



1. 背景
检索增强生成(RAG)作为一种突破性方法论,通过整合外部知识显著提升了自然语言生成能力。该技术通过非参数学习、多源知识融合和垂直领域适配三大核心机制,使大语言模型能够基于权威实时数据生成既符合语境又准确可靠的响应,推动了自然语言处理系统的重大革新。
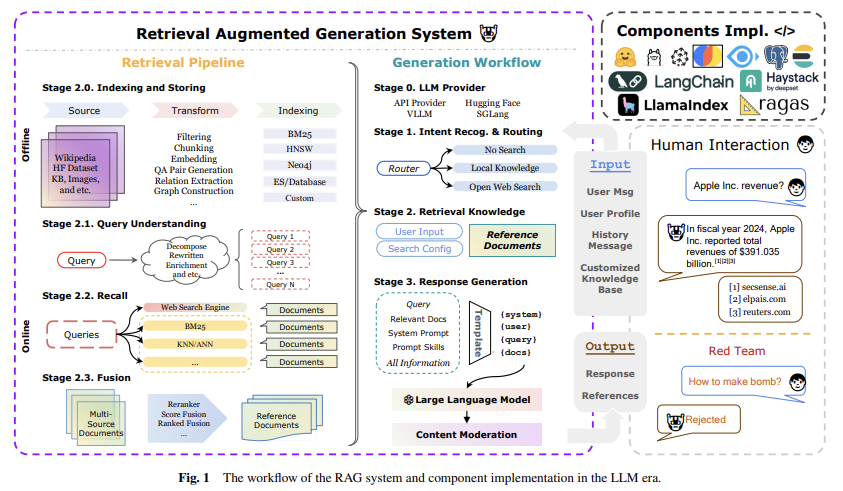
从宏观架构来看,这个融合语言模型与检索技术的复杂系统可划分为检索与生成两大模块。
- 检索模块:涵盖预处理、稠密/稀疏检索、重排序等核心操作
- 生成模块:包含检索规划、多源知识融合及逻辑推理等组件
系统还集成文档分块、向量嵌入、安全验证等上下游环节,整体效能既取决于各组件性能,更依赖于系统级的协同优化。
面对如此复杂的系统架构,如何建立兼顾整体与组件的评估体系成为关键课题。RAG 系统评估尤其面临三重挑战:
- 应用场景的广泛性
- 内部组件的异构性
- 技术迭代的动态性
三大挑战使得建立统一评估范式成为当前研究前沿。
为此,该篇综述作者系统梳理了近年来的 RAG 评估方法:
- 1)体系完整性——涵盖组件级与系统级评估;
- 2)方法多样性——包含传统统计指标与 LLM 时代的新型评估;
- 3)来源广泛性——整合结构化框架与前沿论文方法;
- 4)实践指导性——聚焦可量化指标与实际应用。
通过这种多维视角,为研究者提供评估优化 RAG 系统的完整工具箱。
2. 如何进行RAG系统的评估
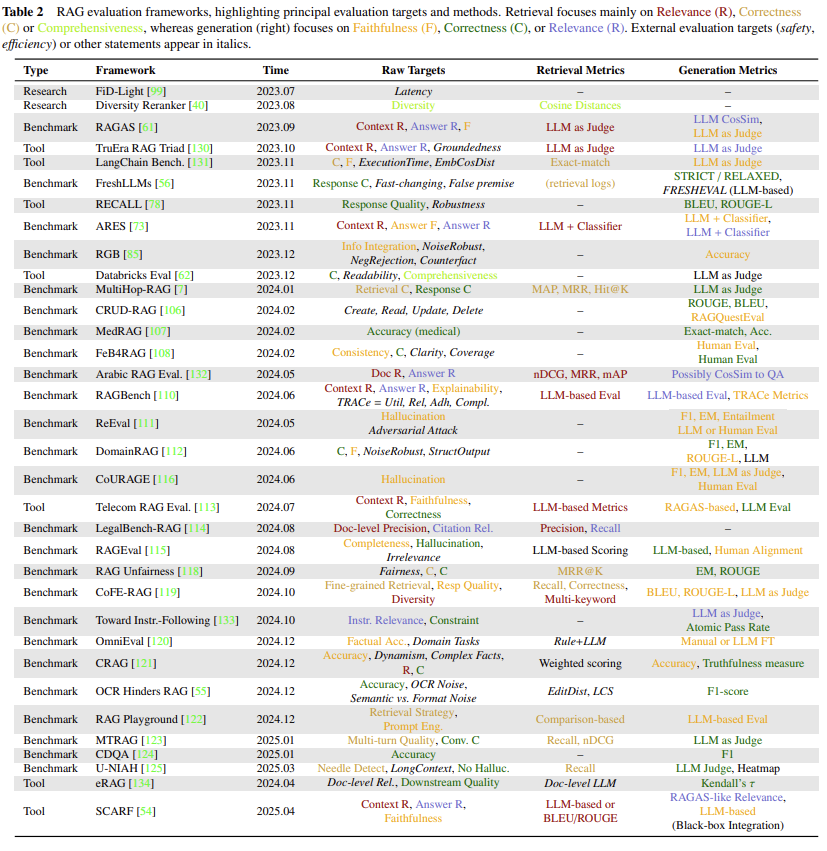
2.1 评估目标
RAG 系统的各个组件可以归结为解决两个核心问题:
- 真实信息的检索
- 生成与标准答案高度契合的响应
以上两个问题分别对应检索模块和生成模块的评估目标。

上图总结了检索组件和生成组件的评估目标。
-
检索组件:包含召回和排序两个主要阶段,二者的输出(相关文档)具有相似的评估方式。
-
- 相关性(相关文档 ↔ 查询):评估检索到的文档与查询所需信息的匹配程度,衡量检索过程的精确性和针对性。
- 全面性(相关文档 ↔ 相关文档):评估检索文档的多样性和覆盖范围,衡量系统是否全面捕捉了与主题相关的各类信息,确保检索结果能根据查询提供完整的视角。
- 准确性(相关文档 ↔ 候选文档):对比候选文档集评估检索结果的精确度,衡量系统对相关文档的识别能力,以及能否给予高相关性文档更高评分。
-
生成组件:
-
- 相关性(响应 ↔ 查询):衡量生成响应与初始查询意图及内容的契合度,确保响应内容切题且满足特定需求。
- 忠实度(响应 ↔ 相关文档):评估生成响应是否准确反映相关文档的信息,衡量生成内容与源文档的一致性。
- 正确性(响应 ↔ 示例响应):类似于检索组件的准确性指标,通过对比标准答案评估生成响应的准确度,检验响应内容的事实正确性和语境适配性。
2.2 传统评估方法
RAG 系统植根于信息检索(IR)与自然语言生成(NLG)两大传统领域,其评估体系沿袭了这两个领域的经典指标,主要从检索和生成两个维度进行评测。
2.2.1 信息检索相关指标
这类指标源自传统检索系统,根据是否考虑排序可分为两类:
-
非排序类指标:仅评估二元相关性(是否相关),不考虑项目在排序列表中的位置。
-
- 准确率/Hit@K:考察结果中真阳性与真阴性的比例
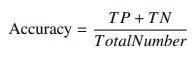
- 召回率@K:在前 k 个结果中,检索到的相关实例占全部相关实例的比例
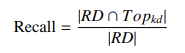
- 精确率@K:在前 k 个结果中,相关实例占检索实例的比例
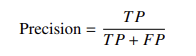
- F1分数:精确率与召回率的调和平均数

-
排序类指标:关注相关项在排序列表中的位置分布。
-
- 平均倒数排名(MRR):首个正确答案排名的倒数的平均值
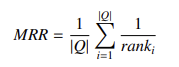
- 归一化折损累积增益(NDCG):对低位相关文档进行折损计算
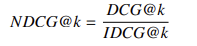
- 平均精确率(MAP):各查询平均精确率的均值
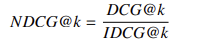
2.2.2 自然语言生成相关指标
自然语言生成相关指标着重评估文本输出的内容质量。
- 精确匹配(EM):严格比对生成答案与标准答案的完全一致性,匹配得 1 分否则 0 分。通常需对答案进行标准化预处理(如转小写、去标点等)。
- ROUGE:通过 n-gram 重叠度评估摘要质量,含 ROUGE-N(n 元语法)、ROUGE-L(最长公共子序列)等变体。
- BLEU:基于 n-gram 精确率的机器翻译评估指标,会施加简短惩罚。虽广泛使用,但无法评估文本流畅度。
- METEOR:改进版 BLEU,引入同义词匹配和词序惩罚机制:
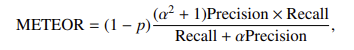
- BertScore:利用 BERT 等模型的上下文嵌入计算语义相似度,生成精确率、召回率和 F1 分数,对语义等价更敏感。
- 文本相似度:评估检索文档间的语义差异,可通过文档内相似度或文档间相似度计算:
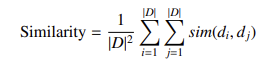
- 覆盖率:检索到的相关文档占全部相关文档的比例:
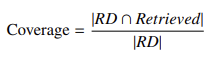
- 困惑度(PPL):衡量语言模型预测能力,基于交叉熵的指数形式:
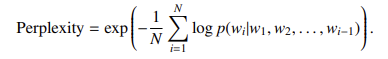
2.2.3 上游预处理评估
随着 RAG 发展,语料预处理(分块和嵌入)的评估日趋重要。
-
分块评估分为两个层面:
-
- 1)内在指标:如关键词全覆盖率(要求关键词至少出现在一个检索块中)、完整上下文所需token数等
- 2)外在指标:分析不同分块方法对下游任务检索性能的影响,如比较 ROUGE、BLEU 等指标
-
嵌入模型评估方面,MTEB 和 MMTEB 已成为行业标准。
-
- MTEB 涵盖 58 个数据集的 8 类任务,证明没有万能嵌入方案;
- MMTEB 进一步扩展至 250+语言、500+任务,新增指令遵循、长文档检索等挑战场景。
2.3 基于大语言模型的评估方法
当前研究越来越多地采用 LLM 驱动的评估指标,这些指标为不同 RAG 模块的迭代优化提供了可量化的基准。这些方法主要可分为基于输出和基于表征的两大类。
2.3.1 基于LLM输出的评估方法
通过对 LLM 生成的文本格式输出进行内容识别或统计分析,其流程简洁直观,且不受 LLM 开源/闭源属性的限制。
- 通过提示工程让 LLM 对组件输出进行显式评分。例如 RAGAS和 Databricks Eval会向 GPT 裁判发出"检查回答是否得到检索上下文支持"或"评估回答对用户查询的完整度"等指令。
- 采用小样本提示设计,利用 GPT-4 判断生成答案与标准答案的匹配程度。
- 构建多智能体 LLM 框架评估检索性能,其相关性判断比传统方法更符合人类偏好。
- 提出基于抽象语法树(AST)的方法来量化 RAG 系统中的幻觉现象,该方法能有效监测外部 API 调用的准确性。这些方法通常受益于思维链推理技术。
新的统计指标:
- 语义困惑度(SePer)指标,通过聚类实体目标捕捉 LLM 对生成答案正确性的内部置信度。给定查询 q 和参考答案 a*,其计算公式为:
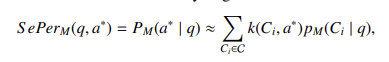
- KPR(关键点提取): 量化 LLM 将检索文档关键点融入回答的程度:
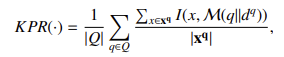
- 相对胜率比(MRWR/MRLR)指标:给定 M 个检索器在 N 个问答样本上的表现,首先计算各检索器在样本上的正确性标识 I^m(n),继而定义检索器 r*i 相对于 r_j 的相对胜率:
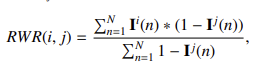
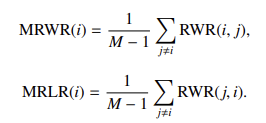
MRWR 和 MRLR 则分别通过对行列方向取平均获得。
- FactScore 通过将生成内容分解为原子事实来验证其与知识源的匹配度。进一步考虑同义表达,提出进阶版 D-FActScore。其核心公式分别为:

-
从风险管控角度提出四维评估体系:
-
- 风险度:保留样本中风险案例占比
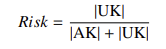
- 谨慎度:对不可答样本的识别率
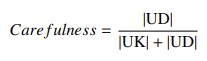
- 对齐度:系统判断与标注的一致性
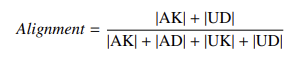
- 覆盖率:样本保留比例
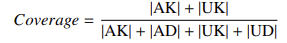
2.3.2 基于 LLM 表征的评估方法
通过建模 LLM 中间层或最终层的向量表征来获取评估指标,其优势在于能减轻对表面词汇模式的过度依赖,但可能因数值相似度与事实正确性的非必然关联而损失可解释性。
- GPTScore:基于 BertScore 思想构建 LLM 评分体系;
- ARES:结合分类器与 LLM 嵌入来验证生成答案与证据的语义对齐
- RAGAS:采用余弦相似度衡量答案相关性。
- Thrust:通过分析 LLM 隐藏状态下的样本聚类效果来评估知识掌握程度:
- 信息瓶颈理论引入检索组件评估
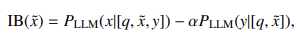
- 基于 METEOR 提出 GECE 指标量化生成文本的长尾特性:
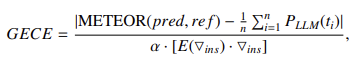
- 外部语境评分 ε 通过注意力机制量化知识利用程度:

3. 外部评估方法
将外部效用归纳为两大领域:安全性与效率,其具体评估方法如下所述。
3.1 安全评估
安全性能关乎 RAG 系统在动态、嘈杂甚至危险环境中生成稳定无害内容的能力。随着 RAG 系统广泛应用,其安全隐患已超越独立大语言模型。外部知识源的引入带来了独特漏洞,需要专门评估框架。
-
【鲁棒性】评估聚焦系统处理误导性检索结果时的表现。
-
- RECALL 通过 BLEU、ROUGE-L 和误导率等指标测试系统区分可靠与虚假知识的能力。
- SafeRAG针对"上下文冲突"等挑战设计专项指标
- C-RAG 则通过保形风险分析和 ROUGE-L 提供理论风险保障。
- 韧性率——衡量检索增强前后系统保持响应准确的比例,体现稳定性;
- 提升率——统计初始错误答案经检索文档修正的比例,评估 RAG 实效性。
-
【事实性】确保生成信息准确,避免看似合理实则错误的陈述(幻觉),尤其在检索结果存在噪声或冲突时。核心指标包括:
-
- 事实准确率(在误导性语境下采用 EM/F1 等标准 QA 指标)
- 幻觉率(生成内容与检索文档矛盾的比例,常用 LLM 评判或人工评估)
- 引证准确度(通过引证精确率/召回率评估来源标注)
- 忠实度指标(衡量输出与检索信息的吻合程度)
-
【对抗攻击】针对 RAG 流程特定环节:
-
- 知识库投毒(Poisoned RAG)通过注入恶意文本诱导预设输出,采用攻击成功率(ASR)及检索精度/召回率评估;
- 检索劫持(HijackRAG)操纵排序算法优先返回恶意内容,重点评估跨模型攻击迁移能力;
- 幻影攻击通过检索失败率(Ret-FR)评估触发文档效果;
- 阻塞攻击则插入强制拒答的"拦截"文档,采用预言指标评估。
-
【隐私性】评估检索库或用户查询的信息泄露风险,通过模拟攻击测试。关键指标包括:
-
- 提取成功率(从知识库获取特定隐私信息的频次)
- PII 泄露率(生成输出中个人身份信息暴露比例)
- 成员推断攻击成功率(判断特定数据是否存在于知识库的能力)
-
【公平性】检测系统是否放大检索文档或训练数据中的偏见。
-
- 偏见指标量化不同人群的性能差异(如错误率、情感分数);
- 刻板印象检测统计有害陈规的出现频率;
- 反事实公平性检验敏感属性变更时输出的合理性变化。
-
【透明度/问责性】评估系统推理过程的可理解性与可追溯性,采用定性化指标:
-
- 解释质量(人工评估说明信息的清晰度与完整性)
- 可追溯性(输出与源文档的关联便捷度)
- 引证准确率(精确率/召回率)。
3.2 效率评估
效率是 RAG 实用性的另一关键维度,直接关系到系统普及度、成本效益与实际价值。
-
延迟评估通常关注两大核心指标:
-
- 首词响应时间(TTFT)衡量系统接收查询后生成首个输出词元所需时长,这对用户体验至关重要——它直接决定了用户感知的响应速度。在需要即时反馈的交互式应用中尤为关键。
- 完整响应时间(总延迟)则统计从提交查询到生成完整响应的全过程耗时,涵盖检索时长、处理时长及所有词元的生成时长。
-
资源与资金成本评估是衡量 RAG 效率的另一核心要素。成本评估方法通常聚焦于量化直接影响系统经济性的直接支出与效率指标。RAG 系统的总成本可分为以下关键组成部分:
-
- 基础设施成本:本地计算资源(用于嵌入生成、向量数据库维护)及开源模型的 LLM 推理开销
- 按量计费成本:基于输入输出词元使用量的外部 LLM 服务 API 费用
- 存储成本:随语料库规模增长的向量数据库托管与维护支出
- 运维开销:人工监管、系统维护及知识库定期更新
- 开发成本:系统初建、集成与定制化费用
如何零基础入门 / 学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。


















 6413
6413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









