




任务2
- 题目
在使用很多文字编辑软件时,都有对所编辑的文稿进行搜索的功能。当文稿内容的数据量比较大时,检索的效率就必须要进行考虑了。利用任务 1 中构建的 BST 数据结构,可以比较有效地解决这个问题。将文稿中出现的每个单词都插入到用 BST 构建的搜索表中,记录每个单词在文章中出现的行号。
本次实验准备了一篇英文文稿,文件名为 article.txt1,请按照上面的样例根据该 article.txt 中的内容构建索引表,并将索引表的内容按照单词的字典序列输出到 index_result.txt 文件中。
在构建 BST 中的结点数据时,请认真思考记录行号的数据类型,如果可能,尽可能使用在之前实验中自己构建的数据结构,也是对之前数据结构使用的一种验证。
- 数据设计
直接使用问题一自己构建的BSTTree即可,只需要有一点注意的,我们需要一个额外的方法insert2,解释如下:
- /**
- @Precondition 二叉查找树未满。
- Key和value不能为null。
- @Postcondition 向二叉查找树中插入一个新元素(包括键和值)。
- 如果树中已经存在具有相同键值的元素,则将使用newElement的value字段加入该元素的value字段。例如,原来的value是a,新的value是b,那么树中的value就是a b
- @return none
- */
- public void insert2(K key, V value);
具体的实现方法其实就是,当新加入的键值对的键在树中存在的话,那么不是更新对应的值,而是把值加入原来的值中。
- @Override
- public void insert2(K key, V value) {
- if (key == null) {
- throw new NullPointerException("Key cannot be null");
- }
- if (value == null) {
- throw new NullPointerException("Value cannot be null");
- }
- root = doInsert2(root, key, value); // 更新根节点
- }
- private BSTNode<K, V> doInsert2(BSTNode<K, V> node, K key, V value) {
- if (node == null) {
- return new BSTNode<>(key, value, null, null); // 创建新节点并返回
- }
- if (key.compareTo(node.key) < 0) {
- node.left = doInsert2(node.left, key, value); // 递归插入左子树
- } else if (key.compareTo(node.key) > 0) {
- node.right = doInsert2(node.right, key, value); // 递归插入右子树
- } else {
- String oldValue = node.value.toString();
- String newValue = value.toString();
- node.value = (V) (oldValue + " " + newValue); // 将新值添加到现有值的后面,并添加空格
- }
- return node;
- }
- @Override
- public void insert2(K key, V value) {
- if (key == null) {
- throw new NullPointerException("Key cannot be null");
- }
- if (value == null) {
- throw new NullPointerException("Value cannot be null");
- }
- root = doInsert2(root, key, value); // 更新根节点
- }
- private BSTNode<K, V> doInsert2(BSTNode<K, V> node, K key, V value) {
- if (node == null) {
- return new BSTNode<>(key, value, null, null); // 创建新节点并返回
- }
- if (key.compareTo(node.key) < 0) {
- node.left = doInsert2(node.left, key, value); // 递归插入左子树
- } else if (key.compareTo(node.key) > 0) {
- node.right = doInsert2(node.right, key, value); // 递归插入右子树
- } else {
- String oldValue = node.value.toString();
- String newValue = value.toString();
- node.value = (V) (oldValue + " " + newValue); // 将新值添加到现有值的后面,并添加空格
- }
- return node;
- }
- 算法设计
算法与第一问也有很多相似之处,依旧是逐行读取,设置一个lineNumber记录行数,每行针对每一个单词进行提取,将提取出来的单词和对应的行数用Insert2方法插入树中即可,有一个关键点在于,如何屏蔽标点符号如“,”,“.”但是保留类似Tom’s 的单词。可以用正则表达式来匹配和提取单词。
正则表达式 [a-zA-Z]+(?:'[a-z]+)? 中,[a-zA-Z] 匹配任意一个字母(大小写不限);+ 表示前面的模式可以出现一次或多次,即匹配一个或多个字母;(?:'[a-z]+)? 是一个非捕获组,用于匹配以撇号 ' 开头,后面跟着一个或多个小写字母的模式;(?: ... ) 表示一个非捕获组,? 表示这个组出现零次或一次。
- private static <K extends Comparable<K>, V> void executeCommand(BSTTree<K, V> bstTree, String line , String lineNumber) throws IOException {
- Pattern pattern = Pattern.compile("[a-zA-Z]+(?:'[a-z]+)?"); // 匹配英语单词的正则表达式模式
- Matcher matcher = pattern.matcher(line);
- while (matcher.find()) {
- String word = matcher.group();
- bstTree.insert2((K) word, (V) lineNumber);
- }
- }
- 运行结果展示
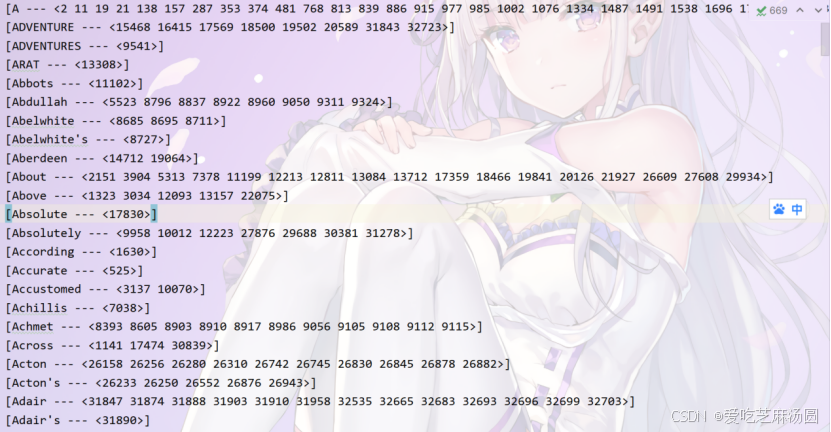
图3 index_result文件测试结果(部分)
- 总结和收获
第一次了解正则表达式并且运用,感觉其实没太搞懂,还要继续努力。
附录:
- 任务2
- BSTTree新增的方法insert2:
- @Override
- public void insert2(K key, V value) {
- if (key == null) {
- throw new NullPointerException("Key cannot be null");
- }
- if (value == null) {
- throw new NullPointerException("Value cannot be null");
- }
- root = doInsert2(root, key, value); // 更新根节点
- }
- private BSTNode<K, V> doInsert2(BSTNode<K, V> node, K key, V value) {
- if (node == null) {
- return new BSTNode<>(key, value, null, null); // 创建新节点并返回
- }
- if (key.compareTo(node.key) < 0) {
- node.left = doInsert2(node.left, key, value); // 递归插入左子树
- } else if (key.compareTo(node.key) > 0) {
- node.right = doInsert2(node.right, key, value); // 递归插入右子树
- } else {
- String oldValue = node.value.toString();
- String newValue = value.toString();
- node.value = (V) (oldValue + " " + newValue); // 将新值添加到现有值的后面,并添加空格
- }
- return node;
- }
- 任务2的FileTest:
- package Homework02;
- import Homework01.BSTTree;
- import java.io.*;
- import java.util.regex.Matcher;
- import java.util.regex.Pattern;
- public class FileTest {
- private static PrintWriter writer;
- public static void main(String[] args) throws IOException {
- BSTTree<String, String> bstTree = new BSTTree<>();
- FileReader fileReader = new FileReader("D:\\develop\\projects\\dataStructure\\homework03\\file\\homework3_article.txt");
- BufferedReader br = new BufferedReader(fileReader);
- writer = new PrintWriter(new FileWriter("D:\\develop\\projects\\dataStructure\\homework03\\file\\index_result.txt")); // 创建PrintWriter对象,并将输出定向到文件
- String line;
- int lineNumber = 0;
- while ((line = br.readLine()) != null) {
- lineNumber++;
- String str = Integer.toString(lineNumber);
- executeCommand(bstTree, line, str);
- writer.flush(); // 刷新PrintWriter的缓冲区
- }
- bstTree.printInorder(writer);
- writer.close(); // 在循环结束后关闭PrintWriter对象
- }
- //泛型方法
- private static <K extends Comparable<K>, V> void executeCommand(BSTTree<K, V> bstTree, String line , String lineNumber) throws IOException {
- Pattern pattern = Pattern.compile("[a-zA-Z]+(?:'[a-z]+)?"); // 匹配英语单词的正则表达式模式
- Matcher matcher = pattern.matcher(line);
- while (matcher.find()) {
- String word = matcher.group();
- bstTree.insert2((K) word, (V) lineNumber);
- }
- }
- }

















 943
943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









