




笔记开始(热身)
任务概览:
1、闯关任务:Leetcode 383(笔记中提交代码与leetcode提交通过截图)
2、可选任务 1:将Linux基础命令在开发机上完成一遍
3、可选任务 2:使用 VSCODE 远程连接开发机并创建一个conda环境
★ 闯关任务:Leetcode 383(笔记中提交代码与leetcode提交通过截图)
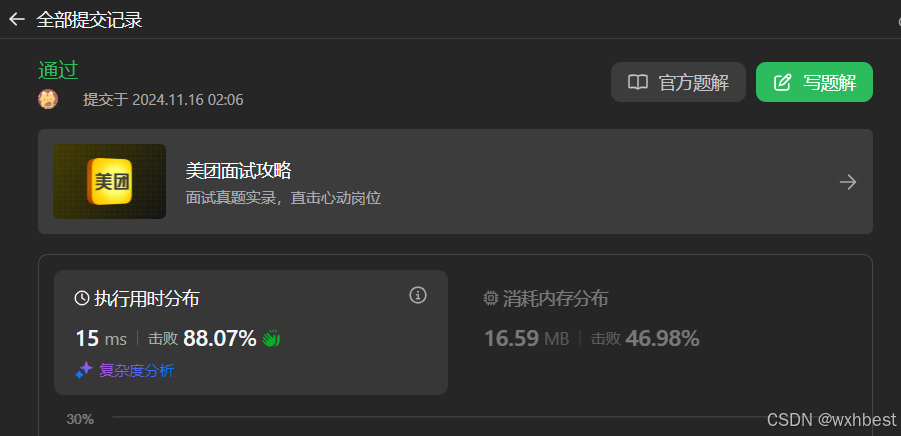
解答: 首先贴上leetcode通过截图
一开始因为屏幕分辨率的关系,没有看到下面的提示,
提示:
1 <= ransomNote.length, magazine.length <= 105ransomNote和magazine由小写英文字母组成
所以我用了相对比较傻的方法写了一个。
# 导入collections 模块中的Counter 类,用于统计字符串中的字符出现的次数
from collections import Counter
# 定义了一个名为 Solution 的类
class Solution:
# Solution 类的一个方法定义,canConstruct 方法接受三个参数:self(类的实例),ransom(赎金信字符串),和 magazine(杂志字符串)
def canConstruct(self, ransom, magazine):
# 使用 Counter 类创建了一个计数器对象 用于统计 magazine 字符串中每个字符出现的次数
magazine_count = Counter(magazine)
# 循环遍历 ransom 字符串中的每个字符
for char in ransom:
# 检查 magazine_count 计数器中当前字符 char 的计数是否为0。
if magazine_count[char] == 0:
#如果是0,意味着 magazine 中没有这个字符,因此无法构成 ransom,方法返回 False
return False
# 如果 magazine 中存在当前字符 char,则将其在 magazine_count 中的计数减1,模拟从magazine 中使用了这个字符。
magazine_count[char] -= 1
# 如果循环结束后没有返回 False,说明 ransom 中的每个字符都可以在 magazine 中找到,因此方法返回 True,表示 ransom 可以由 magazine 中的字符构成
return True
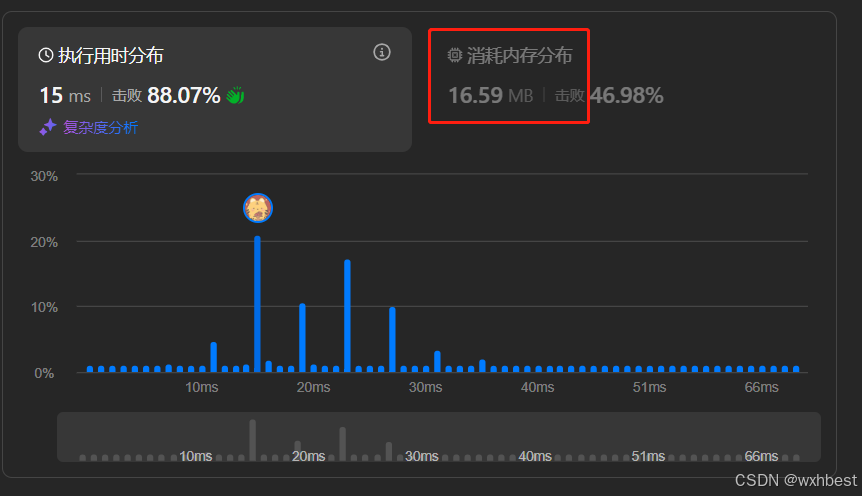
后来,往下拉看到了提示,因为ransomNote和magazine的长度都在1到10^5之间,且它们只包含小写英文字母。我就弃用了Counter类,因为Counter类在处理大字符串时可能会比较慢。(leetcode也告诉了我该方法内存占用过大,如下图)然后我就想用一个固定大小的数组来统计magazine中每个字符的出现次数,因为英文字母表只有26个字母。
class Solution:
def canConstruct(self, ransom, magazine):
# 初始化一个长度为26的列表,用于存储每个字母的出现次数
magazine_count = [0] * 26
# 遍历magazine字符串,统计每个字母的出现次数
for char in magazine:
magazine_count[ord(char) - ord('a')] += 1
# 遍历ransom字符串,对于每个字符,检查magazine中是否有足够的出现次数
for char in ransom:
# 如果magazine中没有这个字符或者字符数量不足,返回False
if magazine_count[ord(char) - ord('a')] == 0:
return False
# 否则,减少这个字符的计数
magazine_count[ord(char) - ord('a')] -= 1
# 如果所有字符都能找到,返回True
return True
★ 闯关任务:Vscode连接InternStudio debug笔记
解答:
1、通过题目给出的代码,加入API_KEY执行后发现会报错:
res_json = json.loads(res) 发生异常: JSONDecodeError Expecting value: line 1 column 1 (char 0) StopIteration: 0 During handling of the above exception, another exception occurred: File "/root/test.py", line 31, in <module> res_json = json.loads(res) ^^^^^^^^^^^^^^^ json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
根据我的理解,这个异常是解析到了一个空字符串或者不是一个有效 JSON 格式的字符串时。而错误信息表明解析器在第一个字符就期望一个值,但是没有找到,这个异常可能是由于internlm_gen 函数返回的 res 变量是一个空字符串或者 None。可能是因为 API 返回的数据不是有效的 JSON 字符串。
那最简单来说,就是将原始的返回值打印出来,以便检查是否有错误信息。
通过输出,得到如下结果
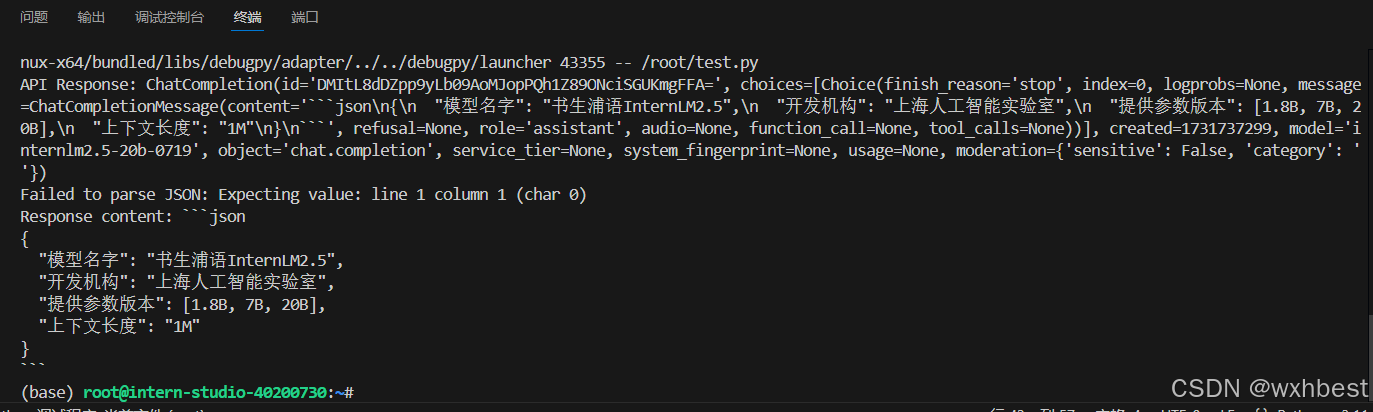
可以看到,在返回的JSON中,有些值表示不规范,比如:```json、或者是【提供的参数版本】这个key,没有引号的包围。所以我准备使用正则表达式来查找、替换、规范这些字符串(一开始我想写死的,后来发现没有通用性,例如一旦1.8B变成2.5B就不可用了),并且去除多余的引号和换行符使得从 API 获取的包含数组标记的 JSON 字符串能够被清理并正确解析为 Python 对象,以便程序正确运行并输出结果。
先展示一下我的成果:

附上我的代码:
from openai import OpenAI
import json
import re
import os
def internlm_gen(prompt, client):
'''
LLM生成函数
Param prompt: prompt string
Param client: OpenAI client
'''
response = client.chat.completions.create(
model="internlm2.5-latest",
messages=[
{"role": "user", "content": prompt},
],
stream=False
)
return response.choices[0].message.content
api_key = os.getenv('api_key')
client = OpenAI(base_url="https://internlm-chat.intern-ai.org.cn/puyu/api/v1/",api_key=api_key)
content = """
书生浦语InternLM2.5是上海人工智能实验室于2024年7月推出的新一代大语言模型,提供1.8B、7B和20B三种参数版本,以适应不同需求。
该模型在复杂场景下的推理能力得到全面增强,支持1M超长上下文,能自主进行互联网搜索并整合信息。
"""
prompt = f"""
请帮我从以下``内的这段模型介绍文字中提取关于该模型的信息,要求包含模型名字、开发机构、提供参数版本、上下文长度四个内容,以json格式返回。
`{content}`
"""
res = internlm_gen(prompt, client)
# 去除多余的反引号和换行符
res_cleaned = res.strip().replace('```json', '').replace('```', '').strip()
# 使用正则表达式将所有看起来像数字但实际上是字符串的值用引号括起来
res_fixed = re.sub(r'(\b\d+\.\d+[A-Za-z]+\b|\b\d+[A-Za-z]+\b)', r'"\1"', res_cleaned)
# 手动去除多余的引号
res_fixed = res_fixed.replace('""', '"')
res_json = json.loads(res_fixed)
print(res_json)
★ 可选任务:pip安装到指定目录
解答: 根据题意,要求使用VScode连接开发机后使用pip install -t命令安装一个numpy到看开发机/root/myenvs目录下,并成功在一个新建的python文件中引用。题意没有要求创建或使用虚拟环境,那我就按照最常规的方式去操作。
首先,我创建一个myenvs的文件夹,然后执行numpy的安装
mkdir -p /root/myenvs
python -m pip install -t /root/myenvs numpy
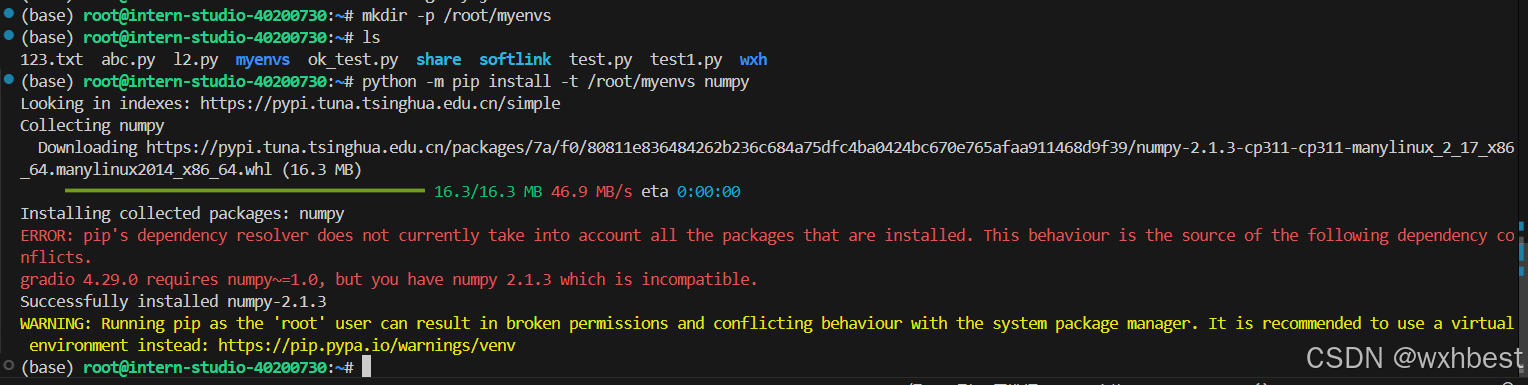
这里看到一个插曲,我没有指定numpy的版本,所以安装之后报错,大致意思是gradio 需要 numpy 的版本约等于 1.0,而我安装的是 2.1.3,提示不兼容。按照提示,按照提示,有两种解决方案,一种是卸载刚才安装的numpy,然后安装版本约等于1.0的版本;另一种就是安装 gradio 并让 pip 自动处理依赖关系。
python -m pip uninstall numpy
pip index versions numpy

可以看到,最低版本是1.3.0,那我们就安装1.3.0
python -m pip install numpy==1.3.0
但是报错了
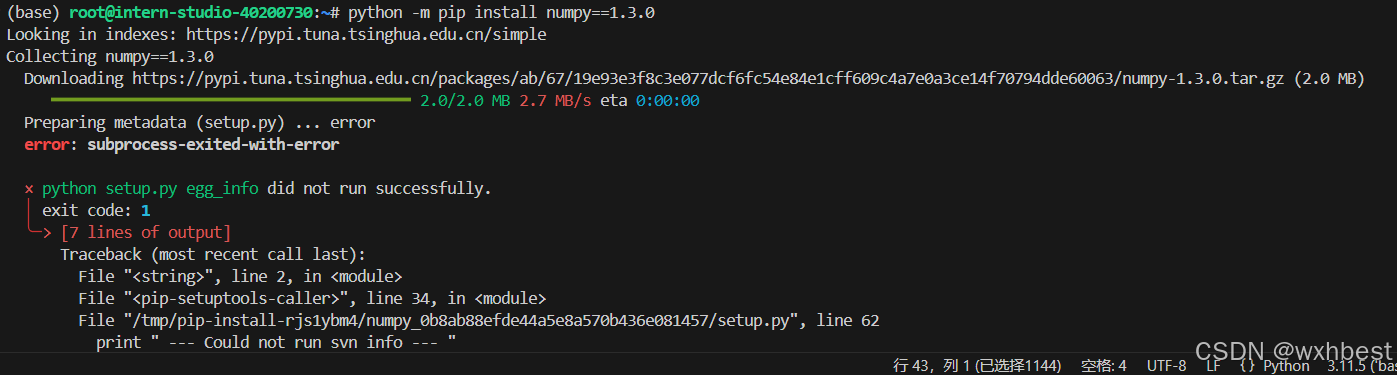
第一种方式失败了,我就采取第二种试一下
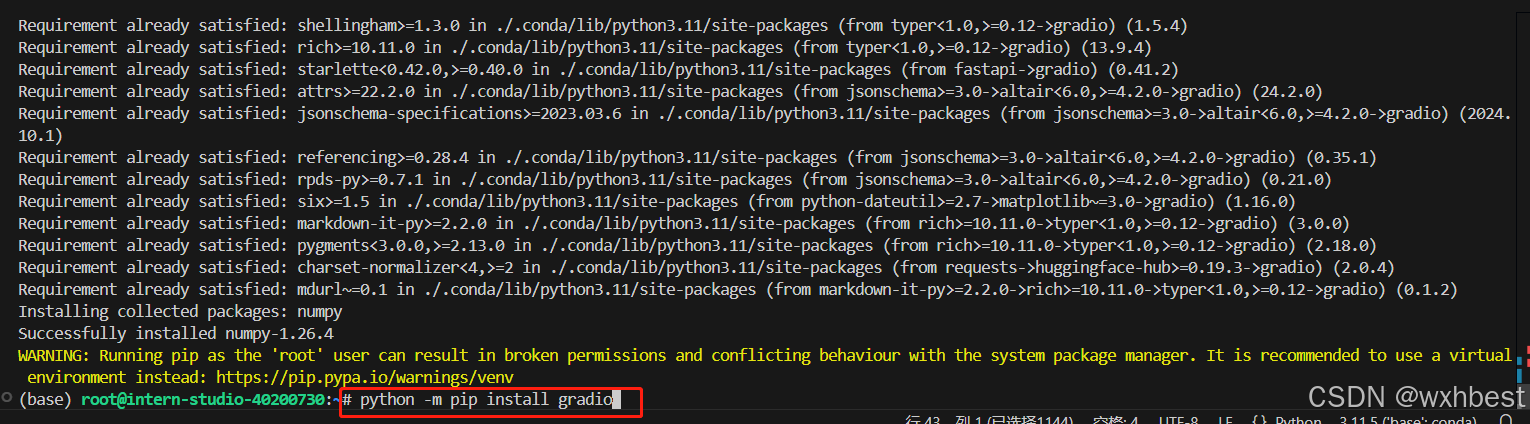
OK了,应该是可以了,我们检查一下。
python -c "import numpy; print(numpy.__version__)"

说明成功安装了1.26.4版本的numpy;那我进行后一步,进入/root/myenvs目录,新建一个python文件并引用numpy。

import numpy #引入numpy
print(numpy.__version__) #打印版本号
通过前面教学的echo命令进行写入new.py,并通过tee命令显示
 执行new.py
执行new.py

成功获取版本号。

















 907
907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









