 2026大模型应用架构全景
2026大模型应用架构全景







1、引言
小屌丝:鱼哥,你这又是干啥嘞?
小鱼:哦,这是在看看国际局势
小屌丝:如果如我所想,
小鱼:你想的是啥,跟我想的不一样。
小屌丝:… 我怀疑你不正经…
小鱼:我还没说你,你竟然先怀疑我?
小屌丝:我有证据.
小鱼:行啊, 你怀疑,你举证
小屌丝:你看

小鱼:你这… 我看的不是
小屌丝:那你说,你看的是啥?
小鱼:这个啊

小屌丝:哇噻~ 鱼哥, 你给俺介绍介绍呗
小鱼:有啥可介绍的, 天天这点东西,
小屌丝:不一样,不一样, 现在你一定会给俺讲一些不一样的内容。
小鱼:我不抽烟,也不喝酒
小屌丝:小艺,导航到老地方,洗澡
2、AI大模型应用架构全景图
关于AI大模型,小鱼写过:
这里就不一一例举了, 如果想看更多的内容,可以进入到大模型专栏,搜索你想看的技术文章。
咱闲言少叙,进入到今天的专题,了解不一样的AI大模型应用架构。
2.1 核心层次
现在大部分企业都在基于AI大模型做事情,所以,针对大模型的核心层次,你不得不知道4个核心层,基础架构层、数据与知识层、智能体与编排层和应用层,详细如下:
-
基础架构层:
- 作为整个系统的技术底座,负责提供算力支持、模型管理和基础服务。
- 这一层主要包括高性能GPU集群、模型服务框架(如vLLM、TGI)、云原生基础设施(Kubernetes、Docker)以及监控评估系统。
-
数据与知识层:
- 承担企业知识的提取、存储和检索功能。该层通过多源数据接入网关处理文本、音频、视频、图片等异构数据,经由ASR(自动语音识别)、OCR(光学字符识别)和NLP处理管道转化为结构化信息。
- 知识存储则采用向量数据库(如Milvus、Chroma)与图数据库(如Neo4j)混合架构,兼顾语义搜索和关系推理能力。
-
智能体与编排层(模型层):
- 是AI应用的"大脑",负责任务分解、工具调用和流程控制。
- 该层基于LangChain、ModelStudio-ADK等框架,通过ReAct(推理+行动)模式让模型具备使用外部工具的能力。
- 智能体根据复杂度可分为L1-L5多个等级,从简单的响应型到完全自治型,满足不同场景的自动化需求。
-
应用层:
- 直接面向最终用户和业务系统,通过API、聊天界面或集成到现有应用的方式提供服务。
- 这一层需要针对不同行业场景设计专用解决方案,如制造业的质检系统、金融领域的风控引擎和内容创作的视频生成工具。

2.2 核心技术
2.2.1 基础开发框架
-
下层:深度学习基础框架
- PyTorch 2.3+:作为主流框架,支持动态计算图与分布式训练优化,新增的torch.compile 3.0显著提升推理效率
- TensorFlow 2.15+:强化了对JAX的兼容性,提供更高效的模型部署工具链
- JAX 0.4.15+:专为高性能计算优化,支持自动并行化与设备无关计算
-
上层:AI Agent开发框架
- LangGraph 1.2+:基于LangChain的图式工作流编排,支持复杂任务的动态流程管理
- AutoGen 2.0+:提供多智能体对话与协作能力,支持基于规则的智能体交互
- CrewAI 1.5+:专注于团队协作式智能体,适用于企业级工作流自动化

2.2.2 模型训练与微调技术
-
参数高效微调(PEFT)的革命性进展
- LoRA 3.0+:支持多层参数适配,微调效率提升40%
- QLoRA 2.5+:量化与LoRA结合,显存占用降低50%,支持70B+模型在消费级GPU上微调
- Adapter Tuning 2.0:基于神经网络结构的适配器设计,微调效果提升15%
-
分布式训练优化
- ZeRO-4+:内存优化技术,支持1000+ GPU的高效分布式训练
- FSDP 3.0:参数分片策略,训练吞吐量提升35%
- 梯度检查点优化:内存占用降低60%,训练速度提升25%
2.2.3 模型训练与微调技术
-
高性能推理框架
- vLLM 0.3.0+:引入PagedAttention 3.0,吞吐量提升50%,支持100+并发请求
- TensorRT-LLM 2.1+:支持混合精度推理,推理延迟降低40%
- FlashAttention-3:内存效率提升50%,支持超长上下文处理
-
推理优化技术
- 模型量化:INT8/INT4量化,模型体积缩小60%,推理速度提升2.5倍
- 算子融合:关键计算路径融合,减少GPU指令调度开销
- 动态批处理:根据请求特征自动调整批处理大小,资源利用率提升30%
2.2.4. AI编程辅助工具
- GitHub Copilot X:支持代码理解、调试、文档生成,开发效率提升35%
- 通义灵码 3.0+:深度集成国产开发环境,支持中文场景下的智能编码
- CodeLlama 3.0+:开源模型,支持多语言代码生成,本地部署成本降低70%
- …

2.3 应用架构设计模式
2.3.1 RAG架构设计
RAG (Retrieval-Augmented Generation) 2025年已从基础检索增强演进为多层知识增强架构:
- 多源知识库:支持结构化数据库、非结构化文档、API接口等多源知识接入
- 向量化检索优化:使用DPR+FAISS 3.0,检索准确率提升25%
- 上下文感知增强:基于用户历史交互动态调整检索策略
- 实时知识更新:支持知识库的增量更新与版本管理

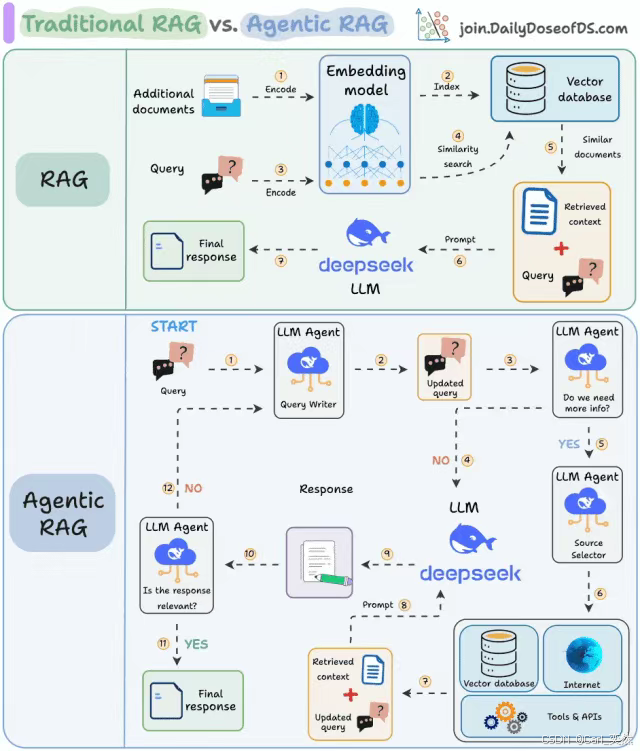
2.3.2 Agentic RAG架构
Agentic RAG 2025年已实现从"被动检索"到"主动决策"的跨越:
- 智能体决策层:基于ReAct架构,实现问题分解、工具调用、结果验证的完整闭环
- 多轮对话管理:支持上下文感知的对话历史管理,对话连贯性提升40%
- 动态知识检索:根据任务需求自动调整检索策略,减少无效检索
- 结果验证机制:对生成内容进行事实性验证,降低幻觉率
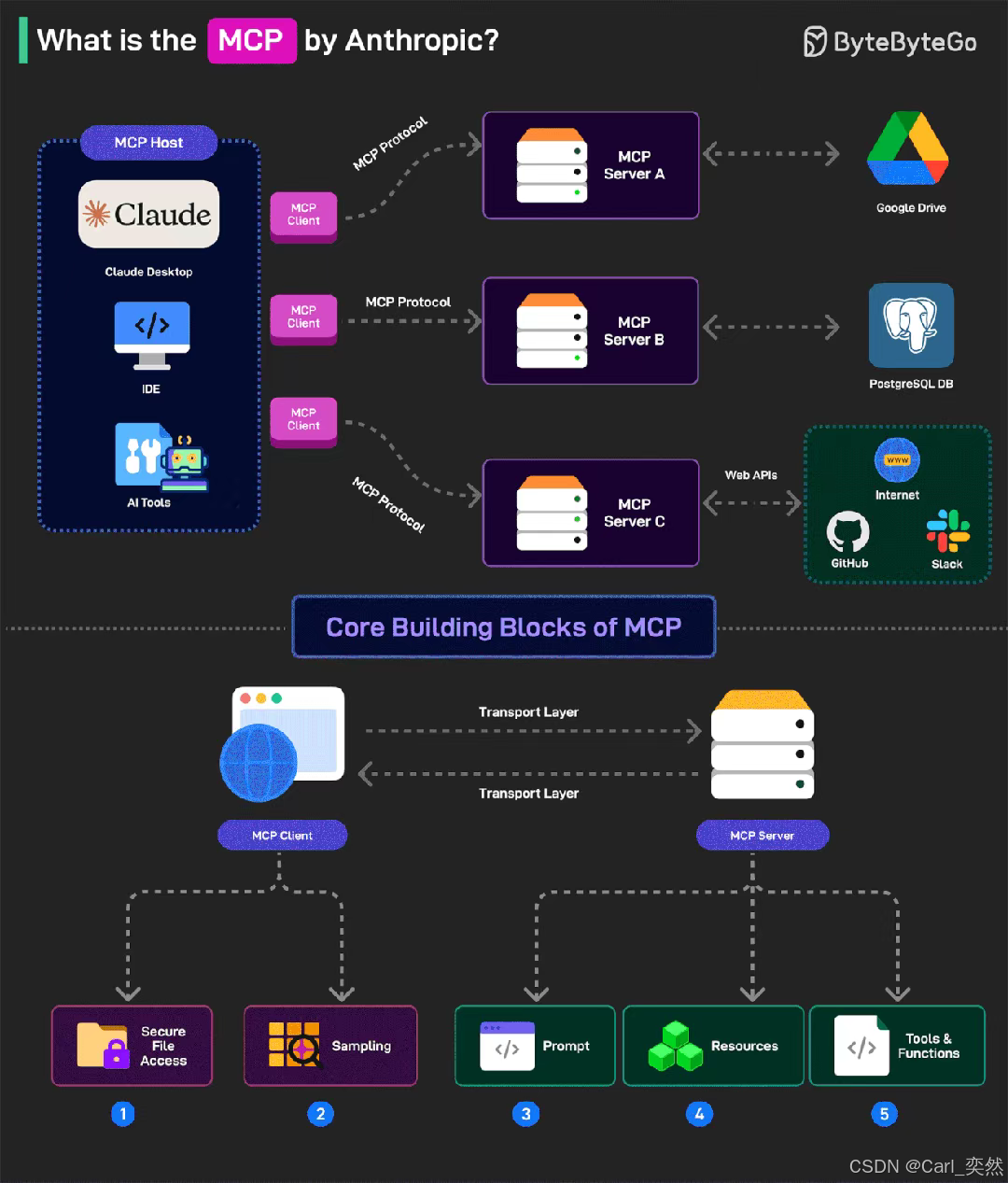
2.3.3 MCP模型上下文协议:统一上下文管理
MCP (Model Context Protocol) 2025年已成为大模型应用的统一上下文管理标准:
- 上下文结构化:将用户输入、历史对话、系统状态等统一为结构化数据
- 动态上下文压缩:基于重要性评估,自动压缩长上下文,保持关键信息
- 多模态上下文支持:同时处理文本、图像、音频等多种模态的上下文
- 上下文版本管理:支持上下文的版本控制与回溯
2.3.4 Function Calling架构:能力扩展的关键
Function Calling 2025年已从简单的API调用演进为能力扩展的核心机制:
- 函数注册与发现:支持动态注册和发现可调用函数
- 参数自动验证:对输入参数进行自动验证,防止错误调用
- 执行结果处理:对API返回结果进行结构化处理,便于后续使用
- 错误处理与重试:提供完善的错误处理机制,确保调用可靠性
2.3.5 A2A Agents架构:智能体间的协同
A2A (Agent-to-Agent) 架构2025年已实现智能体间的高效协同:
- 智能体注册中心:统一管理可调用智能体及其能力
- 任务分发与调度:基于任务需求自动分配合适的智能体
- 状态同步机制:确保智能体间状态的一致性
- 协作模式配置:支持多种协作模式(如流水线、并行、混合)
2.3.6 AG-UI前端交互架构:用户界面的智能化
AG-UI (Agent-Guided UI) 2025年已实现从"静态界面"到"智能交互"的转变:
- 意图识别:基于用户输入自动识别意图,提供相应交互
- 动态界面生成:根据任务需求动态生成交互界面
- 上下文感知提示:基于当前上下文提供智能提示
- 多模态交互支持:支持文本、语音、图像等多种交互方式
2.3.7 Fine-tuning微调架构:定制化模型的核心
Fine-tuning架构2025年已实现从"简单微调"到"全流程管理"的升级:
- 数据准备与标注:支持自动化数据标注与质量评估
- 微调策略配置:提供多种微调策略(如LoRA、Adapter)的配置界面
- 训练监控与分析:实时监控训练过程,提供性能分析
- 模型版本管理:支持模型版本的存储、对比与回滚
2.3.8 ANP架构设计:应用导航协议
ANP (Application Navigation Protocol) 2025年已成为应用导航的核心标准:
- 应用结构定义:定义应用的模块、功能与交互关系
- 导航策略配置:基于用户行为自动调整导航策略
- 上下文感知导航:根据当前上下文提供智能导航建议
- 多端一致性:确保不同终端上的导航体验一致

2.3.9 Context Engineering上下文工程架构
Context Engineering 2025年已成为提升模型效果的关键技术:
- 上下文模板管理:提供可复用的上下文模板
- 动态上下文优化:根据任务需求自动优化上下文结构
- 敏感信息过滤:自动过滤敏感信息,保护数据安全
- 上下文效果评估:对不同上下文设置的效果进行评估
2.3.10 LLM OS大模型操作系统架构
LLM OS 2025年已从"概念"演进为"实际操作系统":
- 任务调度引擎:智能调度大模型任务,优化资源利用
- 应用商店:提供丰富的AI应用,支持一键安装
- 系统级API:提供统一的API接口,方便应用集成
- 安全沙箱:为每个应用提供独立的运行环境,确保安全
2.3.11 ChatBI(Text2SQL)企业级架构
ChatBI 2025年已实现从"简单查询"到"智能决策支持"的跨越:
- 自然语言解析:将自然语言问题转化为结构化查询
- 多源数据集成:支持多种数据源的无缝接入
- 智能分析建议:基于数据提供分析建议
- 可视化展示:自动生成图表,直观呈现分析结果
2.4 模型层:大模型开发与优化的核心流程
- 自然语言处理(NLP)引擎:
- 技术栈: 最新语言模型(如GPT-5、 Gemini)+ 专属NLP工具链。
- 核心模块:
- 关键词提取: 用GPT-5 +关键词抽取API(如Zephyr)精准识别主题词。
- 语料提取: 结合Web爬虫(Puppeteer)+ 大模型去重清洗构建高质量语料库。
- 文本分割/语义解析/主题分析: 用大模型的文本理解能力自动完成文档分段、意图识别与主题聚类。
- 数据集构建:
- 技术栈: 生成式AI + 传统标注工具(如Label Studio)。
- 数据类型:
- 词性标注数据集: 用**Transformer分词模型(如Youtokentome v3)**自动生成标注。
- 知识图谱数据集: 通过大模型自动生成RDF三元组(如“<周杰伦> <职业> <歌手>”)。
- 数据标注:
- 技术栈: 自动化标注为主,人工校验为辅。
- 标注类型:
- 实体/属性/关系/事件标注: 用GPT-5 + Few-shot Learning生成候选标注,人工仅需校验异常项,效率提升10倍以上。
- 模型开发:
- 技术栈: 分布式训练框架(PyTorch 2.5 + Fairscale)+ MLOps平台(Kubeflow 2.0、SageMaker Studio)。
- 开发流程:
- 模型训练: 支持万亿参数模型分布式训练,采用4-bit量化与ZeRO-3优化降低显存占用。
- 模型验证: 用自动化ML工具(AutoGluon) 自动调参,结合SHAP/LIME可解释AI技术分析模型决策逻辑。
- 模型部署: 容器化(Docker 25)+ Serverless(Knative)部署,支持弹性伸缩与灰度发布,推理延迟降至毫秒级。
3、总结
看到这里,关于AI 大模型的全景英语架构图就讲到这里了。
我们从数据到知识、从模型到应用的全链路智能化:
- 数据层: 多模态统一表示 + 自动化预处理。
- 知识层: 动态知识图谱 + 大模型驱动的知识抽取与融合。
- 模型层: 分布式高效训练 + 自动化MLOps + 弹性部署。
- 管理层: 向量+图数据库混合存储 + 可解释知识计算。
- 应用层: 全场景智能交互 + 多模态深度理解。
随着AI的持续布局, 作为IT人员,不得不掌握的技能:AI大模型。
我是小鱼:
- 优快云 博客专家;
- AIGC MVP技术专家;
- 阿里云 专家博主;
- 51CTO博客专家;
- 企业认证金牌面试官;
- 多个名企认证&特邀讲师等;
- 名企签约职场面试培训、职场规划师;
- 多个国内主流技术社区的认证专家博主;
- 多款主流产品(阿里云等)评测一等奖获得者;
关注小鱼,学习【机器视觉与目标检测】 和【人工智能与大模型】最新最全的领域知识。


















 981
981

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











