



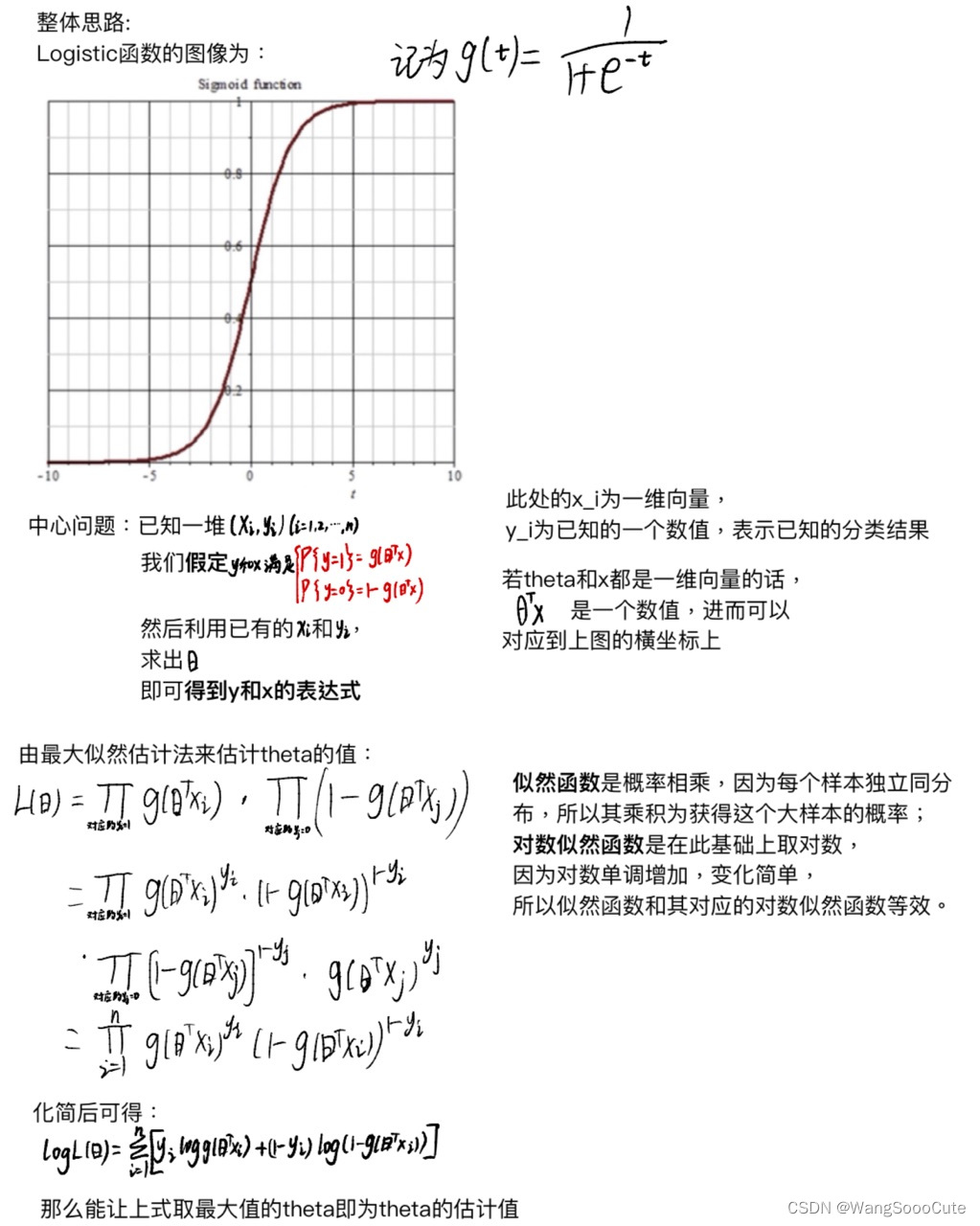
整体思路:
损失函数:


其他感悟:
这种假定分布的就像假定班级成绩服从正态分布一样,因为用的多了发现这种假定的期望loss最少,所以这么假定:

loss通常用|估计值-实际值|或者|估计值-实际值|^2,本文里用的是这个,其实际意义也非常明显:
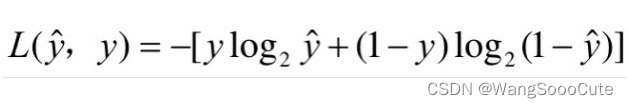
 本文探讨了在模型设计中,如何通过假定数据遵循正态分布来最小化损失函数。作者解释了为何这种假设在实践中常见,并详细介绍了使用绝对误差或平方误差作为loss函数的实际意义。
本文探讨了在模型设计中,如何通过假定数据遵循正态分布来最小化损失函数。作者解释了为何这种假设在实践中常见,并详细介绍了使用绝对误差或平方误差作为loss函数的实际意义。
这种假定分布的就像假定班级成绩服从正态分布一样,因为用的多了发现这种假定的期望loss最少,所以这么假定:
loss通常用|估计值-实际值|或者|估计值-实际值|^2,本文里用的是这个,其实际意义也非常明显:
 206
552
206
552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























