






计算图简介
计算图重要性
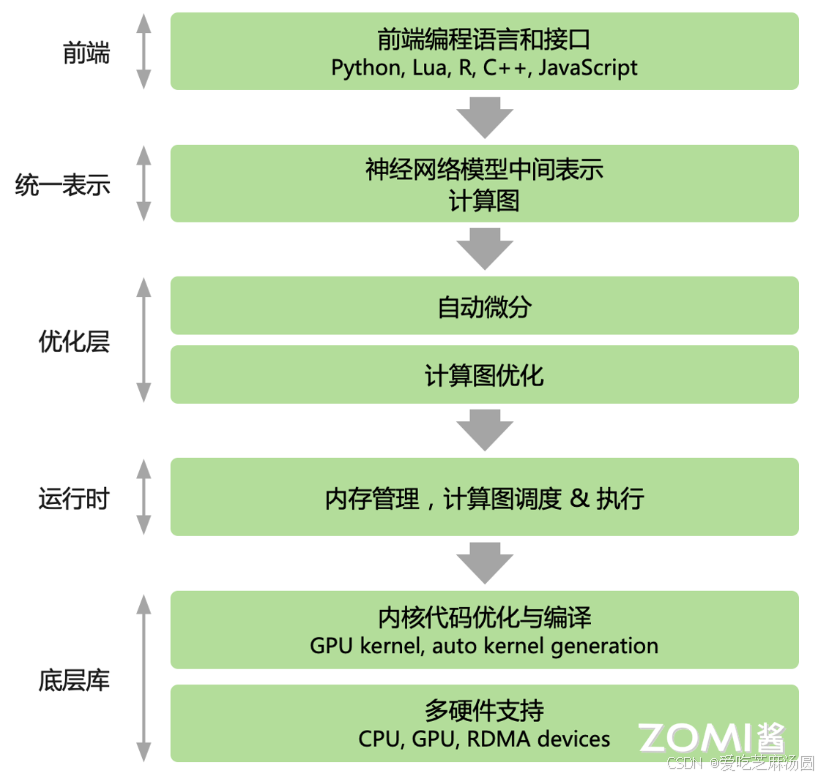
- 目前主流的 AI 框架都选择使用计算图来抽象神经网络计算表达,通过通用的数据结构(张量)来理解、表达和执行神经网络模型,通过计算图可以把 AI 系统化的问题形象地表示出来。
- 神经网络的训练流程主要包括一下五个过程:
- 1)前向计算、
- 2)计算损失、
- 3)自动求导、
- 4)反向传播、
- 5)更新模型参数。
- 在基于计算图的 AI 框架中,这五个阶段统一表示为由基本算子构成的计算图,算子是数据流图中的一个节点,由后端进行高效实现。
计算图基本组成
- AI 框架中的计算图的基本组成有两个主要的元素:
- 1)基本数据结构张量和
- 2)基本计算单元算子。
- 节点代表 Operator 具体的计算操作(即算子),边代表 Tensor 张量。整个计算图能够有效地表达神经网络模型的计算逻辑和状态。
- 基本数据结构张量:张量通过shape来表示张量的具体形状,决定在内存中的元素大小和元素组成的具体形状;其元素类型决定了内存中每个元素所占用的字节数和实际的内存空间大小
- 基本运算单元算子:具体在加速器 GPU/NPU 中执行运算的是由最基本的代数算子组成,另外还会根据深度学习结构组成复杂算子。每个算子接受的输入输出不同,如 Conv 算子接受 3 个输入 Tensor,1 个输出 Tensor
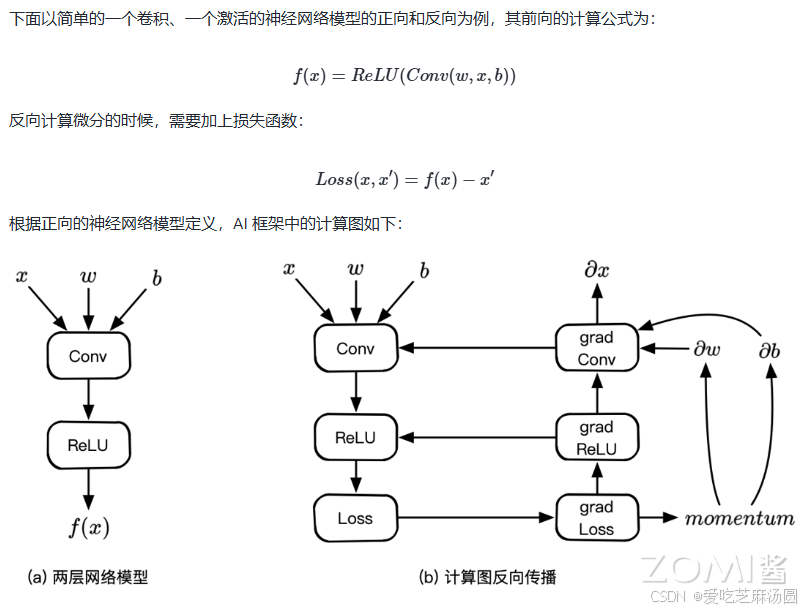
计算图的自动微分

- AI 框架对于带有自动微分的计算图中的可导张量操作实现步骤具体如下:
- 同时注册前向计算结点和导数计算结点;
- 前向结点接受输入计算输出;
- 反向结点接受损失函数对当前张量操作输出的梯度v;
- 当上一张量操作的输入和输出,计算当前张量操作每个输入的向量-雅克比乘积。
AI框架自动微分方式
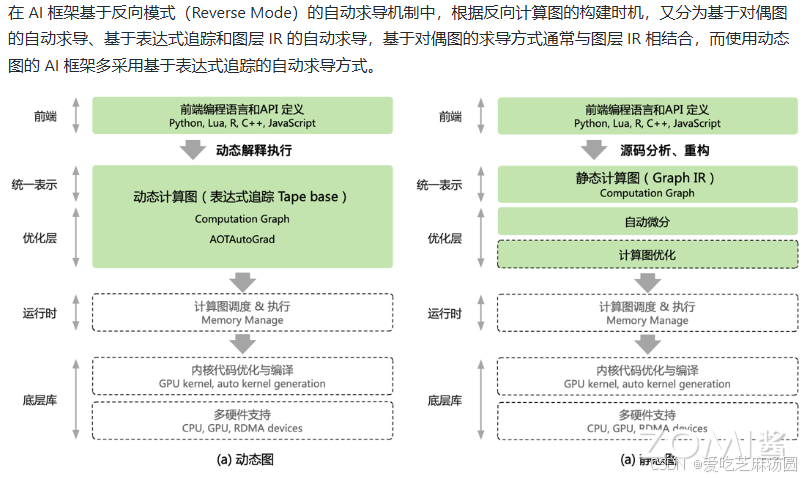
动态计算图
一、PyTorch 动态计算图的特点
- 动态性的第一层含义:计算图的正向传播是立即执行的。每执行一条语句,就会在计算图中动态添加节点(表示张量或函数)和边(表示张量和函数之间的依赖关系),并立即得到计算结果,无需等待完整计算图创建完毕。
例如以下代码:
import torch
w = torch.tensor([[3.0, 1.0]], requires_grad=True)
b = torch.tensor([[3.0]], requires_grad=True)
X = torch.randn(10, 2)
Y = torch.randn(10, 1)
# Y_hat 定义后其正向传播被立即执行,与其后面的 loss 创建语句无关
Y_hat = X@w.t() + b
print(Y_hat.data)
loss = torch.mean(torch.pow(Y_hat - Y, 2))
print(loss.data)
在上述代码中,定义 Y_hat=X@w.t()+b 后,其正向传播被立即执行,与后面 loss 的创建语句无关。
- 动态性的第二层含义:计算图在反向传播后立即销毁,下次调用需重新构建。当使用
backward方法执行反向传播或torch.autograd.grad方法计算梯度后,计算图会被销毁以释放存储空间。若要保留计算图,可在backward中设置retain_graph = True。
例如:
# 如果再次执行反向传播将报错
loss.backward()
# 计算图在反向传播后立即销毁,如果需要保留计算图, 需要设置
retain_graph = True
loss.backward(retain_graph=True)
二、PyTorch 自动微分技术
- 实现方法:业界主流 AI 框架 PyTorch 及 PyTorch Autograd 采用基于磁带(tape-based)的自动微分技术,类似磁带式录音机记录当前执行的操作,然后向后重放以计算每一层的梯度。即把上下文的变量操作记录在
tape上,再用反向微分法计算函数导数。 - 表达式追踪(Evaluation Trace):这是 AI 框架中实现自动微分最常用的方式,通过追踪数值计算过程的中间变量,在前向计算中保留中间计算结果,依据反向模式原理依次计算中间导数,反向计算复用正向计算保留的中间结果。
- 动态计算图生成:每次执行神经网络模型,根据前端语言描述动态生成一份临时计算图,计算图动态生成且过程灵活可变,利于神经网络结构调整阶段提高效率。
- 表达式追踪的优缺点
- 优点:方便跟踪和理解计算过程,易用性较高。
- 缺点:需保存大量中间计算结果,内存占用比静态图实现方式高。
- Gradient Tape 的记录特点:Gradient Tape 默认只记录对
Variable的操作,原因一是Tape需要记录前向传播所有计算过程才能计算后向传播;二是Tape会记录所有中间结果,无需记录无用操作。 - 与基于对偶图自动求导机制的对比:基于表达式追踪的自动微分是在前向传播过程中构建反向计算图,能基于输出梯度信息对输入自动求导,与基于对偶图的自动求导机制的滞后性不同 。
静态计算图
一、静态计算图的基本概念与示例(以TensorFlow为例)
- 代码示例
import tensorflow as tf
# 定义输入张量
a = tf.constant(3.0)
b = tf.constant(4.0)
# 定义计算操作
c = tf.add(a, b)
- 原理:在代码定义阶段构建计算图,之后再进行编译和执行。这种方式能够对计算图进行优化,从而提高计算效率。
- 过程:当定义
tf.add(a, b)这样的操作时,TensorFlow 会将该操作添加到默认的计算图中,但此时不会立即执行计算。所有操作定义完成后,需要通过tf.Session()来运行计算图。在运行之前,TensorFlow 会对计算图进行如合并操作、减少内存使用等优化。
二、基于图层 IR 的静态计算图实现自动微分
- 实现方式:静态地生成可以根据 Python 等前端高级语言描述的神经网络拓扑结构,以及参数变量等图层信息构建一个固定的计算图,这种实现方式被称为静态计算图。
- 自动微分实现:在基于计算图的 AI 框架中,利用反向微分计算梯度通常实现为计算图上的一个优化 Pass。给定前向计算图,以损失函数为根节点广度优先遍历前向计算图时,便能按照对偶结构自动生成出反向计算图。
三、静态图的执行过程
- 构建正向图:在构建正向图的时候,依据图层 IR 的定义,把 Python 等高级语言对神经网络模型的统一描述,通过源码转换成图层 IR 对应的正向计算图,同时将导数的计算也表示成计算图。
- 生成反向图并优化:获取正向计算图后,根据自动微分的反向模式实现方法,在执行前先生成反向对应的静态计算图,并完成对该计算图的编译优化,然后再交给后端硬件执行具体的计算。
四、静态图的特点
- 优点:
- 计算图的构建和实际计算分开进行,定义好整个计算流后,再次运行不需要重新构建计算图,性能更高效。像 TensorFlow 和 MindSpore 等 AI 框架默认使用静态图实现机制。
- 通过图层 IR 的抽象,AI 框架构建起对计算图的统一描述,便于对全局计算图进行编译优化。
- 执行期间可不依赖前端语言描述,并且能够大量复用图中的内存,常用于神经网络模型部署,如移动端安防领域、人脸识别等场景。
- 缺点:
- 计算执行过程中代码的错误不容易被发现,无法像动态图一样实时拿到中间计算结果,给代码调试带来一定麻烦。
- 从开发者角度看,静态图不能实时获取中间结果、代码调试困难以及控制流编写复杂。
五、静态图与动态图的对比(从开发者角度)
- 静态图编写、生成过程复杂,执行性能超过动态图。
- 动态图可以实时获取结果、调试简单、控制流符合编程习惯,这也是 PyTorch 框架越来越受欢迎的原因。



















 2953
2953

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









