式化处理。
首先我们要知道ObjectMapper是Jackson库中的一个类,他的主要作用就是:
1.将java对象序列化为JSON/XML格式(响应)
2.将JSON/XML数据反序列化为java对象(请求)
所有来说我们可以通过两部来实现自定义一个消息转换器:
- 1. 在构造器中自定义日期的转换格式,也就是说改变了日期属性的初始值
- 2. 通过配置SpringMVC让其在调用时,不要调用Jackson自定义的ObjecMapper而是调用我们自定义的格式。
下面就是本项目的具体实现过程:
1. 集成ObjectMapper,重写构造方法,自定义序列化方式
package com.sky.json;
import com.fasterxml.jackson.databind.DeserializationFeature;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.module.SimpleModule;
import com.fasterxml.jackson.datatype.jsr310.deser.LocalDateDeserializer;
import com.fasterxml.jackson.datatype.jsr310.deser.LocalDateTimeDeserializer;
import com.fasterxml.jackson.datatype.jsr310.deser.LocalTimeDeserializer;
import com.fasterxml.jackson.datatype.jsr310.ser.LocalDateSerializer;
import com.fasterxml.jackson.datatype.jsr310.ser.LocalDateTimeSerializer;
import com.fasterxml.jackson.datatype.jsr310.ser.LocalTimeSerializer;
import java.time.LocalDate;
import java.time.LocalDateTime;
import java.time.LocalTime;
import java.time.format.DateTimeFormatter;
import static com.fasterxml.jackson.databind.DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES;
/**
* 对象映射器:基于jackson将Java对象转为json,或者将json转为Java对象
* 将JSON解析为Java对象的过程称为 [从JSON反序列化Java对象]
* 从Java对象生成JSON的过程称为 [序列化Java对象到JSON]
*/
public class JacksonObjectMapper extends ObjectMapper {
public static final String DEFAULT_DATE_FORMAT = "yyyy-MM-dd";
//public static final String DEFAULT_DATE_TIME_FORMAT = "yyyy-MM-dd HH:mm:ss";
public static final String DEFAULT_DATE_TIME_FORMAT = "yyyy-MM-dd HH:mm";
public static final String DEFAULT_TIME_FORMAT = "HH:mm:ss";
public JacksonObjectMapper() {
super();
//收到未知属性时不报异常
this.configure(FAIL_ON_UNKNOWN_PROPERTIES, false);
//反序列化时,属性不存在的兼容处理
this.getDeserializationConfig().withoutFeatures(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES);
SimpleModule simpleModule = new SimpleModule()
.addDeserializer(LocalDateTime.class, new LocalDateTimeDeserializer(DateTimeFormatter.ofPattern(DEFAULT_DATE_TIME_FORMAT)))
.addDeserializer(LocalDate.class, new LocalDateDeserializer(DateTimeFormatter.ofPattern(DEFAULT_DATE_FORMAT)))
.addDeserializer(LocalTime.class, new LocalTimeDeserializer(DateTimeFormatter.ofPattern(DEFAULT_TIME_FORMAT)))
.addSerializer(LocalDateTime.class, new LocalDateTimeSerializer(DateTimeFormatter.ofPattern(DEFAULT_DATE_TIME_FORMAT)))
.addSerializer(LocalDate.class, new LocalDateSerializer(DateTimeFormatter.ofPattern(DEFAULT_DATE_FORMAT)))
.addSerializer(LocalTime.class, new LocalTimeSerializer(DateTimeFormatter.ofPattern(DEFAULT_TIME_FORMAT)));
//注册功能模块 例如,可以添加自定义序列化器和反序列化器
this.registerModule(simpleModule);
}
}2. 让Spring使用我们自定义的消息转换器
在本项目中的WebMvcConfigurationSupport中配置我们的消息转换器。(这个类中还有我们常用的拦截器的配置规则,资源处理的配置规则等等。通过在这个类中配置相关信息,即可改变Spring默认指定的规则为我们自己定义的规则)
/**
* 扩展SpringMVC框架的消息转换器
*/
@Override
protected void extendMessageConverters(List<HttpMessageConverter<?>> converters) {
log.info("扩展消息转换器。。。");
//创建一个消息转换器
MappingJackson2HttpMessageConverter converter = new
MappingJackson2HttpMessageConverter();
//需要为消息转换器设置一个对象转换器,对象转换器可以将java对象序列化为json数据
converter.setObjectMapper(new JacksonObjectMapper());
//将自己的消息转换器加入converters容器中
converters.add(0,converter); // 0:把它放到容器的第一个
}核心就是创建了一个MappingJackson2HttpMessageConverter的实例。他是Spring提共的一个消息转换器,专门处理JSON格式的数据。其次,为我们的消息转换器指定使用我们自定义的序列化方式。然后把他加入到消息转换容器的第一个位置去使用。
PageHelper分页查询:
PageHelper是基于Mybatis提供的第三方分页插件,其底层是基于Mybatis拦截器和动态SQL来实现的。首先Mybatis拦截器会拦截SQL的执行过程,并且在其执行前对其改写,动态SQL会在原始的SQL的基础上添加分页查询的逻辑,大大减少了分页查询的操作。
在本项目中,首先我们要引入maven依赖:
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
</dependency>在Controller层:
EmployeePageQueryDTO里封装的就是分页的参数:page页码;pageSize每页显示的记录数
而pageResult返回的是:total总记录数;recors当前页数所展示的数据集合
/**
* 分页查询
*/
@GetMapping("/page")
public Result<PageResult> page(EmployeePageQueryDTO employeePageQueryDTO) {
log.info("分页查询参数为:{}",employeePageQueryDTO);
PageResult pageResult = employeeService.pageQuery(employeePageQueryDTO);
return Result.success(pageResult);
}在Service实现类中:
调用PageHelper中的startPage来设置分页参数
/**
* 分页查询
* @return
*/
@Override
public PageResult pageQuery(EmployeePageQueryDTO employeePageQueryDTO) {
PageHelper.startPage(employeePageQueryDTO.getPage(), employeePageQueryDTO.getPageSize());
//PageHelper要求我们返回一个Page对象,泛型就为employee实体类
Page<Employee> page = employeeMapper.pageQuery(employeePageQueryDTO);
long total = page.getTotal();
List<Employee> result = page.getResult();
return new PageResult(total,result);
}Mapper层:
动态查询
<select id="pageQuery" resultType="com.sky.entity.Employee">
select * from employee
<where>
<if test="name != null and name != ''">
and name like concat('%',#{name},'%')
</if>
</where>
order by create_time desc
</select>
基于注解和AOP的公共字段填充 :
在我们开发项目时,会牵扯到大量的数据表,而这些数据表会有很多重复的字段,并且当我们对这些重复的字段进行操作时,大量的重复操作会造成代码冗余。例如在苍穹外卖项目中,在对数据进行Update和Insert时,都会对修改人/时间和创建人/时间这四个字段进行更新,这就会使项目中出现了大量相似的代码。
所以我们通过AOP思想(面向切面编程)来优化这种冗余。
AOP的思想:他可以将那些被业务模块所共同调用的逻辑分装起来,便于减少系统之间重复的代码。
在本项目中,我们会先通过注解的方式标记到我们需要的方法,然后利用AOP的思想创建一个切面,在切面中实现对我们进行注解的方法编写我们所需要的业务功能,比如字段的填充,然后再运行原方法。
1.首先我们设置一个自定义的注解,来表示要进行公共字段字段填充的方法。
@Target(ElementType.METHOD) //表示该注解只能在方法上使用
@Retention(RetentionPolicy.RUNTIME) //表示该注解的生命周期,在启动时使用
public @interface AutoFill {
//申明数据库操作类型:update ,insert
OperationType value();
}2. 在我们自定义的注解里面有一个枚举类型的方法,用来枚举数据库的两种类型操作。
/**
* 数据库操作类型
*/
public enum OperationType {
/**
* 更新操作
*/
UPDATE,
/**
* 插入操作
*/
INSERT
}3.自定义切面类,统一拦截加入AutoFill注解的方法,并通过反射为公共字段赋值。
package com.sky.aspect;
import com.sky.annotation.AutoFill;
import com.sky.constant.AutoFillConstant;
import com.sky.context.BaseContext;
import com.sky.enumeration.OperationType;
import lombok.extern.slf4j.Slf4j;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.Signature;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.aspectj.lang.annotation.Pointcut;
import org.aspectj.lang.reflect.MethodSignature;
import org.springframework.stereotype.Component;
import java.lang.annotation.Annotation;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
import java.time.LocalDateTime;
/**
* 自定义切面,实现公共字段自动填充处理逻辑
*/
@Aspect
@Component //也要交个Spring容器管理
@Slf4j
public class AutoFillAspect {
/**
* 切入点
*/
@Pointcut("execution(* com.sky.mapper.*.*(..)) && @annotation(com.sky.annotation.AutoFill)")
public void autoFillPointCut(){}
/**
* 前置通知:在通知中进行公共字段的赋值
*/
@Before("autoFillPointCut()")
public void autoFill(JoinPoint joinPoint) throws NoSuchMethodException, InvocationTargetException, IllegalAccessException {
log.info("开始进行公共字段自动填充");
//获取到当前被拦截(切入点) 的数据库操作类型
MethodSignature signature = (MethodSignature)joinPoint.getSignature(); //获得方法签名对象(更详细)
AutoFill autoFill = signature.getMethod().getAnnotation(AutoFill.class);//获取方法上的注解对象
OperationType operationType = autoFill.value(); //获取数据库的操作类型
//获取到当前被拦截方法的方法参数--实体对象
Object[] args = joinPoint.getArgs();
if(args == null || args.length == 0) {
return;
}
Object entity = args[0];
//准备赋值的数据
LocalDateTime now = LocalDateTime.now();
Long currentId = BaseContext.getCurrentId();
//根据不同的操作类型,为对应的属性通过反射来赋值
if (operationType == OperationType.INSERT) {
//尝试从该类中查找名为 setCreateTime 的方法。
//确保该方法的参数列表与指定的参数类型(这里是 LocalDateTime.class)匹配。
Method setCreateTime = entity.getClass().getDeclaredMethod(AutoFillConstant.SET_CREATE_TIME, LocalDateTime.class);
Method setCreateUser = entity.getClass().getDeclaredMethod(AutoFillConstant.SET_CREATE_USER, Long.class);
Method setUpdateTime = entity.getClass().getDeclaredMethod(AutoFillConstant.SET_UPDATE_TIME, LocalDateTime.class);
Method setUpdateUser = entity.getClass().getDeclaredMethod(AutoFillConstant.SET_UPDATE_USER, Long.class);
//通过反射为对象属性赋值
setCreateTime.invoke(entity,now);//invoke:动态调用 entity 对象的 setCreateTime 方法,将当前时间(now)作为参数传入。
setCreateUser.invoke(entity,currentId);
setUpdateTime.invoke(entity,now);
setUpdateUser.invoke(entity,currentId);
}else if(operationType == OperationType.UPDATE) {
Method setUpdateTime = entity.getClass().getDeclaredMethod(AutoFillConstant.SET_UPDATE_TIME, LocalDateTime.class);
Method setUpdateUser = entity.getClass().getDeclaredMethod(AutoFillConstant.SET_UPDATE_USER, Long.class);
//通过反射为对象属性赋值
setUpdateTime.invoke(entity,now);
setUpdateUser.invoke(entity,currentId);
}
}
}4.在Mapper中的所需方法加入AutoFill注解
/**
* 动态更新员工信息
* @param e
*/
@AutoFill(value = OperationType.UPDATE)
void update(Employee e);并且还了解到了在声明自定义注解里的Target和Retention注解

Target:是一个元注解,用于指定自定义注解可以应用的目标元素类型。
ElementType 是一个枚举类,常见的取值及其含义如下:
- ElementType.TYPE:可以应用于类、接口或枚举(即类型声明上)。
- ElementType.FIELD:可以应用于字段(包括枚举常量)。
- ElementType.METHOD:可以应用于方法。
- ElementType.PARAMETER:可以应用于方法参数。
- ElementType.CONSTRUCTOR:可以应用于构造方法。
- ElementType.LOCAL_VARIABLE:可以应用于局部变量。
- ElementType.ANNOTATION_TYPE:可以应用于其他注解。
- ElementType.PACKAGE:可以应用于包声明。
Retention:是一个元注解,用于指定自定义注解的生命周期。(即注解在什么时候用)
RetentionPolicy 是一个枚举类,常见的取值及其含义如下:
- RetentionPolicy.SOURCE:注解只在源码中保留,编译后会被丢弃(如 @Override)。
- RetentionPolicy.CLASS:注解在编译后的 .class 文件中保留,但运行时不可用(默认值)。
- RetentionPolicy.RUNTIME:注解在运行时保留,可以通过反射机制访问。
阿里云OSS云存储服务:
阿里云对象存储OSS(Object Storage Service)是一款海量、安全、低成本、高可靠的云存储服务。我们可以使用阿里云提供的API、SDK包或者OSS迁移工具轻松地将海量数据移入或移出阿里云OSS。在苍穹外卖这个项目中,我们主要利用阿里云OSS来存储我们菜品与套餐的图片,并且进行回显。
这个地方的代码大部分都是固定的,所以不用死记硬背。
1.首先我们创建一个AliOssUtil工具类,这个工具类实现了文件上传功能。
package com.sky.utils;
import com.aliyun.oss.ClientException;
import com.aliyun.oss.OSS;
import com.aliyun.oss.OSSClientBuilder;
import com.aliyun.oss.OSSException;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.extern.slf4j.Slf4j;
import java.io.ByteArrayInputStream;
@Data
@AllArgsConstructor
@Slf4j
public class AliOssUtil {
private String endpoint;
private String accessKeyId;
private String accessKeySecret;
private String bucketName;
/**
* 文件上传
*
* @param bytes
* @param objectName
* @return
*/
public String upload(byte[] bytes, String objectName) {
// 创建OSSClient实例。
OSS ossClient = new OSSClientBuilder().build(endpoint, accessKeyId, accessKeySecret);
try {
// 创建PutObject请求。
ossClient.putObject(bucketName, objectName, new ByteArrayInputStream(bytes));
} catch (OSSException oe) {
System.out.println("Caught an OSSException, which means your request made it to OSS, "
+ "but was rejected with an error response for some reason.");
System.out.println("Error Message:" + oe.getErrorMessage());
System.out.println("Error Code:" + oe.getErrorCode());
System.out.println("Request ID:" + oe.getRequestId());
System.out.println("Host ID:" + oe.getHostId());
} catch (ClientException ce) {
System.out.println("Caught an ClientException, which means the client encountered "
+ "a serious internal problem while trying to communicate with OSS, "
+ "such as not being able to access the network.");
System.out.println("Error Message:" + ce.getMessage());
} finally {
if (ossClient != null) {
ossClient.shutdown();
}
}
//文件访问路径规则 https://BucketName.Endpoint/ObjectName
StringBuilder stringBuilder = new StringBuilder("https://");
stringBuilder
.append(bucketName)
.append(".")
.append(endpoint)
.append("/")
.append(objectName);
log.info("文件上传到:{}", stringBuilder.toString());
return stringBuilder.toString();
}
}2. 通过OssConfiguration配置类创建这个AliOssUtil工具类的对象:
通过springboot的自动配置把AliOssUtil添加到IOC容器中。
package com.sky.config;
import com.sky.properties.AliOssProperties;
import com.sky.utils.AliOssUtil;
import lombok.extern.slf4j.Slf4j;
import org.springframework.boot.autoconfigure.condition.ConditionalOnMissingBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* 配置类,用于创建AliOSSUtil对象
*/
@Configuration
@Slf4j
public class OssConfiguration {
@Bean //把AliOSSUtil加入了Spring容器
@ConditionalOnMissingBean //保证Spring容器里只有一个工具类
public AliOssUtil aliOssUtil(AliOssProperties aliOssProperties) {
log.info("开始创建阿里云文件上传工具类对象:{}",aliOssProperties);
return new AliOssUtil(aliOssProperties.getEndpoint(),
aliOssProperties.getAccessKeyId(),
aliOssProperties.getAccessKeySecret(),
aliOssProperties.getBucketName());
}
}3.通过配置文件中的写好的值用@ConfigurationProperties注解封装到AliOssProperties对象
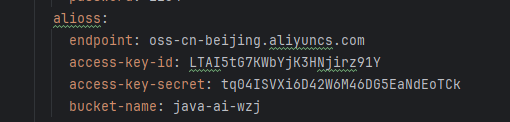
package com.sky.properties;
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;
@Component
@ConfigurationProperties(prefix = "sky.alioss")
@Data
public class AliOssProperties {
private String endpoint;
private String accessKeyId;
private String accessKeySecret;
private String bucketName;
}4.在Controller层调用AliOssutil这个Bean对象
这里里了了UUID随机生成了文件名,来保证我们上传的新照片不会覆盖之前的照片。
package com.sky.controller.admin;
import com.sky.result.Result;
import com.sky.utils.AliOssUtil;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.multipart.MultipartFile;
import java.io.IOException;
import java.util.UUID;
@RestController
@RequestMapping("/admin/common")
@Slf4j
public class CommonController {
@Autowired
AliOssUtil aliOssUtil;
@PostMapping("/upload")
public Result<String> upload(MultipartFile file) throws IOException {
log.info("文件上传:{}",file);
//原始文件名
String originalFilename = file.getOriginalFilename();
//原始文件的后缀名
String extension = originalFilename.substring(originalFilename.lastIndexOf('.'));
//随机构造一个新的文件名
String path = UUID.randomUUID() + extension;
//文件的请求路径
String filePath = aliOssUtil.upload(file.getBytes(), path);
return Result.success(filePath);
}
}在完成了阿里云OSS云存储服务后,我还学习到了,在我们的项目开发时,尽量保持代码的灵活性,不要把代码写死。这样首先可以帮助我们区分环境配置,application.yml时应用程序的配置文件,包含了一些通用的默认的配置信息,这些配置在各个环境中都会用到。而application-dev.yml时专门为开发环境准备的配置文件,他可以包含一些与开发环境相关的特定配置,比如开发环境使用的数据库连接参数、日志级别等。这样就可以使开发人员在开发过程中对application-dev.yml进行灵活的配置,而不会影响到其他环境配置。
并且将不同环境的配置分离到不同的文件中,使得配置更加清晰、易于管理。当项目需要部署到不同的环境,如测试环境、生产环境等时,可以通过修改相应的环境配置文件来快速切换配置,而无需在一个庞大的配置文件中进行繁琐的修改和注释操作。
- application.yml
server:
port: 8080
spring:
profiles:
active: dev
main:
allow-circular-references: true
datasource:
druid:
driver-class-name: ${sky.datasource.driver-class-name}
url: jdbc:mysql://${sky.datasource.host}:${sky.datasource.port}/${sky.datasource.database}?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&useSSL=false&allowPublicKeyRetrieval=true
username: ${sky.datasource.username}
password: ${sky.datasource.password}
redis:
host: ${sky.redis.host}
port: ${sky.redis.port}
password: ${sky.redis.password}
database: ${sky.redis.database}
mybatis:
#mapper配置文件
mapper-locations: classpath:mapper/*.xml
type-aliases-package: com.sky.entity
configuration:
#开启驼峰命名
map-underscore-to-camel-case: true
logging:
level:
com:
sky:
mapper: debug
service: info
controller: info
sky:
jwt:
# 设置jwt签名加密时使用的秘钥
admin-secret-key: itcast
# 设置jwt过期时间
admin-ttl: 720000000
# 设置前端传递过来的令牌名称
admin-token-name: token
user-secret-key: itheima
user-ttl: 720000000
user-token-name: authentication
alioss:
endpoint: ${sky.alioss.endpoint}
access-key-id: ${sky.alioss.access-key-id}
access-key-secret: ${sky.alioss.access-key-secret}
bucket-name: ${sky.alioss.bucket-name}
wechat:
appid: ${sky.wechat.appid}
secret: ${sky.wechat.secret}
mchid: ${sky.wechat.mchid}
mchSerialNo: ${sky.wechat.mchSerialNo}
privateKeyFilePath: ${sky.wechat.privateKeyFilePath}
apiV3Key: ${sky.wechat.apiV3Key}
weChatPayCertFilePath: ${sky.wechat.weChatPayCertFilePath}
notifyUrl: ${sky.wechat.notifyUrl}
refundNotifyUrl: ${sky.wechat.refundNotifyUrl}- application-dev.yml
sky:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
host: localhost
port: 3306
database: sky_take_out
username: root
password: 1234
alioss:
endpoint: oss-cn-beijing.aliyuncs.com
access-key-id: LTAI5tG7KWbYjK3HNjirz91Y
access-key-secret: tq04ISVXi6D42W6M46DG5EaNdEoTCk
bucket-name: java-ai-wzj
redis:
host: localhost
port: 6379
password: 123456
database: 10
wechat:
appid: wxb894315cba1d289f
secret: 5158696d9ff0bab698cf5018ef04e63b
mchid: 1561414331
mchSerialNo: 4B3B3DC35414AD50B1B755BAF8DE9CC7CF407606
privateKeyFilePath: D:\apiclient_key.pem
apiV3Key: CZBK51236435wxpay435434323FFDuv3
weChatPayCertFilePath: D:\wechatpay_166D96F876F45C7D07CE98952A96EC980368ACFC.pem
notifyUrl: http://68c9dda7.r3.cpolar.top
refundNotifyUrl: http://68c9dda7.r3.cpolar.top事务操作:
如果当一个业务操作涉及到对多个表进行插入、更新或者删除操作时,我们要保证数据的一致性,需要开启事务。如果其中某个操作失败,整个业务操作都要回滚,以避免数据出现不一致的情况。
比如说在我们苍穹外卖的项目中,在对当前菜品进行删除时,若该菜品会被删除,则首先设计菜品表的删除操作,其次还会设计到口味表的删除操作。这个时候如果不加事务注解,可能会使得菜品表的数据被删除但口味表的数据没被删除,造成了数据不一致的情况。
为了避免上种情况,所以要添加事务,来保证一些业务逻辑的一系列操作要不都成功,要么都失败。
1.首先在启动类上加入@EnableTransactionManagement来开启事务注解
package com.sky;
import lombok.extern.slf4j.Slf4j;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.scheduling.annotation.EnableScheduling;
import org.springframework.transaction.annotation.EnableTransactionManagement;
@SpringBootApplication
@EnableTransactionManagement //开启注解方式的事务管理
@Slf4j
@EnableCaching
@EnableScheduling
public class SkyApplication {
public static void main(String[] args) {
SpringApplication.run(SkyApplication.class, args);
log.info("server started");
}
}
2.在对应的方法上加入@Transactional注解
@Override
@Transactional//设计多个表的操作,加事务注解
public void deleteById(List<Long> ids) {
//若当前菜品起售中,则不能删除
for (Long id : ids) {
Dish dish = dishMapper.getById(id);
Integer status = dish.getStatus();
if (status == StatusConstant.ENABLE) {
throw new DeletionNotAllowedException(MessageConstant.DISH_ON_SALE);
}
}
//若当前菜品被套餐关联,则不能删除(这次用批量查询的方法)
List<Long> setmealIds = setmealDishMapper.getSetmealIdByDishIds(ids);
if (setmealIds != null && setmealIds.size() > 0) {
throw new DeletionNotAllowedException(MessageConstant.DISH_BE_RELATED_BY_SETMEAL);
}
//批量删除菜品表中的菜品数据(优化)
dishMapper.deleteByIds(ids);
//批量删除关联的口味数据(优化)
dishFlavorMapper.deleteByIds(ids);这样使这个方法中的菜品表和口味表捆包成了一个事务。
Redis:
Redis(Remote Dictionary Server)中文叫远程词典服务器,是一个基于内存的键值型NoSQL数据库。
- 键值(key-value)型,value支持多种不同的数据结构,功能丰富
- 单线程,每个命令具备原子性
在Redis早期使用的是多线程,而在Redis6.0使用了多线程。是因为用多线程来处理数据的读写和协议解析,但是Redis执行命令还是单线程。
- 低延迟,速度快(基于内存、IO多路复用、良好的编码)
之所以说Redis速度快,主要是因为它完全基于内存操作。单机的Redis就可以支撑每秒十几万的开发,相对于MySQL来说,性能是MySQL的几十倍。
- 支持数据持久化
- 支持主从集群、分片集群
主从集群的意思就是说 从节点可以主备主节点的数据,若主节点宕机,数据也会从从节点上找到,并且还能提高IO的效率。分片集群就是把数据进行了拆分,比如把这些数据拆分为了n份,存在不同的节点上去,然后用很多机器一起存,增加了存储的上限。
- 支持多语言客户端
Redis还支持多种数据结构,比如字符串、列表、哈希表、集合和有序集合以及他们的各种操作。
在我们的项目中之所以引入Redis这个技术的地方就是查询店铺的营业状态,因为在查询店铺的营业状态属于一个频繁查询和更新的操作,使用Redis可以确保在高平发的场景下,能够快速地获取和修改店铺的营业状态。并且店铺的营业状态一般只有两种:营业或打样。所以利用Redis的缓存机制,可以将店铺营业状态信息缓存到内存中,减少了频繁访问后端数据库,减轻了数据库的压力。
具体来说:
1.导入Spring Data Redis的依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>2.配置Redis的 配置文件
redis:
host: localhost
port: 6379
password: 123456
database: 103. 编写RedisConfiguration的配置类来创建redisTemplate对象
因为SpringBoot提供的自动配置会创建一个默认的RedisTemplate对象,但它的序列化可能一般不符合要求。所以我们要自定义序列化方式,通过设置StringRedisSerializer作为key的序列化器,确保Redis中的key读取的是可读的字符串。
@Configuration
@Slf4j
public class RedisConfiguration {
//创建redisTemplate对象
@Bean
public RedisTemplate redisTemplate(RedisConnectionFactory redisConnectionFactory) {
log.info("开始创建redis模板对象");
RedisTemplate redisTemplate = new RedisTemplate();
//设置redis的连接工厂对象
redisTemplate.setConnectionFactory(redisConnectionFactory);
//设置redis key的序列化对象(防止出现乱码)
redisTemplate.setKeySerializer(new StringRedisSerializer());
return redisTemplate;
}
}4.通过调用RedisTemplate对象来在Java中操作Redis,实现店铺营业状态的设置
@RestController("adminShopController") //区分相同类名的bean对象
@RequestMapping("/admin/shop")
@Slf4j
public class shopController {
@Autowired
private RedisTemplate redisTemplate;
public static final String key = "SHOP_STATUS";
/**
* 设置店铺的营业状态
* @param status
* @return
*/
@PutMapping("/{status}")
public Result setStatus(@PathVariable Integer status) {
log.info("设置店铺的营业状态为:{}",status == 1 ? "营业中" : "打样中");
redisTemplate.opsForValue().set(key,status);
return Result.success();
}
/**
* 获取店铺营业状态
* @return
*/
@GetMapping("/status")
public Result<Integer> getStatus() {
Integer status = (Integer) redisTemplate.opsForValue().get(key);
log.info("获取店铺状态:{}",status == 1 ? "营业中" : "打样中");
return Result.success(status);
}
}并且在后面的用户端小程序展示的菜品数据都是通过查询数据库获得的,如果用户端访问量比较大,数据库的访问压力随之增大。就会导致用户在访问时系统响应慢,用户体验差。所以我们也可以用缓存的方法来解决这类问题。
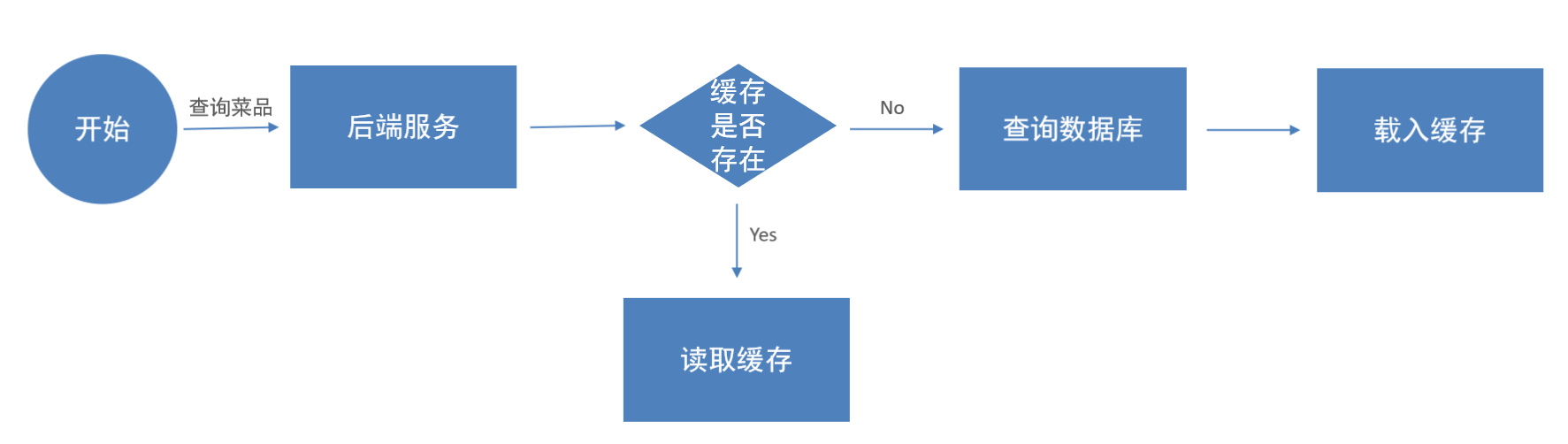
因此为了提高我们的用户效率,我们采用这样一种思想:建立一块缓存区,在用户查询对应数据的时候,先看看缓存区有没有,如果缓存区有,直接发送缓存区中的数据,如果缓存区没有,再查询数据库,并且把查询到的数据同时存到缓冲区中,便捷下次查询的效率。
而我们建立缓存区的方法是使用Redis数据库,在前面我们就介绍过Redis,他是一个存储在内存中的键值类型的数据库,这大大优化了查询效率。
代码开发
修改用户端接口 DishController 的 list 方法,加入缓存处理逻辑:
@Autowired
private RedisTemplate redisTemplate;
/**
* 根据分类id查询菜品
*
* @param categoryId
* @return
*/
@GetMapping("/list")
@ApiOperation("根据分类id查询菜品")
public Result<List<DishVO>> list(Long categoryId) {
//构造redis中的key,规则:dish_分类id
String key = "dish_" + categoryId;
//查询redis中是否存在菜品数据
List<DishVO> list = (List<DishVO>) redisTemplate.opsForValue().get(key);
if(list != null && list.size() > 0){
//如果存在,直接返回,无须查询数据库
return Result.success(list);
}
Dish dish = new Dish();
dish.setCategoryId(categoryId);
dish.setStatus(StatusConstant.ENABLE);//查询起售中的菜品
//如果不存在,查询数据库,将查询到的数据放入redis中
list = dishService.listWithFlavor(dish);
redisTemplate.opsForValue().set(key, list);
return Result.success(list);
}Httpclient:
在我们平常访问服务器里面的资源的时候,我们通常是通过浏览器输入网址来访问前端页面,在通过前端发出的某个请求去访问我们的后端服务器。但是有一种情况就是,可能某些的请求需要我们服务器端去发送,来获取一些资源或者服务。比较项目的功能是有限的,人的精力也是有限的,如果我们在开发后端的场合下,可以借助第三方的API来服务我们的项目,降低开发难度,何乐而不为呢。
所有HttpClient就实现了这样的功能,通过让服务器去发送请求,获取外部或者第三方的资源和服务。比如项目中调用微信登录的接口。
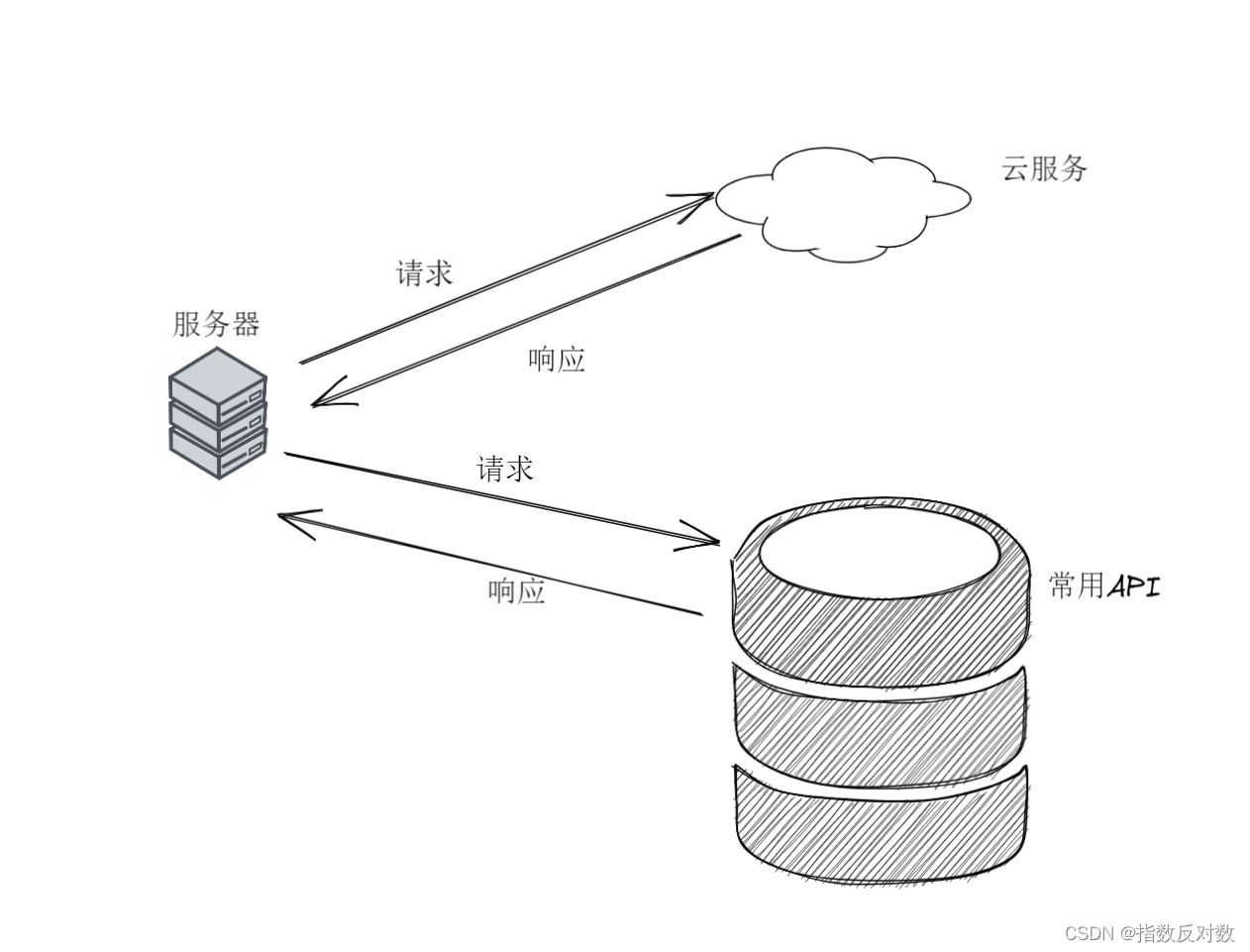
具体使用情况如下:
1.导入Maven坐标
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.13</version>
</dependency>2.获取到HttpClient对象
3.根据业务方法,获取响应的请求方式。如Get、Post和Put等。
4.设置路径或者请求参数。
5.处理返回对象。
6.关闭资源。
比如:
@Test
void testGet() throws IOException {
//获取HttpClient对象
CloseableHttpClient httpClient = HttpClients.createDefault();
//创建请求对象
String url = "http://localhost:8080/user/shop/status";
HttpGet httpGet = new HttpGet(url);
//发送请求,接受返回结果
CloseableHttpResponse response = httpClient.execute(httpGet);
//----处理返回结果
//获取服务端返回的状态码
int statusCode = response.getStatusLine().getStatusCode();
System.out.println("服务端返回的状态码为:"+statusCode);
//获取服务端返回的数据
HttpEntity entity = response.getEntity();
//对HttpEntity对象进行解析(字符串)
String body = EntityUtils.toString(entity);
System.out.println(body);
//关闭资源
response.close();
httpClient.close();
}
微信登陆:
微信登录的功能基本是一个固定的方式实现的。下面是微信登录的流程图:
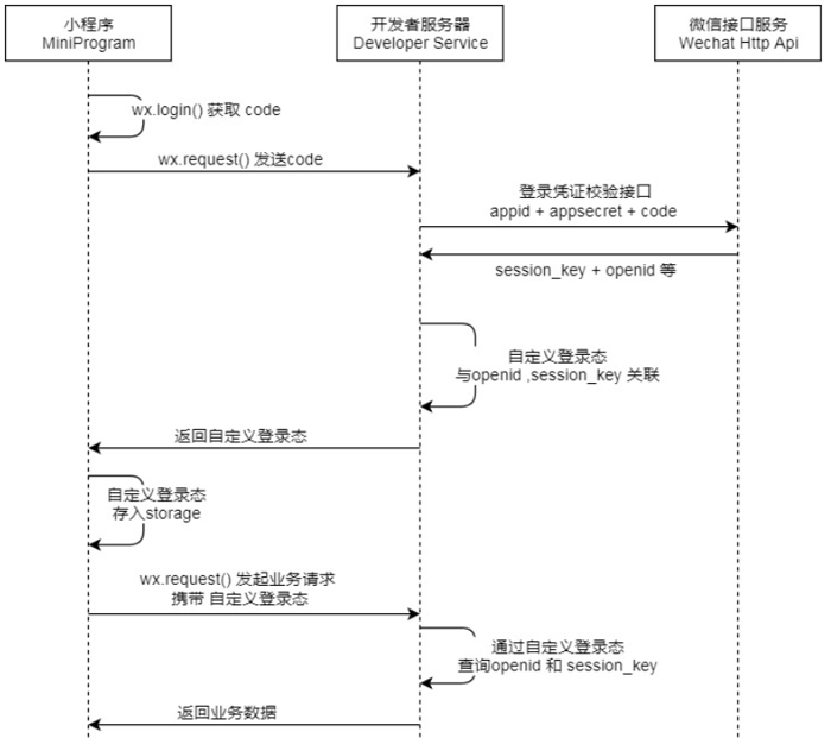
具体的执行步骤可以分为:
- 小程序端,调用wx.login()获取code,就是授权码。
- 小程序端,调用wx.request()发送请求并携带code,请求开发者服务器(自己编写的后端服务)。
- 开发者服务端,通过HttpClient向微信接口服务发送请求,并携带appId+appsecret+code三个参数。
- 开发者服务端,接收微信接口服务返回的数据,session_key+opendId等。opendId是微信用户的唯一标识。
- 开发者服务端,自定义登录态,生成令牌(token)和openid等数据返回给小程序端,方便后绪请求身份校验。
- 小程序端,收到自定义登录态,存储storage。
- 小程序端,后绪通过wx.request()发起业务请求时,携带token。
- 开发者服务端,收到请求后,通过携带的token,解析当前登录用户的id。
- 开发者服务端,身份校验通过后,继续相关的业务逻辑处理,最终返回业务数据。
通过微信登录的流程,如果要完成微信登录的话,最终就要获得微信用户的openid。在小程序端获取授权码后,向后端服务发送请求,并携带授权码,这样后端服务在收到授权码后,就可以去请求微信接口服务。最终,后端向小程序返回openid和token等数据。
除此之外,我们也需要一个拦截器把未登录时候的一切请求进行拦截(查询餐厅状态和登录请求除外)
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
//判断当前拦截到的是Controller的方法还是其他资源
if (!(handler instanceof HandlerMethod)) {
//当前拦截到的不是动态方法,直接放行
return true;
}
//1、从请求头中获取令牌
String token = request.getHeader(jwtProperties.getAdminTokenName());
//2、校验令牌
try {
log.info("jwt校验:{}", token);
Claims claims = JwtUtil.parseJWT(jwtProperties.getAdminSecretKey(), token);
Long empId = Long.valueOf(claims.get(JwtClaimsConstant.EMP_ID).toString());
log.info("当前员工id:", empId);
//通过ThreadLocal来存储empId,使得它在同一个线程的其他包中可以使用
BaseContext.setCurrentId(empId);
//3、通过,放行
return true;
} catch (Exception ex) {
//4、不通过,响应401状态码
response.setStatus(401);
return false;
}
}拦截器的思想就是校验下发的token令牌,如果令牌无法被解析或者没有令牌,说明当前用户处于未登陆状态,就不可以访问未开放的网络请求。
最后我们还需要在配置类中注册拦截器。
registry.addInterceptor(jwtTokenUserInterceptor)
.addPathPatterns("/user/**")
.excludePathPatterns("/user/user/login")
.excludePathPatterns("/user/shop/status");内网穿透:
首先内网穿透的原理就是,一般在局域网中的设备使用私有的IP地址,这些地址在局域网内部是唯一的,但在互联网是不可以路由的。内网穿透的工作原理是在局域网内的设备与具有公网IP地址的服务器之间建立一条通道。
列如在外卖项目中的微信支付功能,在微信支付后,微信这个第三方的服务器需要回调苍穹外面接口通知支付结果。但是本地开发环境没有公网IP,无法接受回调。所以使用内网穿透将本地服务器暴露到公网,配置第三方支付平台回调的URL为穿透后的公网地址,确保支付结构能正确的通知到本地服务。
Spring Task:
在我们日常项目开发中我们经常要使用定时任务。比如在凌晨进行统计计算,查询信息等。这时候如果我们人工的执行这些操作是非常麻烦的,所以就提出了Spring Task,它是Spring框架提供的任务调度工具,可以安装某个约定时间执行某个代码的逻辑,并且仅仅基于注解就可实现。
只要是需要定时处理的场景都可以使用Spring Task。
在我们的项目中通过用Spring Task来定时的处理异常订单(超时,一直处于派送状态),具体实现如下:
1.导入依赖
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>版本号</version>
</dependency>2. 开启定时任务
通过在启动类上使用@EnableScheduling注解来开启相关的定时任务功能。
3.@Scheduled注解实现定时任务
就是在我们需要定时任务的逻辑代码上加入@Scheduled注解并且通过cron表达式来设置这个任务多久执行一次。
/**
* 处理超时订单的方法(每个1分钟查询一次)
*/
@Scheduled(cron = "0 * * * * ?")
public void processTimeoutOrder() {
log.info("处理超时订单");
//查询到超时的未处理订单
List<Orders> ordersList = orderMapper.getByStatueAndOrderTime(Orders.PENDING_PAYMENT, LocalDateTime.now().minusMinutes(15));
//删除这些订单
if (ordersList != null && ordersList.size() > 0) {
for (Orders orders : ordersList) {
orders.setStatus(Orders.PENDING_PAYMENT);
orders.setCancelReason("订单超时,自动取消");
orders.setCancelTime(LocalDateTime.now());
orderMapper.update(orders);
}
}
}cron表达式其实就是一个字符串,通过cron表达式可以自定义任务触发的时间。它分为6或7个域,由空格分开,每个域代表一个含义。分别为:秒、分钟、小时、日、月、周、年(可选)。
比如:2022年10月12日上午9点整 对应的cron表达式为:0 0 9 12 10 ? 2022
说明:一般日和周的值不同时设置,其中一个设置,另一个用?表示。
为了描述这些信息,提供一些特殊的字符。这些具体的细节,我们就不用自己去手写,因为这个cron表达式,它其实有在线生成器。cron表达式在线生成器:在线Cron表达式生成器
Websocket:
WebSocket是一种单个TCP连接上进行全双工通信的协议,它使得客户端和服务器之间的数据交换变得更简单,容许服务器端主动的向客户端推送数据。并且浏览器和服务器只需要完成一次握手,两者就可以创建持久性的连接,并进行双向数据传输。
在我们的项目中,通过Websocket实现外卖催单和来单提醒这两个功能。用户在下单或者催单后,发送请求到后端,后端再发送该请求对应的逻辑到商家单来通知商家。
具体来说:
1.先在WebSocketConfiguration配置类中注册WebSocket的Bean
/**
* WebSocket配置类,用于注册WebSocket的Bean
*/
@Configuration
public class WebSocketConfiguration {
@Bean
public ServerEndpointExporter serverEndpointExporter() {
return new ServerEndpointExporter();
}
}2.编写WebSocket服务和它自己的方法
/**
* WebSocket服务
*/
@Component
@ServerEndpoint("/ws/{sid}")
public class WebSocketServer {
//存放会话对象
private static Map<String, Session> sessionMap = new HashMap();
/**
* 连接建立成功调用的方法
*/
@OnOpen
public void onOpen(Session session, @PathParam("sid") String sid) {
System.out.println("客户端:" + sid + "建立连接");
sessionMap.put(sid, session);
}
/**
* 收到客户端消息后调用的方法
*
* @param message 客户端发送过来的消息
*/
@OnMessage
public void onMessage(String message, @PathParam("sid") String sid) {
System.out.println("收到来自客户端:" + sid + "的信息:" + message);
}
/**
* 连接关闭调用的方法
*
* @param sid
*/
@OnClose
public void onClose(@PathParam("sid") String sid) {
System.out.println("连接断开:" + sid);
sessionMap.remove(sid);
}
/**
* 群发
*
* @param message
*/
public void sendToAllClient(String message) {
Collection<Session> sessions = sessionMap.values();
for (Session session : sessions) {
try {
//服务器向客户端发送消息
session.getBasicRemote().sendText(message);
} catch (Exception e) {
e.printStackTrace();
}
}
}
3.通过webSocketServer对象的方法来实现像商家端推送消息
/**
* 客户催单
* @param id
*/
@Override
public void reminder(Long id) {
//根据id查询订单,判断订单是否存在
Orders ordersDB = orderMapper.getById(id);
if (ordersDB == null) {
throw new OrderBusinessException(MessageConstant.ORDER_STATUS_ERROR);
}
Map map = new HashMap<>();
map.put("type",2);
map.put("orderId",id);
map.put("content","订单号" + ordersDB.getNumber());
String jsonString = JSONObject.toJSONString(map);
//通过websocket向客户端浏览器推送消息
webSocketServer.sendToAllClient(jsonString);
}商家端实现效果:
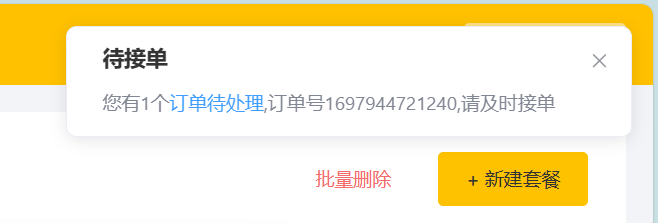
Apache POI:
Apache POI是一套开源的Java库,用于读取和写入 Microsoft Office 文档格式,如 Excel、Word 和 PowerPoint。用它可以使用Java读取和创建,修改MS Excel文件.而且,还可以使用Java读取和创建MS Word和MSPowerPoint文件。
在本项目中,管理员需要导出历史订单数据、菜品销售统计等信息到Excel文件。所以我们根据提供好的模板表,这样我们可以通过Apache POI来实现对这个模板表填充数据。
具体代码如下(能看懂就好):
/**
* 导出运行数据报表
* @param response
*/
@Override
public void exportBusinessData(HttpServletResponse response) throws IOException {
LocalDate begin = LocalDate.now().minusDays(30);
LocalDate end = LocalDate.now().minusDays(1);
//查询概览运营数据,提供给Excel模板文件
BusinessDataVO businessData = workspaceService.getBusinessData(LocalDateTime.of(begin, LocalTime.MIN), LocalDateTime.of(end, LocalTime.MAX));
//读取模板文件,作为输入流
InputStream inputStream = this.getClass().getClassLoader().getResourceAsStream("template/运营数据报表模板.xlsx");
//基于提供好的模板文件创建一个新的excel对象
XSSFWorkbook excel = new XSSFWorkbook(inputStream);
//获取文件中的一个sheet页
XSSFSheet sheet = excel.getSheet("Sheet1");
sheet.getRow(1).getCell(1).setCellValue(begin + "至" + end);
//获得第4行
XSSFRow row = sheet.getRow(3);
//获取单元格
row.getCell(2).setCellValue(businessData.getTurnover());
row.getCell(4).setCellValue(businessData.getOrderCompletionRate());
row.getCell(6).setCellValue(businessData.getNewUsers());
//获得第5行
row = sheet.getRow(4);
row.getCell(2).setCellValue(businessData.getValidOrderCount());
row.getCell(4).setCellValue(businessData.getUnitPrice());
//准备明细数据 30天
for (int i = 0; i < 30; i++) {
LocalDate date = begin.plusDays(i);
workspaceService.getBusinessData(LocalDateTime.of(date, LocalTime.MIN), LocalDateTime.of(date, LocalTime.MAX));
row = sheet.getRow(7 + i);
row.getCell(1).setCellValue(date.toString());
row.getCell(2).setCellValue(businessData.getTurnover());
row.getCell(3).setCellValue(businessData.getValidOrderCount());
row.getCell(4).setCellValue(businessData.getOrderCompletionRate());
row.getCell(5).setCellValue(businessData.getUnitPrice());
row.getCell(6).setCellValue(businessData.getNewUsers());
}
//通过输出流将Excel文件下载到客户端浏览器
ServletOutputStream outputStream = response.getOutputStream();
excel.write(outputStream);
//关闭资源
outputStream.close();
excel.close();
}个人感悟:
从初涉 JavaSE 的语法基础,到深入 JavaWeb 的交互逻辑,再到 SSM 框架的整合应用,直至 SpringBoot 的高效开发。而苍穹外卖项目的完成,更是让我将这些零散的知识串联起来,体会到了 Java 技术栈在实际项目中的应用。回顾整个学习和项目实践过程,我真正的理解到理论与实践相结合的重要性。单纯的理论学习只能让我了解知识的表面,只有通过实际项目的开发,才能巩固前面的知识点,真正掌握技术的精髓,发现问题并解决问题。并且也深刻的体会到了一个真实企业级的项目,从需求分析、接口设置、接口开发、架构设计和最后的项目的功能测试完整过程。这是我第一次写一个非常完整的项目,并且也是第一次写这种项目总结,如果有不好的地方,请大家多多指教,不过也对我来说是一次非常宝贵的经历。
我的java之路也才刚刚开始,后面还有很多需要提升的地方,还有不到一年的时间,一定要好好努力,希望在明年的这个时候找到一个满意的实习!!!

















 2567
2567

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









