







 超级会员免费看
超级会员免费看
K-means
1、算法概述
K-means 是一种经典的无监督学习聚类算法,由 Stuart Lloyd 在1957年提出。它通过迭代的方式将数据集划分为 K 个簇,使得每个数据点都属于离它最近的簇中心(质心)对应的簇。
2、算法原理
K-means 的核心思想是最小化簇内平方和(Within-Cluster Sum of Squares, WCSS),即让每个簇内的数据点尽可能紧凑,簇间的数据点尽可能分离。
3、基本概念
- K值:预设的聚类数量
- 质心(Centroid):每个簇的中心点
- 距离度量:通常使用欧几里得距离
4、算法步骤
- 初始化:随机选择 K 个数据点作为初始质心
- 分配阶段:将每个数据点分配到最近的质心所在的簇
- 更新阶段:重新计算每个簇的质心
- 迭代:重复步骤2-3,直到质心不再显著变化或达到最大迭代次数
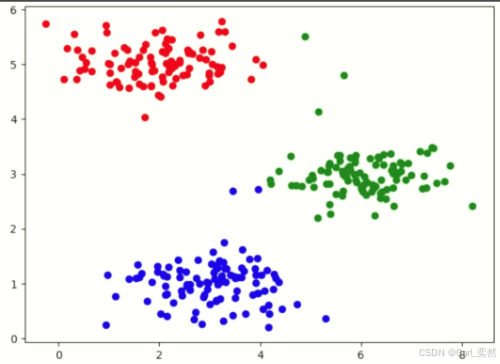
5、数学公式
5.1 目标函数

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 437
437

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











