







前言-异构计算平台
异构计算(Heterogeneous computing)
指使用不同类型指令集和体系架构的计算单元组成系统的计算方式。
通常将CPU与其他如GPU、DPU、DSP、FPGA等组成的异构平台。
随着CPU频率和内核数量的提升对计算效力带来的
边际效用递减逐渐显现,单纯依靠CPU的提升已经无法满足实际需求。与此同时,
GPU等专用计算单元在逐渐发展中功能变得更加强悍。CPU擅长于处理不规则数据结构和不可预测的存取模式,以及递归算法、分支密集型代码和单线程程序等这类程序任务拥有复杂的指令调度、循环、分支、逻辑判断以及执行等步骤;而GPU擅于处理规则数据结构、大规模并行、可预测存取模式。行业内表现突出异构平台是以英伟达
、寒武纪、华为等为代表的公司设计开发的GPU算力板卡+CPU服务器的形式出现在用户面前。
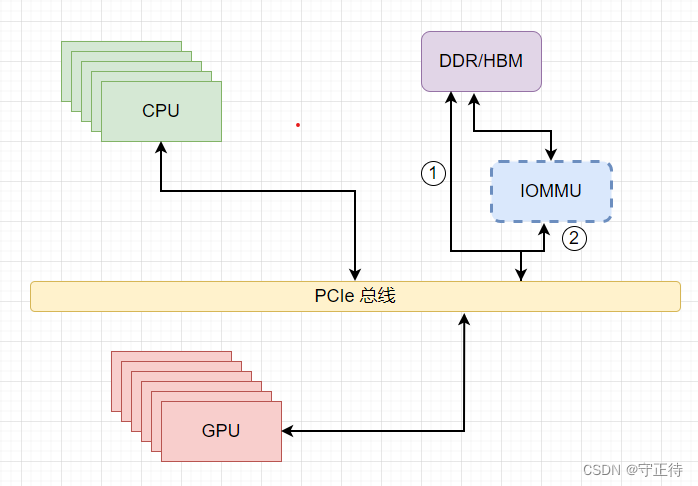
一、无IOMMU通路
如上图①所示,在没有IOMMU的平台上,使用
SWIOTLB技术实现
一种纯软件的地址映射方案,其作用在于使得寻址能力较低、无法直接寻址到内核所分配的DMA buffer的那些设备,也能够进行DMA操作。
假设一个64位系统,其内存的基地址是0x80000000,内存大小是4G,则内存的物理地址范围是0x80000000-0x180000000,同时该系统中某个外设的DMA只能按32 bits地址寻址,即寻址范围为0-0xFFFFFFFF,如果恰好非给该外设DMA的内存地址超过了这个范围,该外设DMA实际无法使用该地址。swiotlb维护了一块低地址的buffer,该buffer的大小可以由bootloader通过swiotlb参数传递给内核,也可以使用默认值,默认值是64M。如果给DMA分配的物理地址(这里记做phyaddr1)超过了其寻址能力,那么swiotlb技术将从其buffer中分配同样大小的一块空间,给DMA使用,其物理地址记做phyaddr2,swiotlb会维护phyaddr1和phyaddr2的映射关系。
-
在函数mem_init的一开始,就调用swiotlb_init做swiotlb的初始化,swiotlb_init中就会分配所需要的buffer,也确实保证buffer在 低地址区间 。
-
swiotlb维护了一张io_tlb_orig_addr表,这张表维护了原始物理地址和swiotlb分配物理地址之间的映射关系。当DMA将数据写入swiotlb分配的物理地址后,一般会以中断的方式通知CPU,CPU在查看DMA写到内存的数据之前,需要先做一个sync,该sync操作就会触发swiotlb将数据拷贝到原始物理地址处,这样就保证了CPU能够看到正确的数据,可以想见,这种需要CPU深度参与方式效率不高。
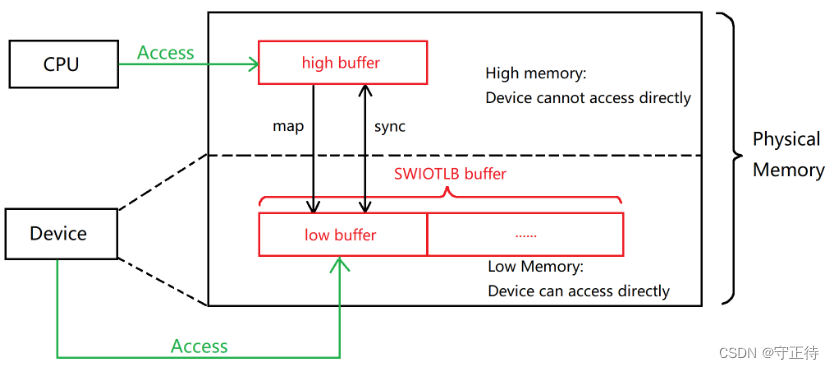
在以上过程中,需要确保low buffer的访问的缓存一致性。以DMA Streaming Mapping举例:
-
申请到一块 high buffer记作 Data Buffer
-
通过map_single从swiotlb里找到一块low buffer记作 Bounce Buffer
-
把CPU访问的Data Buffer与Bounce Buffer映射起来
-
最后通过swiotlb同步机制把这两个buffer中的数据做个拷贝(memcpy)
-
DMA 写 - CPU 读
-
-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2071
2071

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









