



L1G1000 了解全链路开源体系
经过老师的介绍,了解到了书生浦语大模型正在开课,于是报了个课来了解下,玩了几天准备对它来简单做个介绍,也让自己对这个大模型有个系统性的了解;
书生浦语官网
目前书生浦语正在开课,重点:
1、了解Ai行业行业前沿功能
2、免费
3、送用于服务器、显卡供你学习,学的越牛逼,送的越多
扫描以下二维码可以报名:

一、介绍
1、我们先让它自己介绍下自己:
1、书生浦语从去年中旬开始与大家见面,截止今日经过了多个版本的快速迭代,功能越来越强大,目前市面上主流的大模型功能它基本全都有,并且最最最重要的是支持全链条开源,与社区生态无缝连接。

2、这款大语言模型是全链条开源的,与社区生态无缝连接。它在性能上超过了国际主流的训练框架,如Hugging Face和Llamalndex。该模型支持千亿参数规模和百万上下文长度,具备多种微调和偏好对齐算法,适用于预训练和微调。此外,它还拥有首个精细处理的开源多模态语料库,以及多种部署和应用方案。
看下面这张图,大家就知道含精量有多少了吧,不得不说的是全链路开源,真的很良心很良心了,这不得不给上海人工智能实验室点个赞了;

3、书生浦语模型拥有不同的参数规模版本,以满足不同场景的需求:
1.8B:超轻量级,适用于端侧应用或开发者快速学习上手。
7B:模型轻便但性能不俗,适合轻量级研究和应用。
20B:综合性能更强,支持更复杂的实用场景。
102B:性能强大的闭源模型,典型场景表现接近GPT-4。
在20B的版本其实就很够一些小型公司做一些生产力工具,当然到了102B你会发现他的功能会有一个质的飞跃,是质的飞跃,你会感觉到完全不一样的人工智能体,更接近与gpt4;对了,这个是闭源的。

4、这个开源体系中下面三种开源数据处理工具非常重要
Miner U:一站式开源高质量数据提取工具,支持多格式(PDF/网页/电子书),智能萃取,生成高质量预训练/微调语料。
Label LLM:专业致力于LLM对话标注,支持指令采集、偏好收集、对话评估等,多人协作、任务管理、源码开放可魔改。
Label U:轻量级开源标注工具,支持图片、视频、音频多种数据标注,小巧灵活,AI标注导入二次人工精修。
在日常工作中,如果能灵活善用这些工具的话会对工作又很大的提升帮助,例如市场上现在稍有的开源标注工具,这个其实是能大大节省劳动力的,有过标注经验的小伙伴懂的都懂,腱鞘炎就是这么来的。。。。

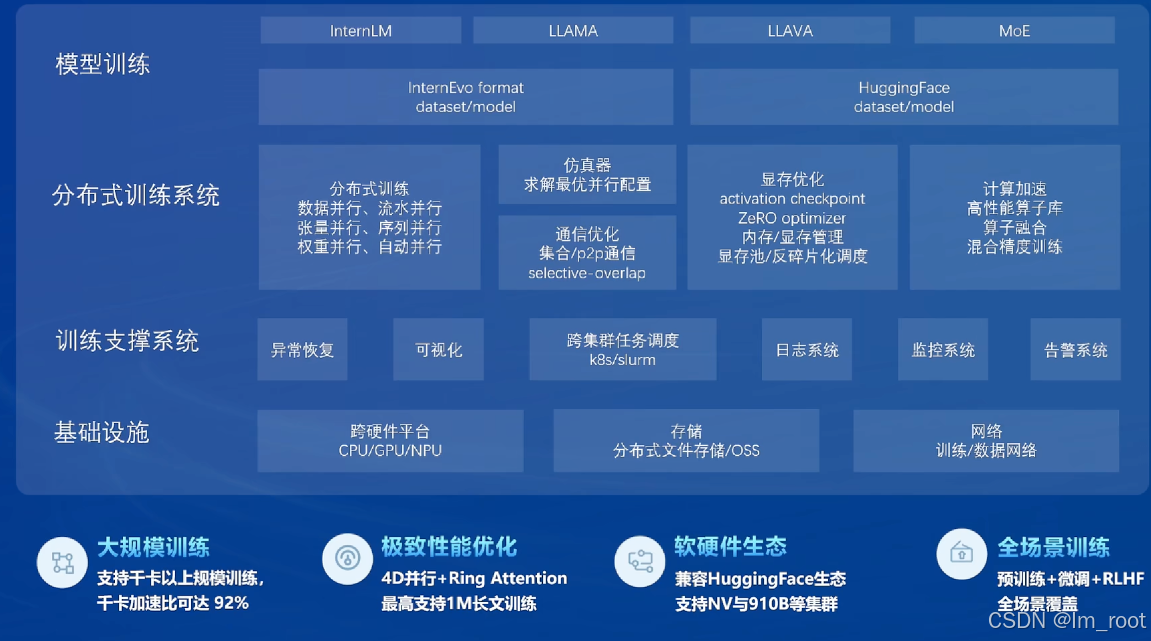
5、开源体系之预训练
分布式训练系统:
支持千卡以上规模训练,千卡加速比可达92%,这意味着即使是大规模的训练任务也能在短时间内完成。
4D并行和Ring Attention技术使得模型能够支持1M长文本的训练,这对于长文本处理任务尤为重要。
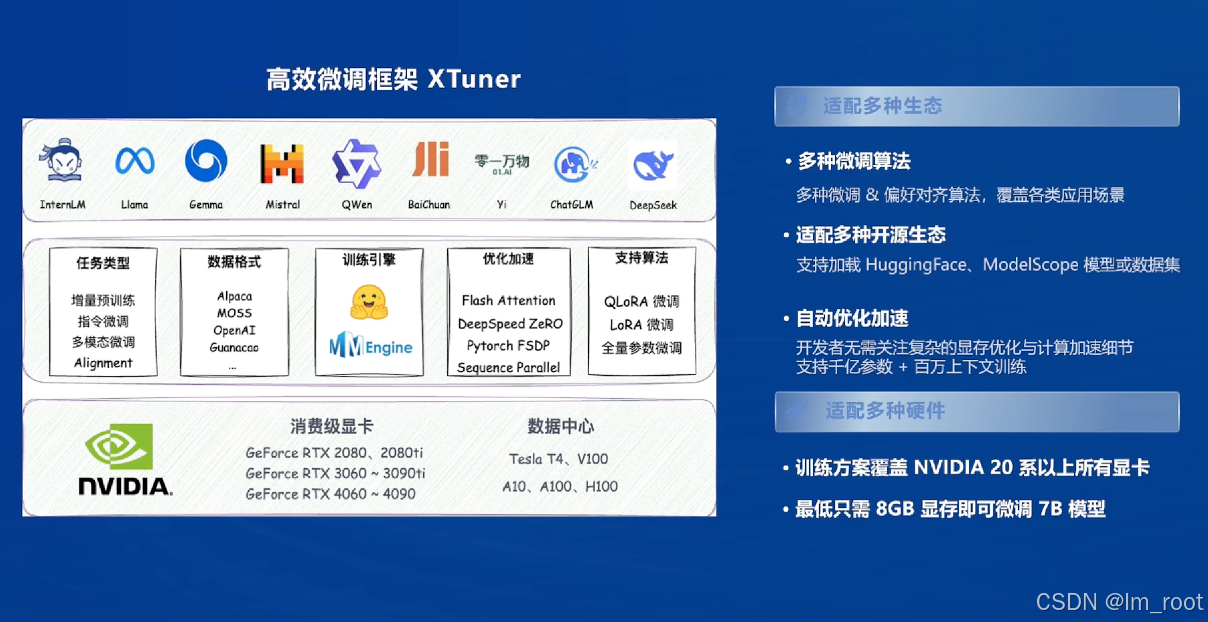
XTuner:
作为一个高效的微调框架,XTuner支持多种微调算法和偏好对齐,使得模型能够更好地适应特定的应用场景。
它还支持加载HuggingFace、ModelScope等开源生态的模型或数据集,这进一步增强了模型的灵活性和适用性。
这部分内容其实是含精量比较高了,也比较书面概念话,讲的很多都是底层的知识,对于想深入了解的小伙伴可以去官网挖掘下,如果单纯的知识想在应用端层面使用的话,了解即可;
6、目前已经应用的头部企业,

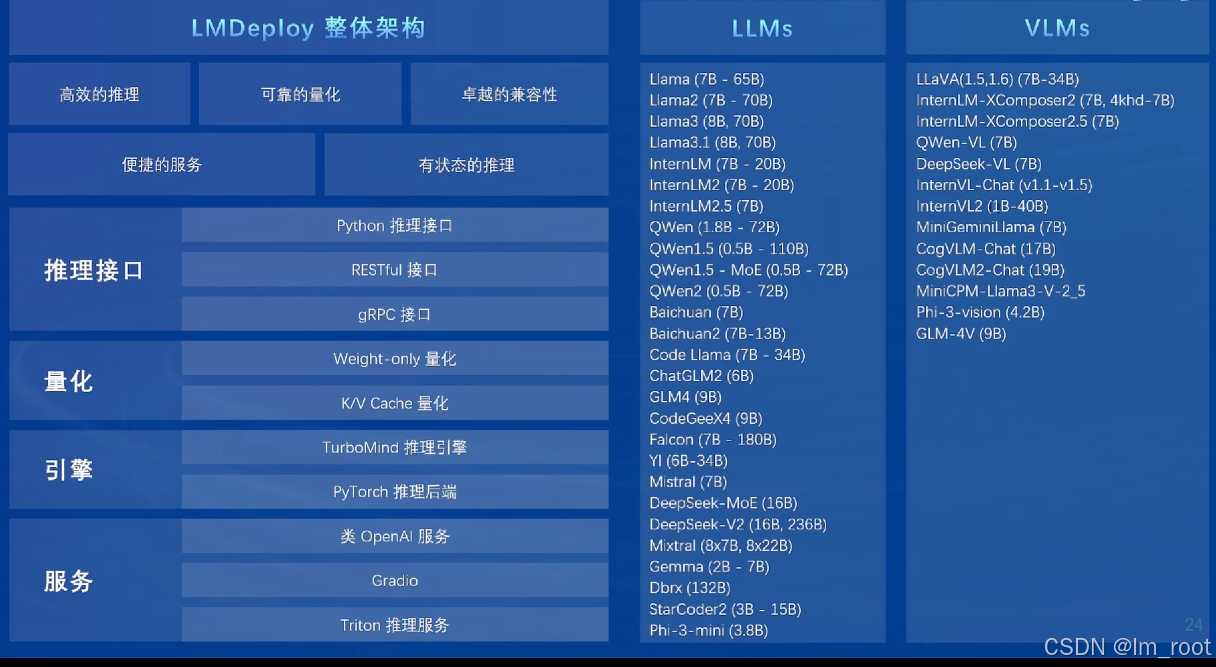
7、开源体系之部署LMDeploy:
提供了一个高效、可靠、兼容的部署架构,支持多种推理接口和服务,使得模型的部署变得简单快捷。
支持多种硬件平台,包括NVIDIA的多个系列显卡,这为用户提供了更多的选择和灵活性
二、我们可以学习什么,聊聊自己的对ai行业的感悟
1、其实对于大多数普通来说来,用的对最多的是他的智能体问答功能了,解答日常遇到的问题、规划履行计划、做计算题、代码开发等内容
2、进一步的话特别是作为开发人员,ai这两个字在行业的含精量不用我多说了,通过这门课程你可以对ai是怎么来的,ai能干什么,我们怎么做一个ai出来有一个系统性的了解。对我们以后的工作环节、找工作环节、或者最重要的好友吹牛逼环节都很重要。
下一个时代革命肯定是ai革命毋庸置疑,就看还需要多少时间了。趁此机会一起尽量多了解下,才能不被时代抛弃。加油💪🏻

















 2252
2252

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









