




任务概览
1、基础任务:
- 理解多模态大模型的常见设计模式,可以大概讲出多模态大模型的工作原理。
- 了解InternVL2的设计模式,可以大概描述InternVL2的模型架构和训练流程。
- 了解LMDeploy部署多模态大模型的核心代码,并运行提供的gradio代码,在UI界面体验与InternVL2的对话。
- 了解XTuner,并利用给定数据集微调InternVL2-2B后,再次启动UI界面,体验模型美食鉴赏能力的变化。
开始任务:
基础任务:
1、理解多模态大模型的常见设计模式,可以大概讲出多模态大模型的工作原理。
多模态大模型是指能够处理和理解多种类型数据(如文本、图像、声音等)的人工智能模型。这些模型的目的是整合不同模态的信息,实现跨模态的理解与生成,以获得更丰富的理解和更好的性能。
下面是课程视频的一些关键截图:


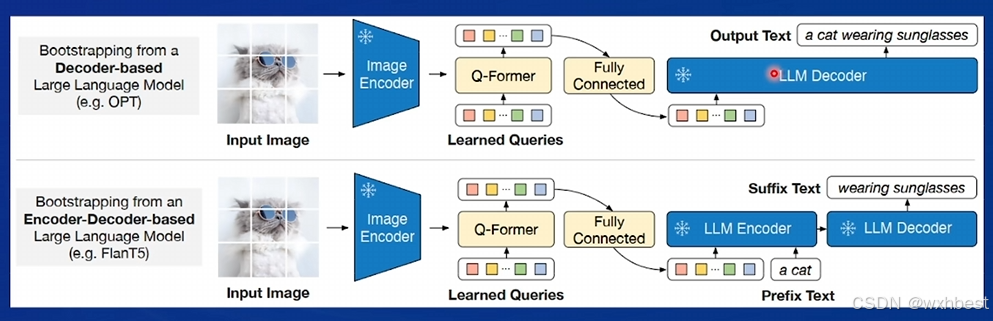
它们的核心设计模式主要分为 Q-Former(如 BLIP-2 系列) 和 ViT+MLP(如 LLaVA 系列) 两种。以下是这两种架构的工作原理及其特点的详细介绍:
1. BLIP-2 系列的 Q-Former
基本原理
BLIP-2(Bootstrapped Language-Image Pretraining)采用了一种名为 Q-Former(Query-Transformer) 的中间模块,作为视觉模态和语言模态的桥梁。其工作流程如下:
- 视觉特征提取:通过一个预训练的视觉编码器(如 ViT,Vision Transformer)提取图像的底层特征,这些特征可以看作是图像的多维嵌入表示。
- Q-Former 对接视觉特征:(1)Q-Former 是一个轻量级的 Transformer 模块,包含固定数量的 learnable queries(可学习查询向量)。(2)Q-Former通过 self-attention 和 cross-attention 机制,将 learnable queries 与视觉特征进行交互,从图像特征中提取与语言模态关联性更强的信息。
- 语言生成:(1)经过 Q-Former 编码的模态对齐特征被传递到一个冻结的语言模型(如 GPT 或 LLaMA)。(2)语言模型负责对齐模态特征后执行下游任务(如图像描述生成、跨模态问答等)。
特点
- 高效性:通过轻量化的 Q-Former,BLIP-2 不需要对大型语言模型(LLM)进行微调,能高效地连接视觉和语言模态。
- 灵活性:Q-Former模块作为一个中介层,可以适配不同的视觉编码器和语言模型。
- 任务能力强:在图文生成、问答等任务上表现优异,尤其是在对图像与文本信息高度相关的场景中。
2. LLaVA 系列的 ViT + MLP
基本原理
LLaVA(Large Language and Vision Assistant)系列模型主要使用 ViT(Vision Transformer)+ MLP(多层感知机) 的设计,将视觉特征直接映射到语言模型可以理解的嵌入空间。工作流程如下:
- 视觉特征提取:(1)使用 ViT 作为图像编码器,从图像中提取 patch 特征,将其表示为一组嵌入向量。(2)这些向量捕捉了局部和全局的视觉模式。
- 特征映射:(1)使用一个多层感知机(MLP)将视觉特征映射到与语言嵌入对齐的空间。(2)MLP 的作用是对视觉特征进行简单的非线性变换,使其与语言模型的输入维度匹配。
- 语言生成:映射后的视觉特征直接与语言模型(如 LLaMA 或 GPT)交互,作为语言模型的输入,结合已有的上下文信息生成跨模态的输出(如对图像的问答)。
特点
- 简单直接:ViT + MLP 模块设计简单,易于实现且推理速度快。
- 端到端训练:LLaVA 采用端到端的方式微调视觉特征提取模块和语言模型,更紧密地结合视觉和语言模态。
- 成本较低:由于去除了 Q-Former 等中介层,整体架构较为轻量。
- 适合交互:尤其适用于需要实时响应的对话类任务,如跨模态聊天和辅助。
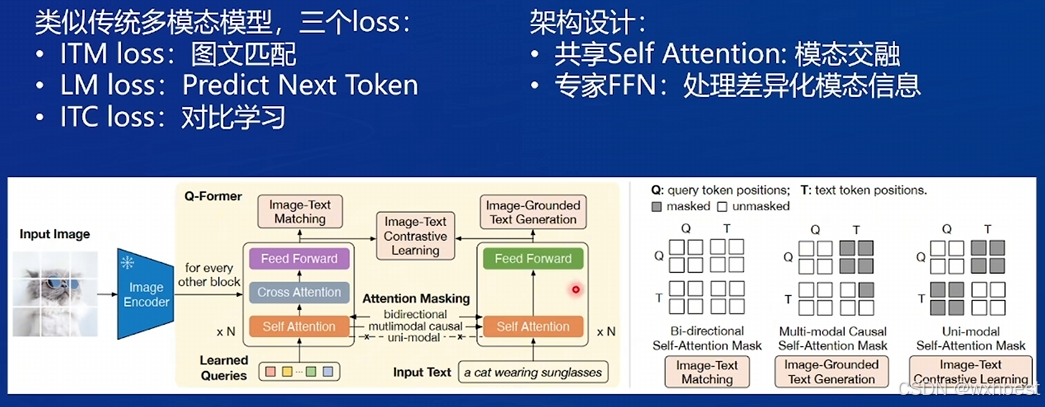
多模态大模型的工作原理通常涉及到复杂的网络结构和训练策略,目的是充分利用不同模态中的互补信息,以提高模型的性能和泛化能力。这些模型在诸如自动标注、内容检索、情感分析和人机交互等领域有着广泛的应用。
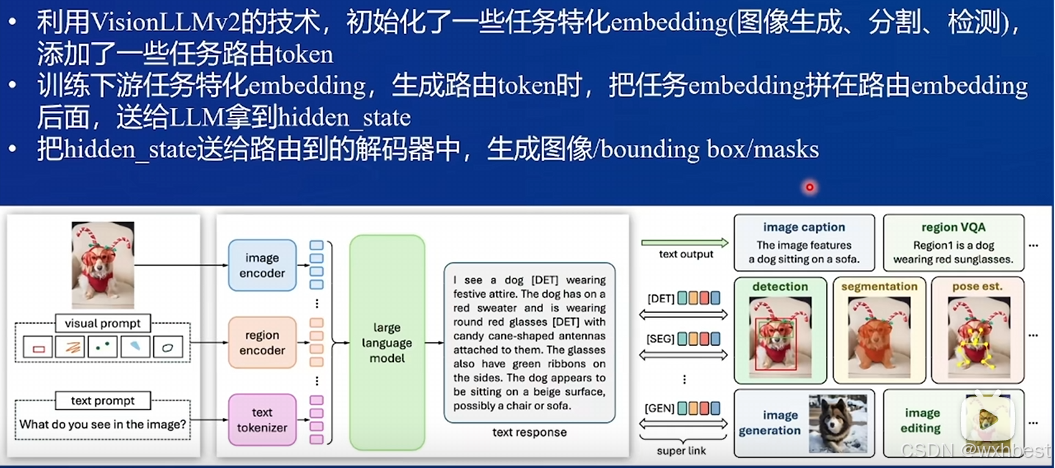
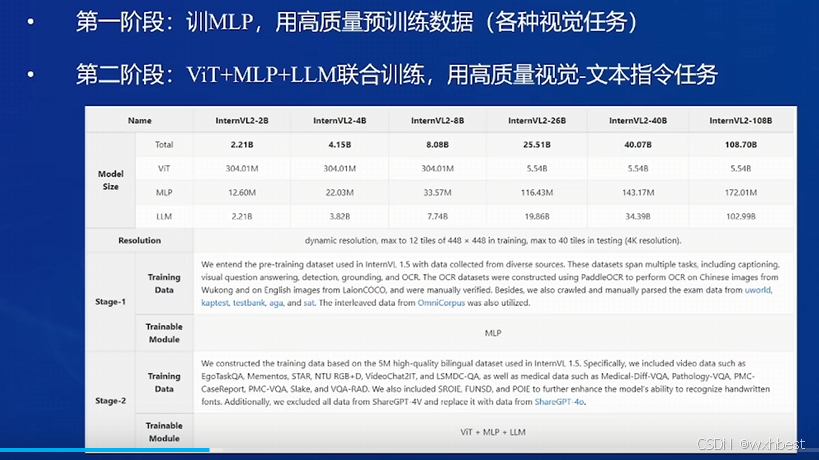
2、了解InternVL2的设计模式,可以大概描述InternVL2的模型架构和训练流程。
模型架构:
InternVL2 是一种多模态大模型,主要架构包括 ViT、Pixel Shuffle 和 MLP,并在训练过程中采用动态分辨率。

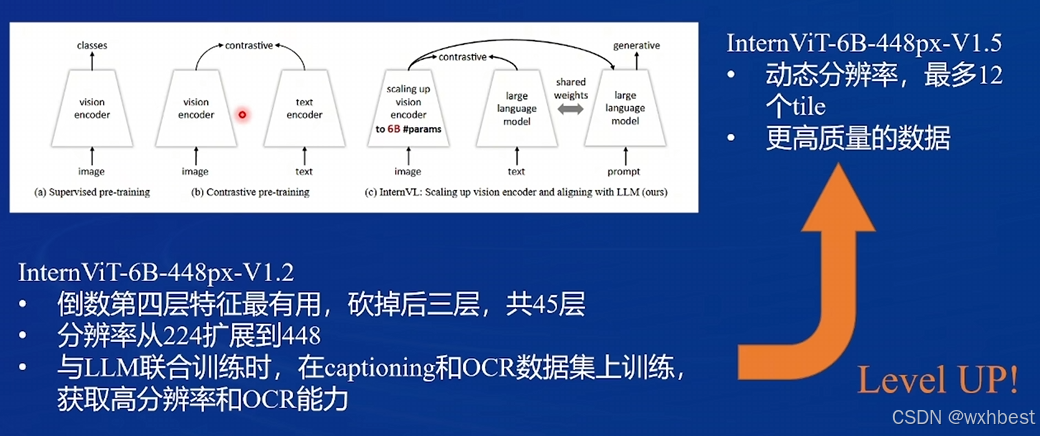
ViT(Vision Transformer)
- InternVL2 使用了 ViT 作为主要的视觉编码器,用于提取图像的视觉特征。
- ViT 将图像分割为 patch(图像块),并将每个 patch 转换为嵌入表示,输入 Transformer 模块以捕获全局信息。
- 这种设计保留了图像的细粒度信息,非常适合多模态任务。
Pixel Shuffle
- 在 InternVL2 中,Pixel Shuffle 的作用是对视觉特征进行空间重构,提升特征的分辨率,从而在下游任务中捕获更细致的视觉细节。
- Pixel Shuffle 可以在不显著增加计算开销的情况下提高视觉特征的解析度。
MLP(多层感知机)
- 用于对视觉特征进行进一步变换,映射到语言模型可以理解的嵌入空间。
- MLP 模块在 InternVL2 的早期阶段单独训练,主要目的是为视觉模态与语言模态之间建立初步连接。
动态分辨率
- 在训练过程中,InternVL2 支持动态分辨率,从低分辨率开始训练,逐渐过渡到高分辨率。
- 动态分辨率的使用能够有效减少训练资源,同时保证模型在高分辨率任务上的性能。
Text Encoder 的保留
- 不同于 CLIP(丢弃了文本编码器,仅使用视觉编码器生成跨模态嵌入),InternVL2 保留了文本编码器,使得模型能够直接处理文本信息,而不依赖额外的嵌入生成步骤。
- 保留文本编码器增强了模型对文本模态的处理能力,提高了跨模态对齐的精度。
训练流程:主要分2个阶段
第一阶段:单独训练 MLP
第二阶段:联合训练 ViT、MLP 和 LLM
3、了解LMDeploy部署多模态大模型的核心代码,并运行提供的gradio代码,在UI界面体验与InternVL2的对话。
进入开发机,新建虚拟环境并进入:
conda create --name xtuner-env python=3.10 -y
conda activate xtuner-env安装与deepspeed集成的xtuner和相关包:
pip install xtuner==0.1.23 timm==1.0.9
pip install 'xtuner[deepspeed]'
pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cu121
pip install transformers==4.39.0 peft==0.13.2推理环境配置:
conda create -n lmdeploy python=3.10 -y
conda activate lmdeploy
pip install lmdeploy==0.6.1 gradio==4.44.1 timm==1.0.9LMDeploy部署
拉取本教程的github仓库的代码,
git clone https://github.com/Control-derek/InternVL2-Tutorial.git
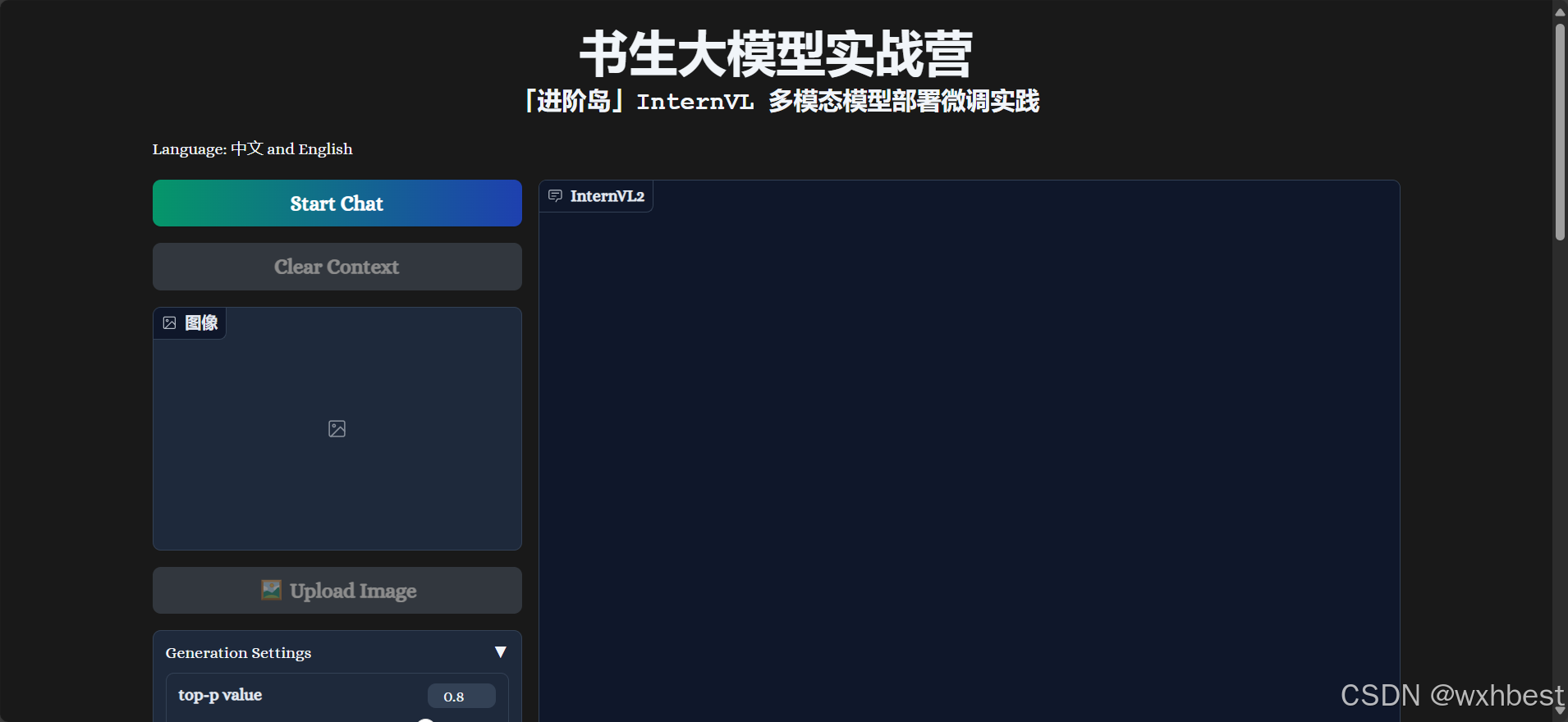
cd InternVL2-Tutorial使用UI界面,启动demo:
conda activate lmdeploy
python demo.py通过ssh转发1096端口,可以看到如下界面:
XTuner微调实践
进入环境:
cd /root/xtuner
conda activate xtuner-env # 或者是你自命名的训练环境原始internvl的微调配置文件在路径./xtuner/configs/internvl/v2下,我们将刚才克隆的仓库/root/InternVL2-Tutorial,复制配置文件到目标目录下:
cp /root/InternVL2-Tutorial/xtuner_config/internvl_v2_internlm2_2b_lora_finetune_food.py /root/xtuner/xtuner/configs/internvl/v2/internvl_v2_internlm2_2b_lora_finetune_food.py根据教程,我们去下载一下huggingface的数据集。
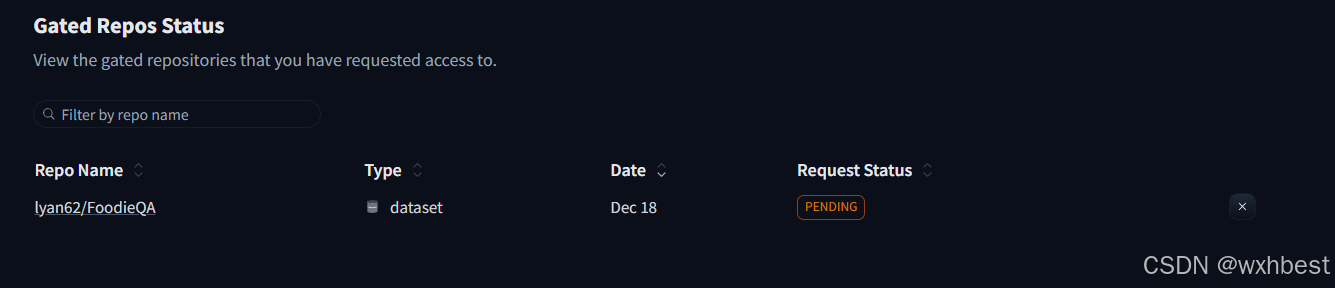
可以看到,我已经提交了申请,等待作者的同意。
我们暂时先用/root/share/datasets/FoodieQA下的进行微调。
xtuner train /root/xtuner/xtuner/configs/internvl/v2/internvl_v2_internlm2_2b_lora_finetune_food.py --deepspeed deepspeed_zero2看到巴拉巴拉跳日志了,说明已经在跑了。
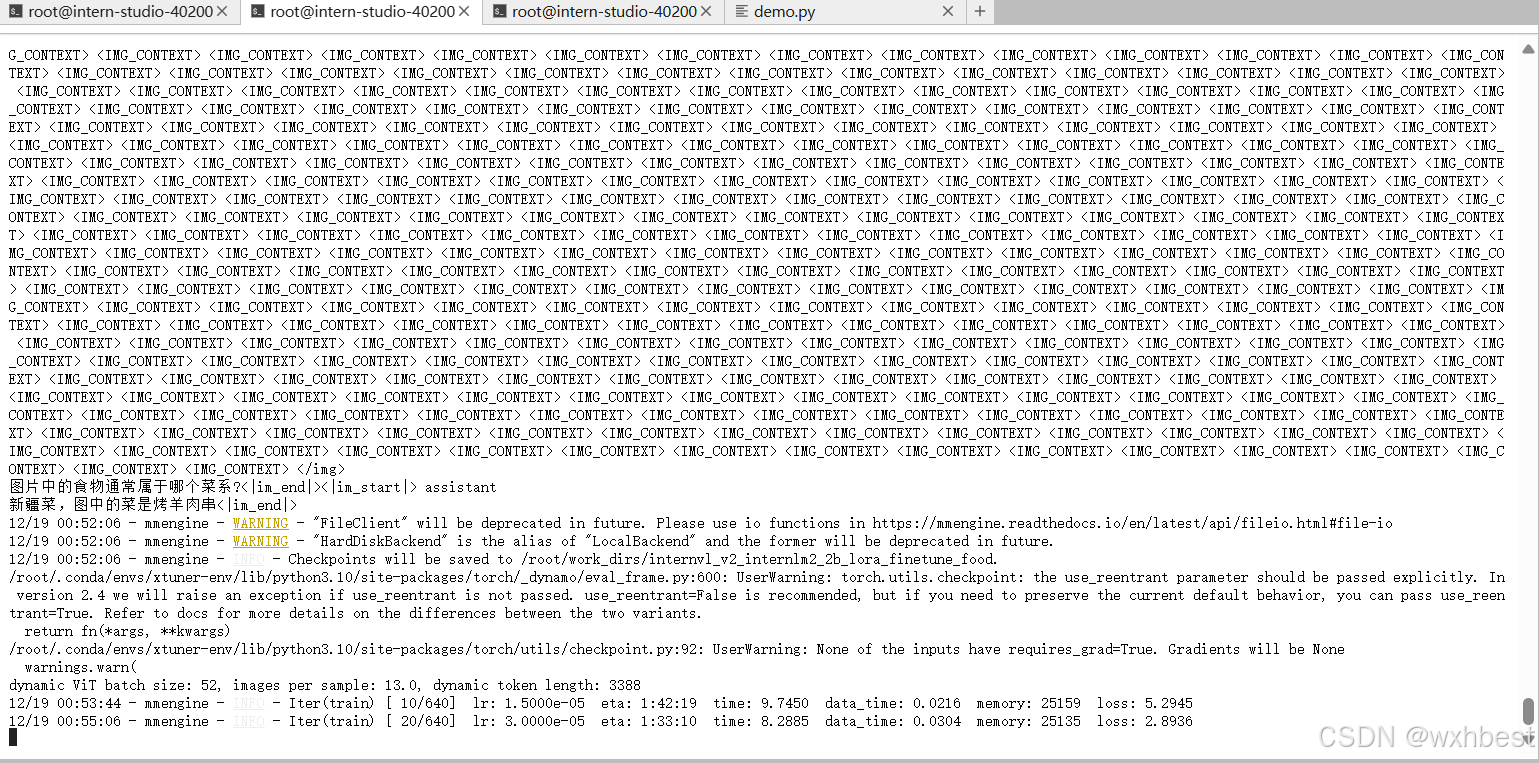
可以看到,跑的时候,显卡消耗也是巨大的。
![]()
微调后,把模型checkpoint的格式转化为便于测试的格式:
python xtuner/configs/internvl/v1_5/convert_to_official.py xtuner/configs/internvl/v2/internvl_v2_internlm2_2b_lora_finetune_food.py ./work_dirs/internvl_v2_internlm2_2b_lora_finetune_food/iter_640.pth ./work_dirs/internvl_v2_internlm2_2b_lora_finetune_food/lr35_ep10/4、了解XTuner,并利用给定数据集微调InternVL2-2B后,再次启动UI界面,体验模型美食鉴赏能力的变化。
修改MODEL_PATH为刚刚转换后保存的模型路径:

运行demo.py
cd /root/InternVL2-Tutorial
conda activate lmdeploy
python demo.py启动代码,ssh转发,我们对比和之前的差异。
微调前,把肠粉错认成越南春卷,微调后,正确识别:
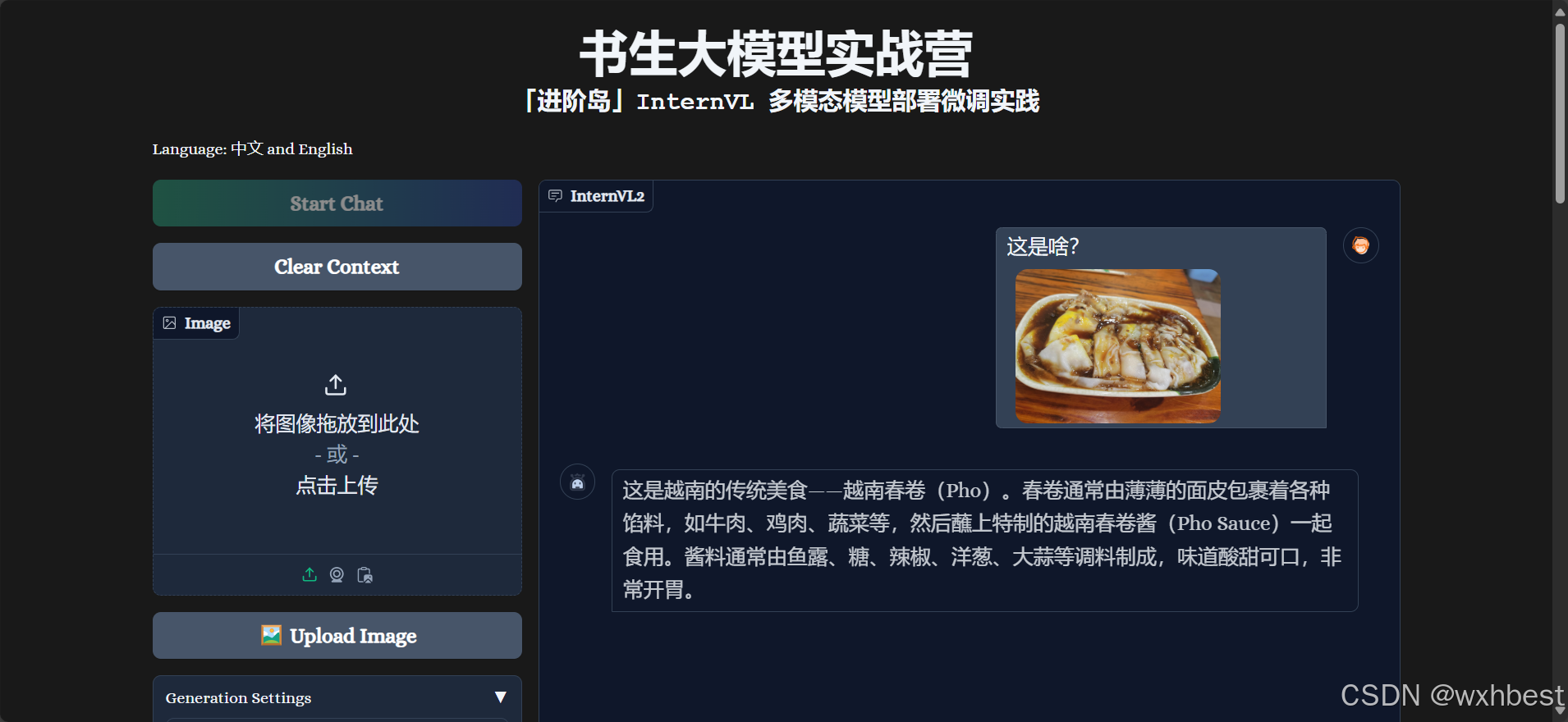
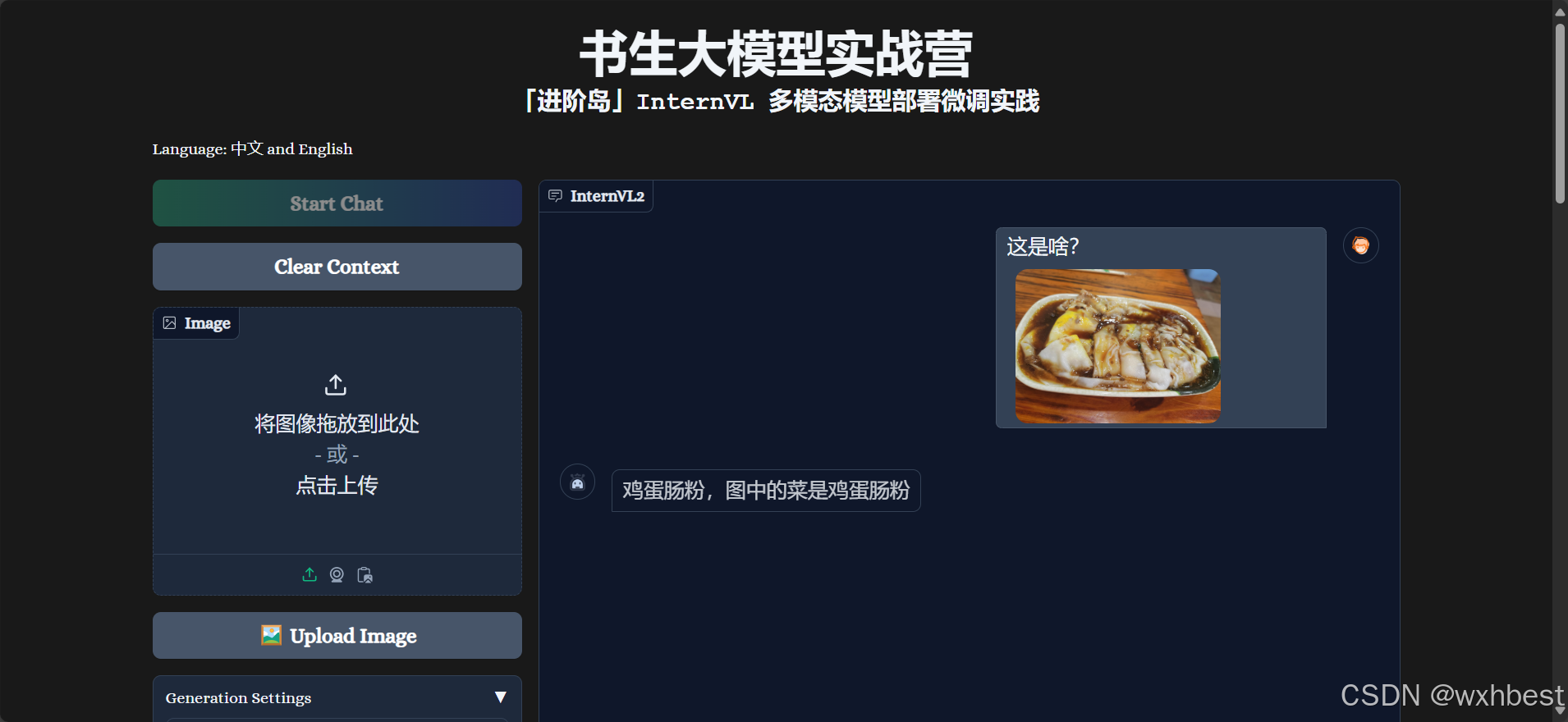
微调前,把锅包肉错认成炸鸡排,微调后,正确识别:
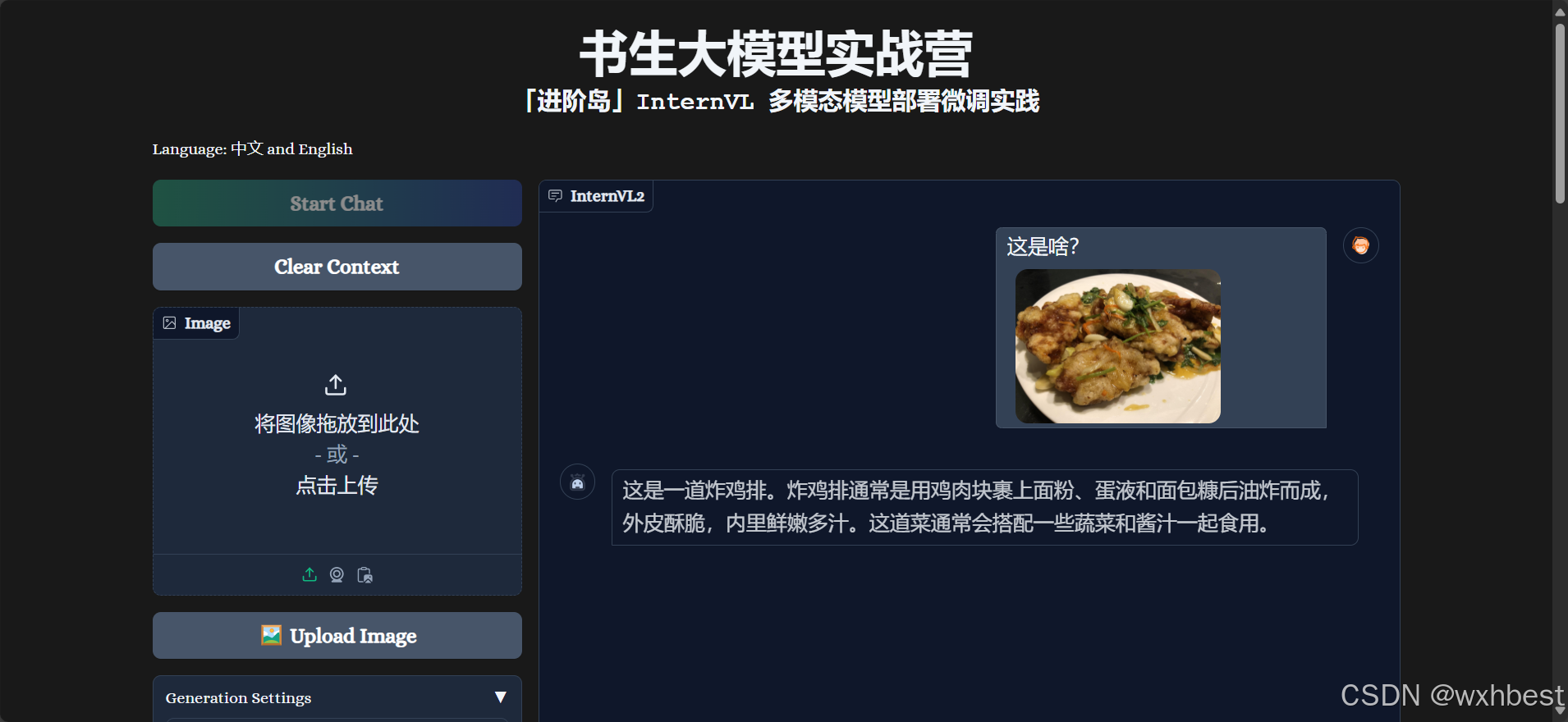
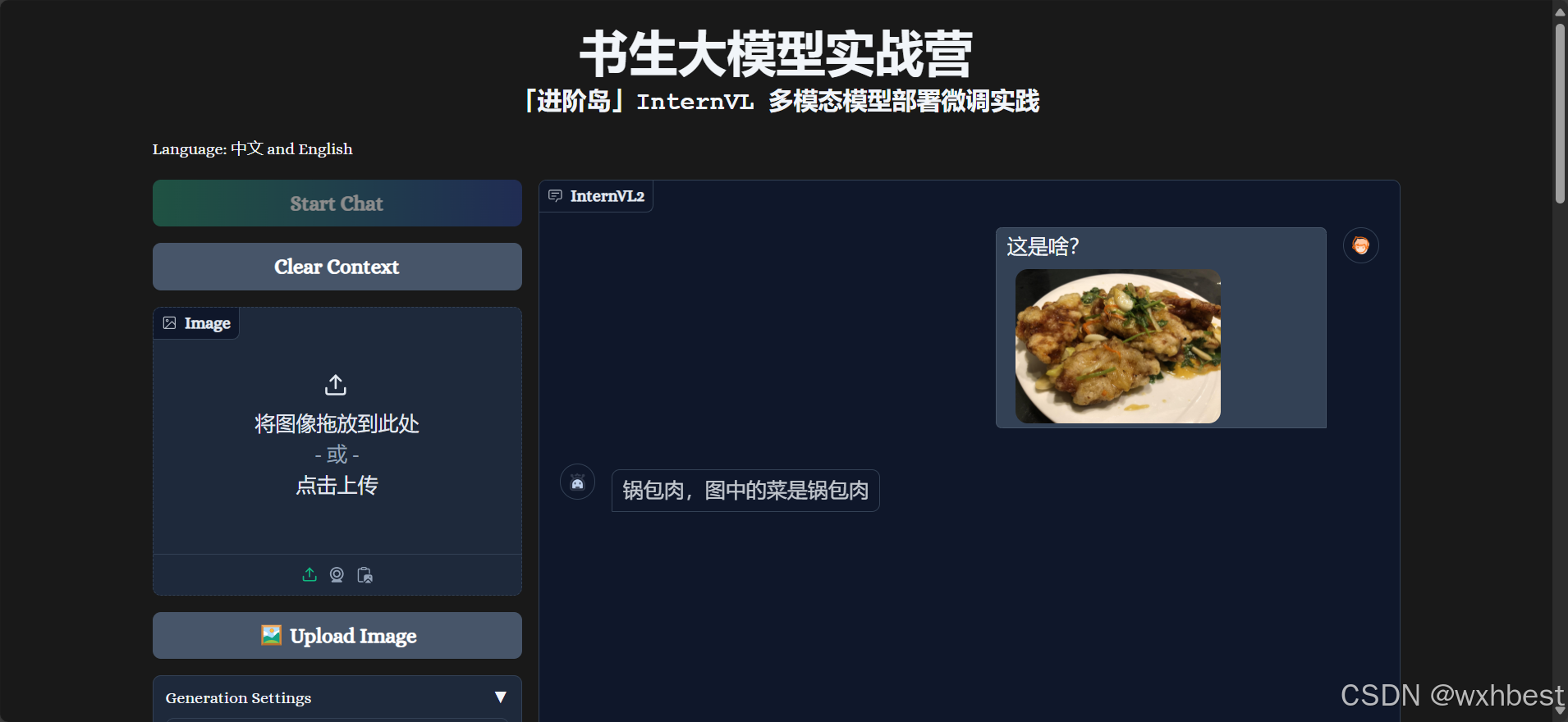
至此,此关完美结束!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









