




 本文详细介绍了在Ubuntu系统中安装和配置TensorRT、CUDA和CUDNN的步骤,包括关闭Xserver、卸载旧驱动、安装新驱动、更新Docker、下载CUDA安装包、配置CUDA环境变量、安装cudnn以及验证各个组件的过程。此外,还提到了TensorRT的加速技术以及与CUDA和CUDNN的关系,适合于NVIDIA GPU平台上的深度学习模型推理优化。
本文详细介绍了在Ubuntu系统中安装和配置TensorRT、CUDA和CUDNN的步骤,包括关闭Xserver、卸载旧驱动、安装新驱动、更新Docker、下载CUDA安装包、配置CUDA环境变量、安装cudnn以及验证各个组件的过程。此外,还提到了TensorRT的加速技术以及与CUDA和CUDNN的关系,适合于NVIDIA GPU平台上的深度学习模型推理优化。
文章目录
导读
TensorRT是可以在NVIDIA各种GPU硬件平台下运行的一个模型推理框架,支持C++和Python推理。即我们利用Pytorch,Tensorflow或者其它框架训练好的模型,可以转化为TensorRT的格式,然后利用TensorRT推理引擎去运行该模型,从而提升这个模型在NVIDIA-GPU上运行的速度。
CUDA,CUDNN和TensoRT的关系:
- cuda是NVIDIA推出的用于自家GPU进行并行计算的框架,用户可通过cuda的API调度GPU进行加速计算(只有当要解决的计算问题是可以大量并行计算时才能发挥cuda的作用)
- cudnn是NVIDIA推出的用于自家GPU进行神经网络训练和推理的加速库,用户可通过cudnn的API搭建神经网络并进行推理,cudnn则会将神经网络的计算进行优化,再通过cuda调用gpu进行运算,从而实现神经网络的加速(当然你也可以直接使用cuda搭建神经网络模型,而不通过cudnn,但运算效率会低很多)
- tensorrt其实跟cudnn有点类似,也是NVIDIA推出的针对自家GPU进行模型推理的加速库,只不过它不支持训练,只支持模型推理。相比于cudnn,tensorrt在执行模型推理时可以做到更快。
TensorRT主要通过下面两种技术来加速模型运行速度:
- tensorrt对网络结构进行了重构,将一些能合并的运算进行了合并(比如conv,bn,relu算子进行合并运算),且针对gpu的特性做了优化。对于cudnn来说,执行完conv,bn和relu三个操作可能需要调用三次cudnn对应的api进行计算,耗时比较长;但tensorrt则将三个操作进行了重构合并,进一步减少了推理时间
- 我们在模型训练的时候,通常采用float32数据进行训练,当模型训练完毕,其实无需使用float32这么高的精度进行推理。tensorrt则可以执行float16和int8执行推理,基本上几行代码搞定;但cudnn执行float16推理则相对要写比较多代码,也比较复杂
本文以TensorRT7.2.3.4为例。
Environment
- 硬件环境:CPU:英特尔X86处理器 GPU:GeForce 2080Ti
- 软件环境:Ubuntu16.04/Ubuntu18.04
- 虚拟环境:Docker 19.03以上版本
NVIDIA Driver
参考TensorRT7.2.3安装准备,TensorRT7最低需要CUDA10.2以上版本,所以要求你的驱动所支持的CUDA最高版本要不低于10.2,参考CUDA文档。
宿主机下
准备工作可参考linux下适配nvidia驱动,这里归纳如下
1. 关闭X server
安装驱动和CUDA包均需要关闭使用nvidia驱动的程序,如X server、禁用nouveau驱动
sudo /etc/init.d/lightdm stop
sudo /etc/init.d/lightdm status
这里以lightdm类型桌面为例,如果是gdm类型桌面,则命令改为gdm。更多关闭方式可参考关闭X server,推荐最后一种方式从其他设备终端登录关闭。
2. 卸载原驱动:
$ sudo apt remove --purge nvidia-*
3. 安装新驱动:
进入英伟达驱动下载(备选),按类型搜索下载驱动安装包。
本文选用支持CUDA11.2的460.91.03版本
运行$ sudo sh NVIDIA-Linux-x86_64-460.91.03.run按提示安装即可。
4. 更新docker
若使用容器,还需相应更新nvidia-docker-runtime,运行命令:
$ sudo apt install nvidia-docker-runtime
注: 若apt未能索引到nvidia-docker-runtime,可以尝试更换为:
$ sudo apt install nvidia-container-runtime
附: Docker安装教程参考官网指南
FAQ: 添加apt源后update更新提示无Release,是因为国内访问docker官方源不稳定,可在添加源时将官方源替换为国内镜像,本文以阿里云镜像源为例:
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] http://mirrors.aliyun.com/docker-ce/linux/ubuntu \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt update
Docker
$ docker run -itd --gpus 'device=0,"capabilities=compute,utility"' --name=tensorrt_test -h tensorrt_test -v /home/nas:/home/data nvidia/cuda:10.2-devel-ubuntu16.04 bash
-
--name:容器名 -
-h:容器的host名 -
-v:目录映射。主机目录:容器目录 -
nvidia/cuda:10.2-devel-ubuntu16.04:公共镜像,可自行到docker-hub中拉取需要的镜像。 -
--gpus:配置容器使用GPU外设。device指定用哪个显卡,若使用全部则直接写all;capabilities指定容器使用GPU能力,具体如下:- compute: 需要在docker中使用CUDA和OpenCL
- compat32:需要在docker中运行32位程序
- graphics: 需要在docker中使用OpenGL和Vulkan
- utility:需要在docker中使用nvidia-smi和NVML
- video:需要在docker中使用视频编解码
- display:需要在docker中使用X11
在启动容器时需要为容器指定其需要的GPU能力,默认为utility。在深度学习开发中,往往需要cuda和cudnn此时需要添加compute能力。参考
进入容器$ docker exec -it tensorrt_test bash
CUDA
TensorRT7.2.3.4支持10.2, 11.0.1, 11.1.1, and 11.2.1,自己选择合适版本下载安装。本文使用11.0.1。
1. 下载CUDA安装包
Installer Type推荐选择runfile(local)
$ wget https://developer.download.nvidia.com/compute/cuda/11.0.3/local_installers/cuda_11.0.3_450.51.06_linux.run
2. 安装cuda
$ sudo sh cuda_11.0.3_450.51.06_linux.run
#..一堆协议说明...
accept/decline/quit: accept #接受协议
Install NVIDIA Accelerated Graphics Driver for Linux-x86_64?
(y)es/(n)o/(q)uit: n #是否安装显卡驱动,由于已经安装显卡驱动,选择n
Install the CUDA 11.0 Toolkit?(y)es/(n)o/(q)uit: y #是否安装CUDA工具包,选择y
Enter Toolkit Location
[ default is /usr/local/cuda-11.0 ]: #工具包安装路径,默认回车即可,也可根据自己情况修改路径
Do you want to install a symbolic link at /usr/local/cuda?
(y)es/(n)o/(q)uit: y #添加软链接,如果你之前安装过另一个版本的cuda,除非你确定想要用这个新版本的cuda,否则这里建议选no,因为指定该链接后会将cuda指向这个新的版本。
Install the CUDA 11.0 Samples?
(y)es/(n)o/(q)uit: n #安装样例,这里看自己情况
Enter CUDA Samples Location
[ default is /root ]: #如果上面选择n则无需管该项,否则样例安装地址自己选择
# ***安装信息***
Installing the CUDA Toolkit in /usr/local/cuda-11.0 ...
Finished copying samples.
===========
= Summary =
===========
Driver: Not Selected
Toolkit: Installed in /usr/local/cuda-11.0
Samples: Not Selected
Please make sure that
- PATH includes /usr/local/cuda-11.0/bin
- LD_LIBRARY_PATH includes /usr/local/cuda-11.0/lib64, or, add /usr/local/cuda-11.0/lib64 to /etc/ld.so.conf and run ldconfig as root
To uninstall the CUDA Toolkit, run the uninstall script in /usr/local/cuda-11.0/bin
Please see CUDA_Installation_Guide_Linux.pdf in /usr/local/cuda-11.0/doc/pdf for detailed information on setting up CUDA.
***WARNING: Incomplete installation! This installation did not install the CUDA Driver.
To install the driver using this installer, run the following command, replacing <CudaInstaller> with the name of this run file:
sudo <CudaInstaller>.run -silent -driver
Logfile is /tmp/cuda_install_6388.log
# ***安装完成***
若安装过程中出现Missing recommended library错误,运行下面命令安装相关依赖:
$ sudo apt install freeglut3-dev build-essential libx11-dev libxmu-dev libxi-dev libgl1-mesa-glx libglu1-mesa libglu1-mesa-dev
3. 配置CUDA环境变量
修改~/.bashrc文件在文件末尾添加环境变量:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64
export PATH=$PATH:/usr/local/cuda/bin
export CUDA_HOME=$CUDA_HOME:/usr/local/cuda
保存后还需使其生效: $ source ~/.bashrc
注意: 上面在设置环境变量时,使用的是cuda,而不是cuda-11.0,这主要是为了方便我们切换cuda版本,可以让我们不用每次都去该环境变量的值。当我们想使用其他版本时,只需要删除该软链接,然后重新建立指向另一版本CUDA的软链接即可(注意软连接名称还是cuda,因为要与~/.bashrc文件里设置的保持一致)
$ sudo rm -rf cuda
$ sudo ln -s /usr/local/cuda-10.2 /usr/local/cuda
4. 安装cudnn
- 进入cudnn下载选择v8.1.0 for cuda11.0,11.1,11.2下载。
- 解压
$ tar -xzvf cudnn-x.x-linux-x64-v8.x.x.x.tgz - 将cudnn库文件复制到cuda相应目录:
$ sudo cp cuda/include/cudnn*.h /usr/local/cuda/include
$ sudo cp -P cuda/lib64/libcudnn* /usr/local/cuda/lib64
$ sudo chmod a+r /usr/local/cuda/include/cudnn*.h /usr/local/cuda/lib64/libcudnn*
注意: 命令里使用的软链接地址,如果软链接指向的不是所需目标路径请修改命令为具体的绝对路径。
5.查看版本
$ uname -a // 查看ubuntu发行版本信息
$ ls -l /usr/local/ | grep cuda // 查看cuda版本
$ cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2 // 查看cudnn版本
$ cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2 // 查看cudnn版本
TensorRT
下载TensorRT7安装包:
进入TensorRT7.2.3下载选择合适版本下载安装包,推荐选择TAR package(Deb安装方式可参考文末)。本文选择TensorRT-7.2.3.4.Ubuntu-16.04.x86_64-gnu.cuda-11.0.cudnn8.1.tar.gz。
注: TensorRT8只支持cuda11.0及以上版本,若你的cuda是11.0及以上可安装TensorRT8,否则选低版本。另,TensorRT8.5以下版本由于自带cudnn,所以只需关注cuda版本,无需关注cudnn版本;而TensorRT8.5及以上版本不再捆绑cudnn,所以不仅要明确cuda版本还需明确系统的cudnn版本再选择相应cuda和cudnn版本对应的TensorRT8.5及以上版本安装
TAR包方式
1. 解压
$ version=7.2.3.4
$ os=Ubuntu-16.04
$ arch=$(uname -m)
$ cuda=cuda-11.0
$ cudnn=cudnn8.1
$ tar xzvf TensorRT-${version}.${os}.${arch}-gnu.${cuda}.${cudnn}.tar.gz
2. 安装python包
$ cd TensorRT-${version}/python
$ sudo pip3 install tensorrt-7.2.3.4-cp37-none-linux_x86_64.whl
3. 安装graphsurgeon
$ cd TensorRT-${version}/graphsurgeon
$ sudo pip3 install graphsurgeon-0.4.5-py2.py3-none-any.whl
4. 安装onnx-graphsurgeon
$ cd TensorRT-${version}/onnx_graphsurgeon
$ sudo pip3 install onnx_graphsurgeon-0.2.6-py2.py3-none-any.whl
5. 安装UFF(可选)
如果你需要使用带有转换tensorflow模型的tensorrt还需安装UFF
$ cd TensorRT-${version}/uff
$ sudo pip3 install uff-0.6.9-py2.py3-none-any.whl
检查安装which convert-to-uff
6. 配置环境变量
在~/.bashrc末尾增加
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:{TensorRT_PATH}/lib
自行替换{TensorRT_PATH}为你的绝对路径。使其生效$ source ~/.bashrc
7. 安装pycuda并验证tensorrt
$ sudo pip3 install pycuda==2020.1
由于2020.1版本之后官方只提供源码包,故2020.1版本以上需要源码编译安装,下面以2023.1版本为例:
-
下载源码包并解压
pycuda2023.1版本源码包 -
编译并安装
编译中需要pyconfig.h头文件,确保在${CPLUS_INCLUDE}中能找到正确头文件。如果本地没有需要安装对应版本的python-dev,如apt install python3.8-dev
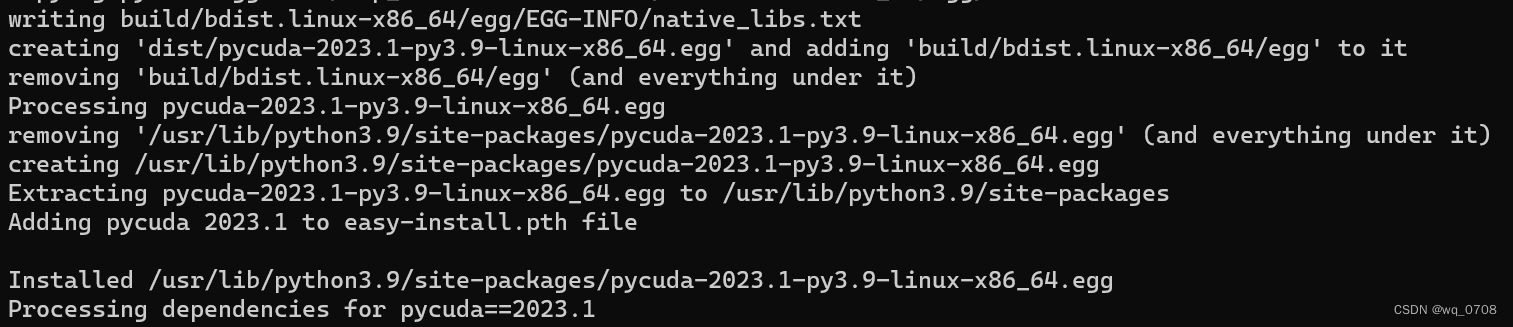
安装中依赖Mako、appdirs、pytools三个python包,可以提前安装以防因网络问题自动安装终止。$ cd pycuda-VERSION $ python configure.py --cuda-root=/usr/local/cuda $ su -c "make install"当出现如下图中Installed xxx/pycuda-xxx.egg时证明安装成功,最后需把egg目录加入环境变量
PYTHONPATH
 注: 如果要将PyCUDA安装到其他路径下,则需要编辑Makefile中的setup.py调用,方法是在install指令后的行中添加例如
注: 如果要将PyCUDA安装到其他路径下,则需要编辑Makefile中的setup.py调用,方法是在install指令后的行中添加例如--home=/home/${whoami}/local -
测试
$ cd pycuda-VERSION/test $ python test_driver.py
进入python环境
import tensorrt
import pycuda
如果均能正常导入则安装成功
Deb本地仓方式
1. 安装
$ version=7.0.0.1
$ os=ubuntu1804
$ arch=amd64
$ cuda=cuda10.0
$ sudo dpkg -i nv-tensorrt-repo-${os}-${cuda}-trt${version}-ga-20210226_1-1_${arch}.deb
$ sudo cp /var/nv-tensorrt-local-repo-${os}-${cuda}-trt${version}/*-keyring.gpg /usr/share/keyrings/
$ sudo apt update
$ sudo apt install tensorrt
2.验证
$ sudo dpkg -l | grep TensorRT
如下图,能显示出TensorRT组件信息就是安装成功




















 676
676



 到【灌水乐园】发言
到【灌水乐园】发言








