






EfficientNetV2训练速度快,是由于引入Fused-MBConv模块,引入了渐进式学习策略
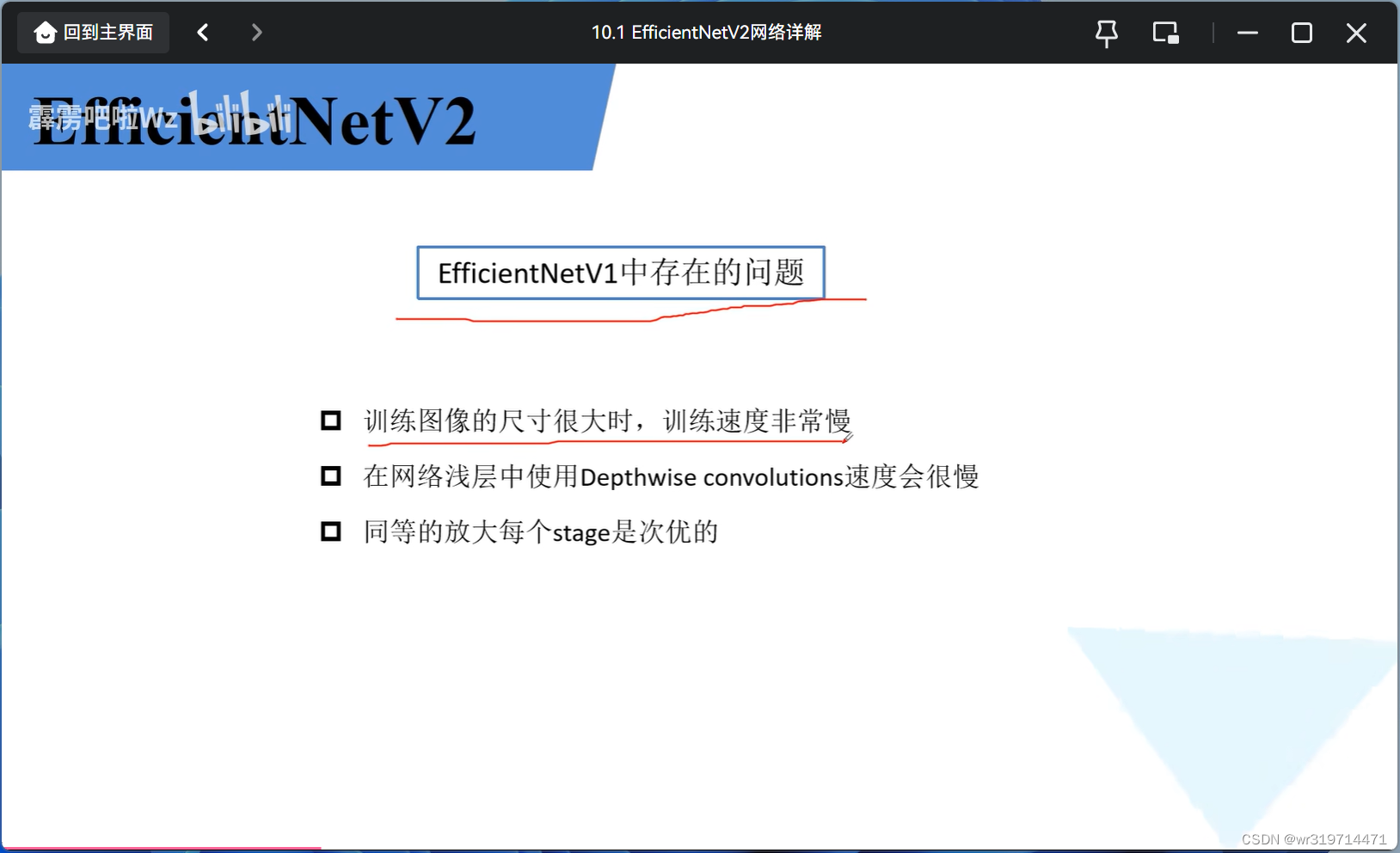
1.EfficientNetv1中存在的问题


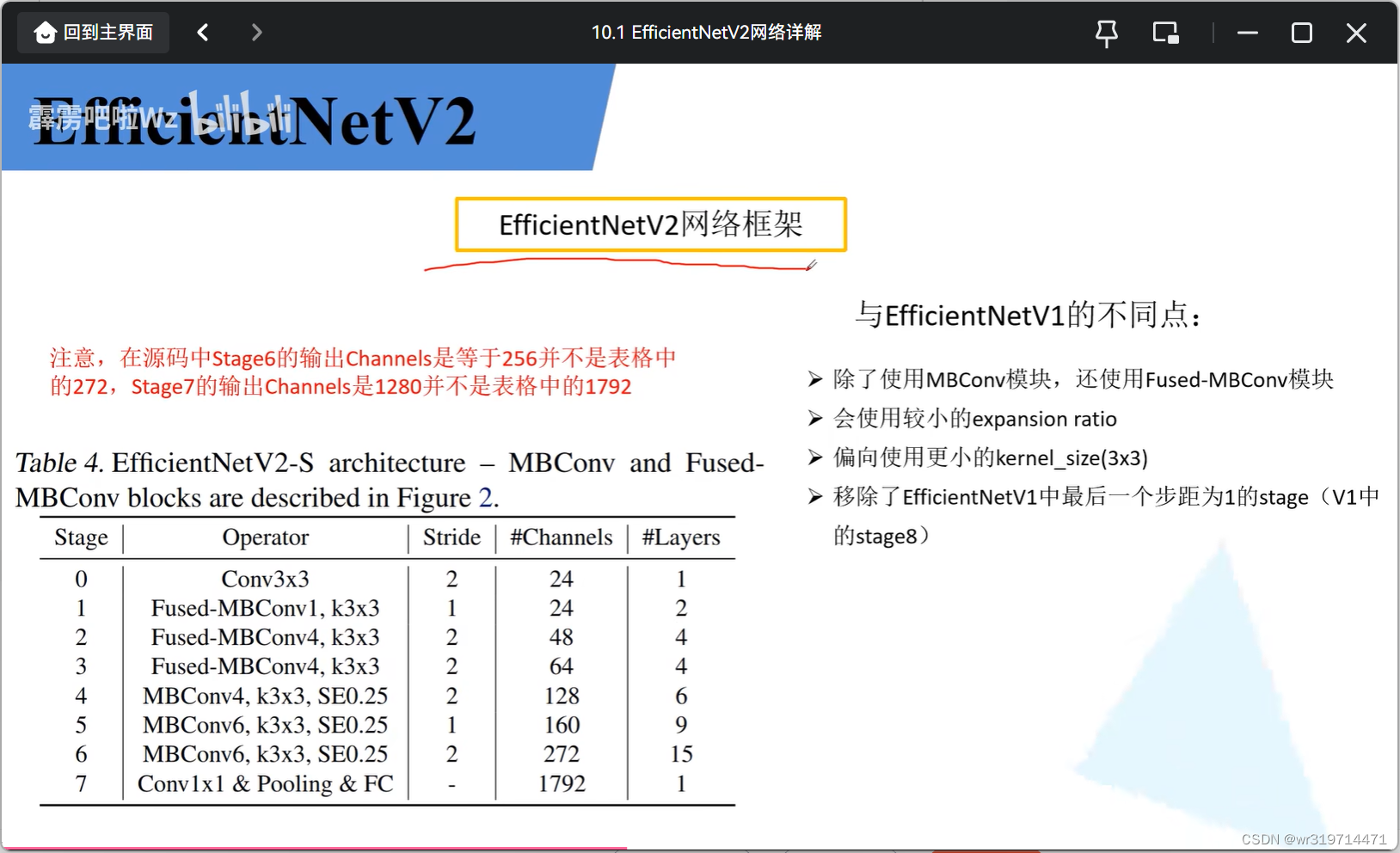
并不是将所有的MBconv都替换成·Fused MBConv模块,而是将网络的一些浅层MB替换成Fused MB(stage1到3)
2. v2的贡献

这里的正则方法包括 dropout ,rand augment ,mixup
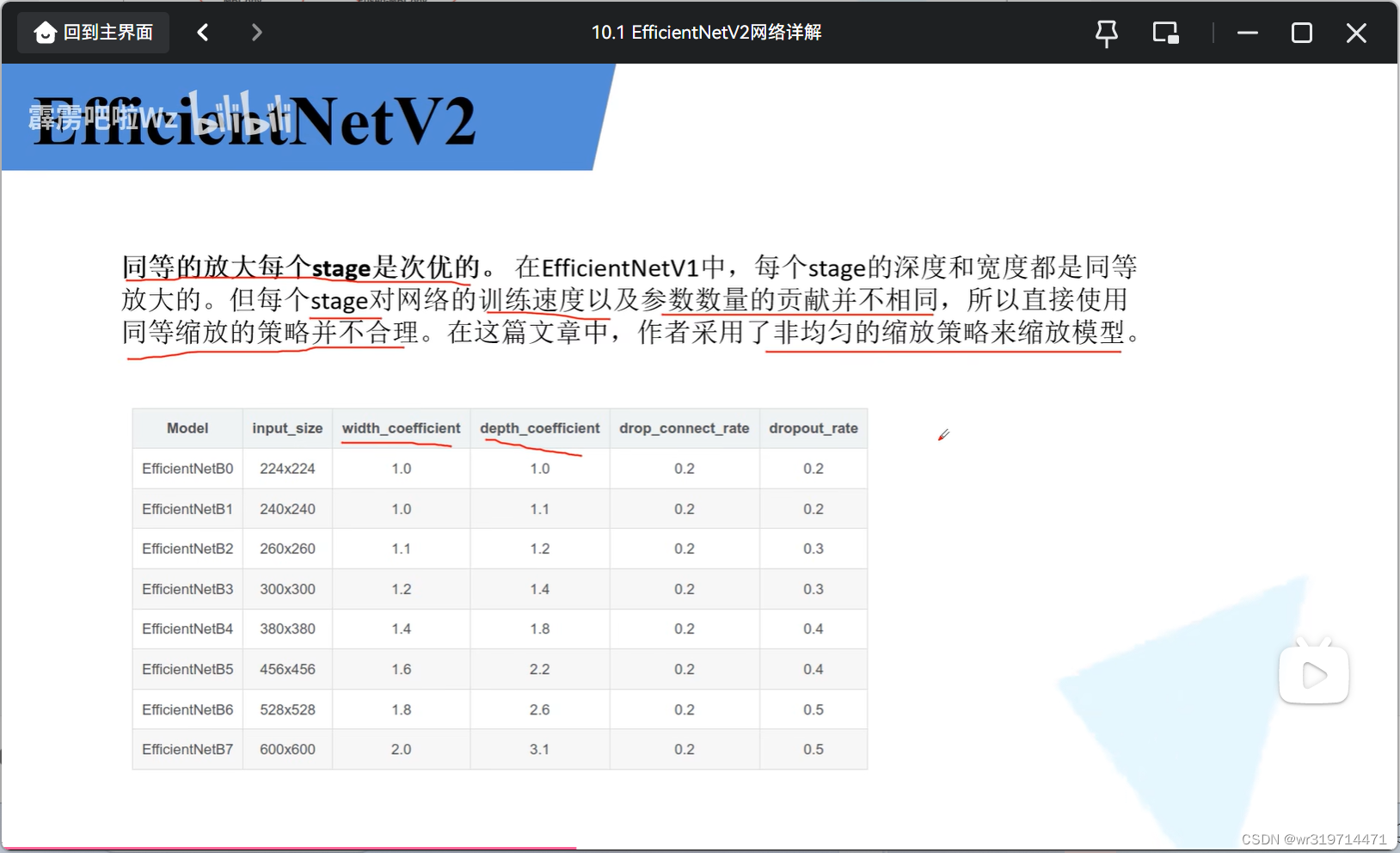
3. V2-s的架构
stage的卷积后跟有bn和silu激活函数
conv1中的1是主分支上第一个卷积层的扩展因子,k3*3是卷积核大小
se代表使用se结构,0.25代表se中第一个全连接层的节点个数是输入MB模块的特征矩阵的0.25
stride对应每个stage中的第一个operator,其他均为1
4.Fused MBConv
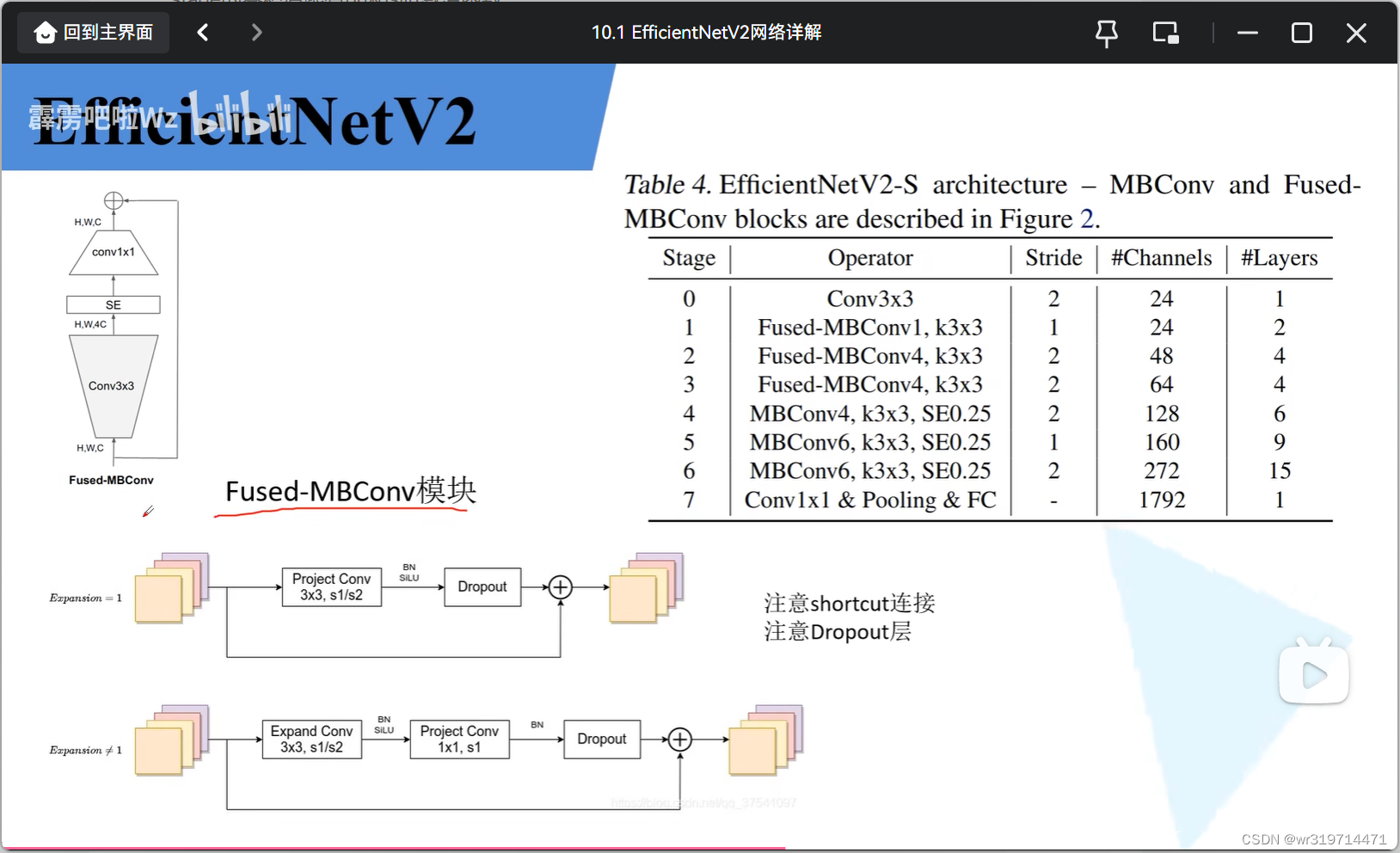
图中有se模块,但在实际搭建过程中没有(没有可能能好)
扩展因子等于1和不等于1的结构是不同的(等于1时不需要扩展,所以就少了一个卷积层)
输入特征矩阵的shape和主分支上输出特征矩阵的shape相同时才有捷径分支
有捷径分支时才有dropout层
##这里的dropout有所不同(不是以随机比例失活一定的神经元)

正向传播过程中将输入通过了一个一个block,这里每个block都可以认为是残差结构(主分支上通过f得到输出,捷径分支就是输入直接引到输出),会以一定的概率对主分支上的输出进行丢弃(整个主分支丢弃),也就相当于没有这一层,也就相当于网络是一个随机的深度了,存活概率是从1到0.5
这里的dropout层仅指FusedBM和BM中的,不包括最后一个全连接层前面的那个
参数(m和l比s多一个stage)

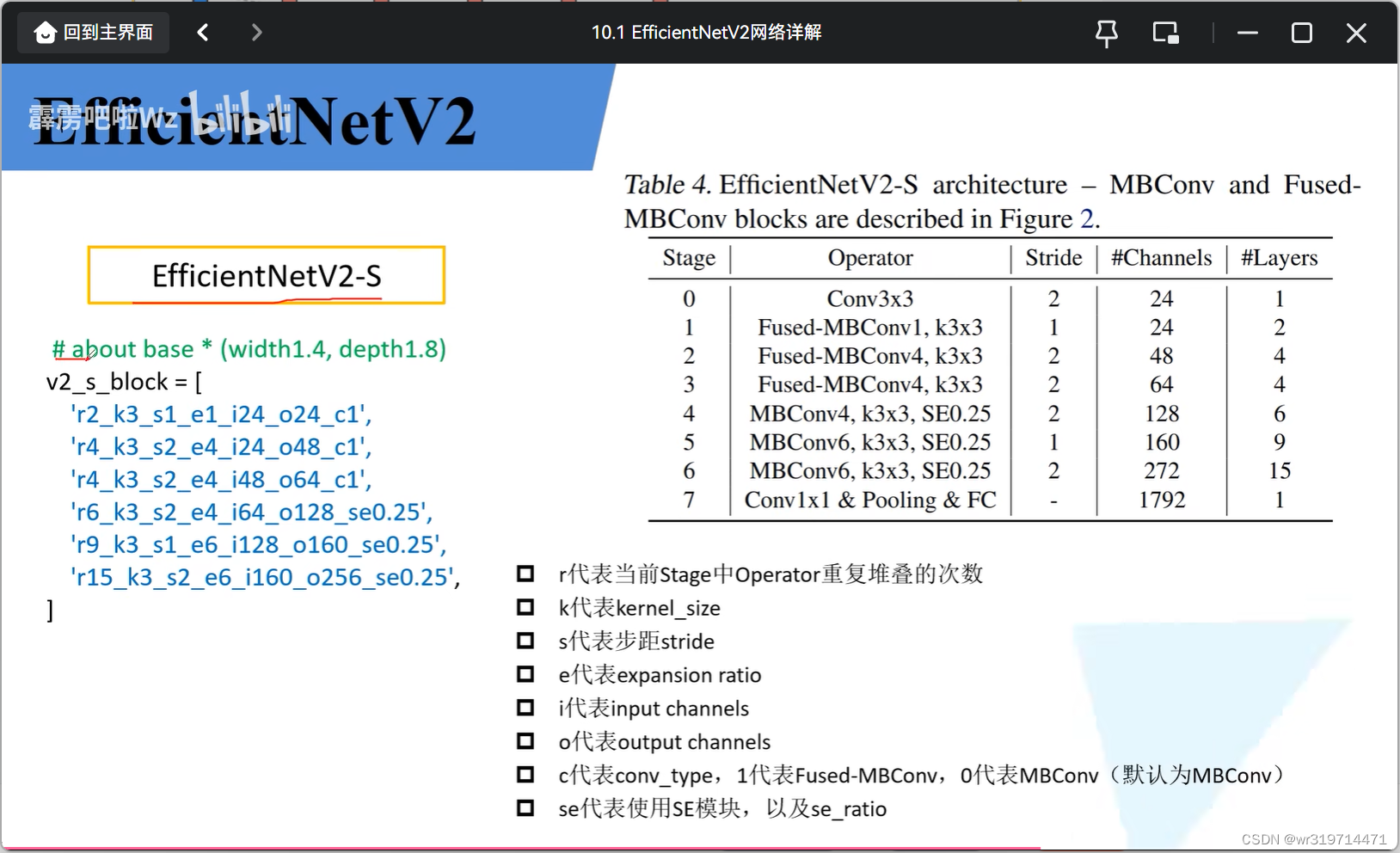


v2s是在baseline的基础上得到的,大概是width1.4,depth1.8 但这是不均匀缩放的,具体不知道
5.EfficientNetv2其他训练参数
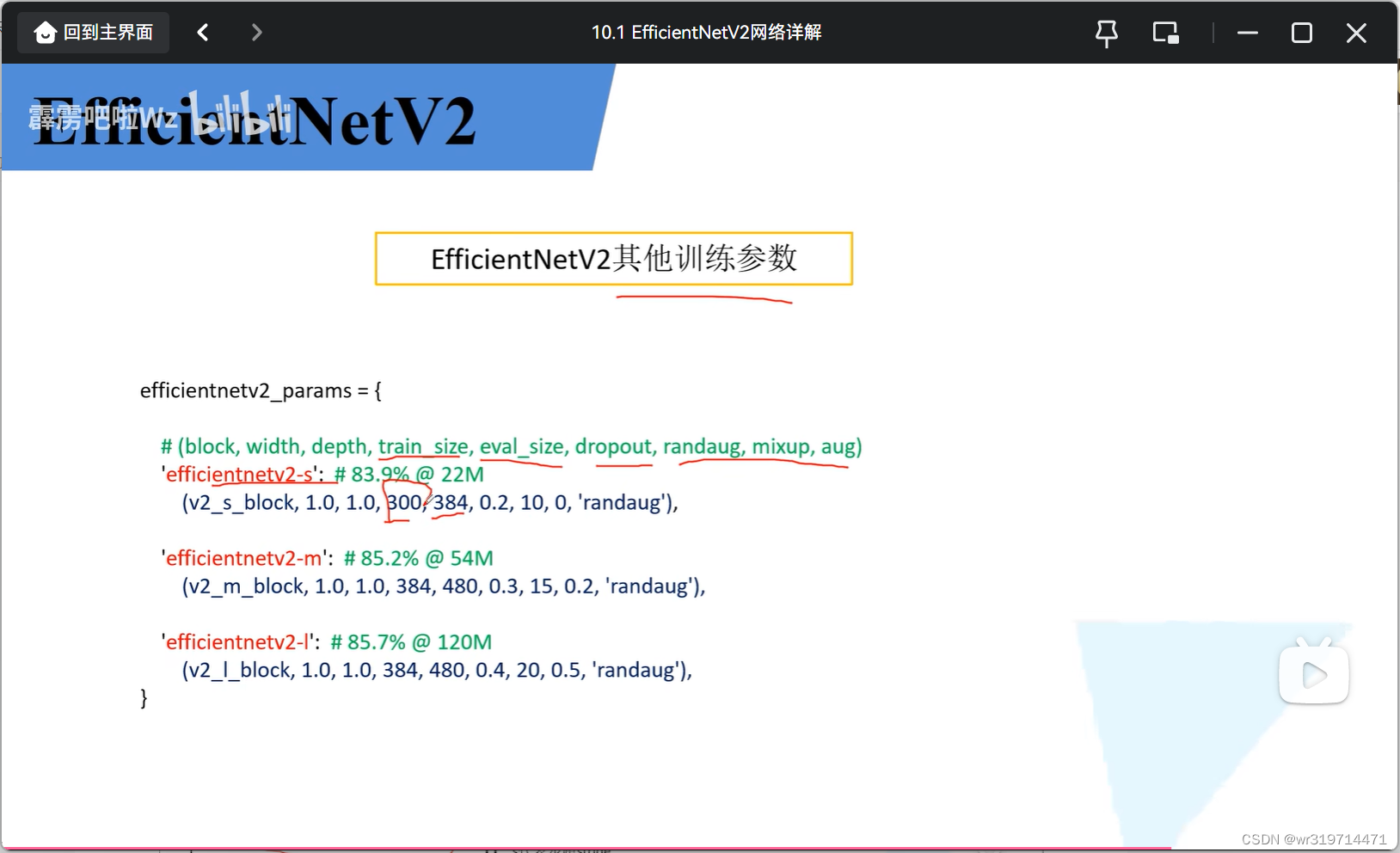
trans_size 是300,是指训练过程中最大训练尺寸(但是由于采用了渐进式的学习策略,所以他的训练尺寸是会变的,最大不会超过300)
eval_size是384 验证的时候直接采用384*384大小的
dropout的0.2对应的是全局平均池化和fc之间的
最后三个数据是渐进式学习策略时使用到的超参数

在使用不同的训练图像尺寸时要使用不同强度的正则化方法
epoch小时,图像小,正则化方法弱
随着epoch增大,图像更大,正则化方法更强


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









