






 论文介绍了一个新基准HaluEval-Wild,用于评估大型语言模型在现实场景中的幻觉。它通过真实用户交互数据和细化的特征提取提升幻觉检测。研究发现不同模型在处理挑战性查询时有显著差异,提示了知识蒸馏模型的局限性。
论文介绍了一个新基准HaluEval-Wild,用于评估大型语言模型在现实场景中的幻觉。它通过真实用户交互数据和细化的特征提取提升幻觉检测。研究发现不同模型在处理挑战性查询时有显著差异,提示了知识蒸馏模型的局限性。
原文:HaluEval-Wild:Evaluating Hallucinations of Language Models in the Wild
这篇论文介绍了一个名为“HaluEval-Wild”的新基准测试,旨在评估大型语言模型(LLMs)在真实世界环境中的幻觉率。传统的NLP任务如知识密集型问答和摘要等基准测试不足以捕捉用户与LLMs之间的复杂交互,因此该研究收集了来自现有真实世界用户-LLM交互数据集的挑战性查询,并将其分类为五种不同类型以进行精细分析。通过使用强大的GPT-4模型和检索增强生成技术,研究人员还合成了一些参考答案。这项工作提供了一种新颖的方法,有助于提高我们对LLMs在现实场景中可靠性的理解和改进。
论文方法
方法描述
本研究旨在构建一个挑战性的数据集HaluEval-Wild,用于评估大型语言模型(LLM)在实际场景中的表现。该数据集来源于真实用户与LLM之间的交互记录,并通过以下两个步骤来筛选出具有挑战性的查询:
- 利用ShareGPT1原始数据集中的第一轮对话,识别可能导致LLM产生幻觉的用户查询。
- 使用伪标签训练Llama2-7B模型作为初始分类器,自动预筛具有挑战性的查询。该分类器处理用户查询及其对应的LLM响应,生成二元标签以指示该查询诱导的对话中发生幻觉的可能性。
方法改进
相比于传统的基于规则或关键词分析的方法,本研究采用了更精细的特征提取方式,通过捕捉特定用户的查询特征,提高了幻觉检测的准确性。
解决的问题
本研究解决了如何构建一个具有挑战性的数据集,用于评估大型语言模型在实际场景中的表现。通过将真实用户与LLM之间的交互记录转换为具有挑战性的查询,可以更好地模拟现实世界中的应用场景,从而提高LLM的准确性和可靠性。此外,本研究还提供了五种细粒度的幻觉类型分类框架,有助于深入理解不同类型的幻觉产生的原因和机制。
论文实验
本文主要介绍了对大型语言模型(LLMs)的幻觉评价方法和实验结果。具体来说,作者提供了参考答案生成机制,并使用外部搜索引擎检索相关信息来提供更准确的回答。通过比较不同型号的LLMs在HaluEval-Wild数据集上的表现,作者得出了以下结论:
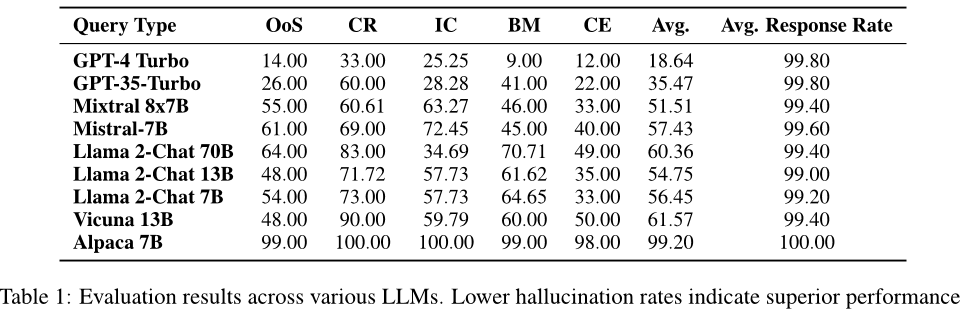
- 不同型号的LLMs在处理各种类型的查询时存在显著差异。例如,Alpaca 7B的幻觉率高达99.20%,而GPT-4 Turbo的平均幻觉率为18.64%。
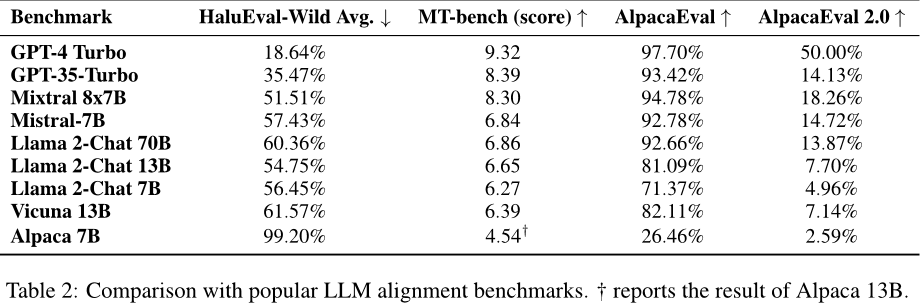
- 经过知识蒸馏的模型,如Vicuna-13B,在标准聊天机器人基准测试中表现出色,但在HaluEval-Wild上更容易产生幻觉。
- 自我反思是一种有效的幻觉缓解机制。通过对LLM进行自我反思,可以有效地减少幻觉的发生。
总的来说,本文的研究为评估和改善LLMs的表现提供了有用的工具和思路。

论文总结
文章优点
- 提出了HaluEval-Wild这一新的基准测试,用于评估在真实场景下基于大型预训练模型(LLMs)的语言生成系统的可信度。
- 使用了精心筛选的挑战性查询来衡量LLMs的能力和局限性,并且通过手动验证参考答案的方法确保了结果的准确性。
- 对各种流行的LLMs进行了全面的分析,揭示了知识蒸馏模型更容易产生幻觉的问题,这为提高这些模型的事实完整性提供了基础。
方法创新点
- 该研究提出了一个全新的基准测试,即HaluEval-Wild,以评估在真实场景下基于大型预训练模型(LLMs)的语言生成系统的可信度。
- 研究使用了精心筛选的挑战性查询来衡量LLMs的能力和局限性,并且通过手动验证参考答案的方法确保了结果的准确性。
- 该研究还对各种流行的LLMs进行了全面的分析,揭示了知识蒸馏模型更容易产生幻觉的问题,这为提高这些模型的事实完整性提供了基础。
未来展望
- 该研究提出了一些限制,例如基准测试可能无法完全代表所有用户与LLMs之间的交互以及基准测试可能受到主观判断的影响等。
- 随着LLMs的发展,需要不断更新和改进HaluEval-Wild和其他类似的基准测试,以确保它们能够准确地评估LLMs的性能和可靠性。
- 在未来的研究中,可以探索如何进一步减少LLMs产生的幻觉,从而提高其事实完整性和可信度。



















 150
150

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











