




 本文介绍了CUDA编程的基础知识,包括__global__修饰符的使用、内存管理函数cudaMalloc()、cudaFree()和cudaMemcpy(),以及如何查询和选择GPU设备。
本文介绍了CUDA编程的基础知识,包括__global__修饰符的使用、内存管理函数cudaMalloc()、cudaFree()和cudaMemcpy(),以及如何查询和选择GPU设备。
CUDA C简介
CPU上的Hello World
/*
//代码3.2.1:在CPU上运行C程序
//时间:2019.07.20
#include <iostream>
int main(void)
{
printf("Hello, world!\n");
system("pause");
return 0;
}
GPU上的Hello World
我们将CPU以及系统的内存称为Host,而将GPU及其内存称为Device,在GPU Device上执行的函数通常称为Kernal。
/*
//代码3.2.2:在GPU上运行CUDA C程序,在CPU上运行C程序
//时间:2019.07.20
*/
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <iostream>
__global__ void kernal()
{
}
int main(void)
{
kernal << <1, 1 >> >();
printf("Hello, world!\n");
system("pause");
return 0;
}
*/
与CPU的Hello World相比,GPU的Hello World多了两个值得注意的地方:
(1)一个空的函数kernal(),并且带有修饰符__global__
(2)对这个空函数的调用,并且带有修饰字符<<<1,1>>>
__global__修饰符:
CUDA C为标准C增加了__global__修饰符。这个修饰符将告诉编译器,该函数应该编译为在设备上执行而不是编译为主机执行,__global__修饰符正是Host调用Device的接口
在这个简单是示例中,函数kernal()将被交给编译GPU设备代码的编译器进行编译,而main()函数将被交给CPU主机编译器进行编译。
至于修饰字符<<<1,1>>>我们留在以后再解释,现在只要知道这个修饰字符跟怎样组织GPU的并行性有关即可。
向kernal()中传递参数
/*
//代码3.2.3传递参数
//时间:2019.07.20
*/
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <iostream>
__global__ void add(int a,int b,int *c)
{
*c = a + b;
}
int main(void)
{
int c;
int *dev_c;
//第一个参数是一个指针,指向用于保存新分配内存地址的变量
//第二个参数是分配内存的大小
//返回类型为void*,这与C语言中malloc()返回分配内存的指针存在不同
cudaMalloc((void**)&dev_c, sizeof(int));
//需要注意的是:
//可以将cudaMalloc()分配的指针传递给在设备上执行的函数
//可以在设备代码中使用cudaMalloc()分配的指针进行内存读写操作
//可以将cudaMalloc()分配的指针传递给在主机上执行的函数
//不能在主机代码中使用cudaMalloc()分配的指针进行内存读写操作
add << <1, 1 >> >(2, 4, dev_c);
//cudaMemcpy,第一个参数是主机指针,第二个参数是设备指针,第三个参数指明内存copy的大小
//cudaMemcpyDeviceToHost,指明运行时源指针是一个设备指针,而目标指针是一个主机指针
cudaMemcpy(&c,dev_c,sizeof(int),cudaMemcpyDeviceToHost);
cudaFree(dev_c);
printf("2+4=%d\n", c);
system("pause");
return 0;
}

这里新增了多行代码,在这些代码中包含两个概念:
(1)可以像调用C函数那样将参数传递给核函数
(2)当设备执行任何有用的操作时,都需要分配内存
cudaMalloc()函数:
在设备存储空间中为变量分配内存:
cudaMalloc()函数除了分配内存的指针不是作为函数的返回值外,其他的行为与malloc()是相同的,并且返回类型为void *
第一个参数是一个指针,指向用于保存新分配内存地址的变量,第二个参数是分配内存的大小。
注意,程序员一定不能在主机代码中对cudaMalloc()返回的指针进行解引用。
综上,将Device指针的使用限制总结如下:
(1)可以将cudaMalloc()分配的指针传递给在设备上执行的函数
(2)可以在Device代码中使用cudaMalloc()分配的指针进行内存读写操作
(3)可以将cudaMalloc()分配的的指针传递给在主机上执行的函数
(4)不能在主机代码中使用cudaMalloc()分配的指针进行内存读写操作
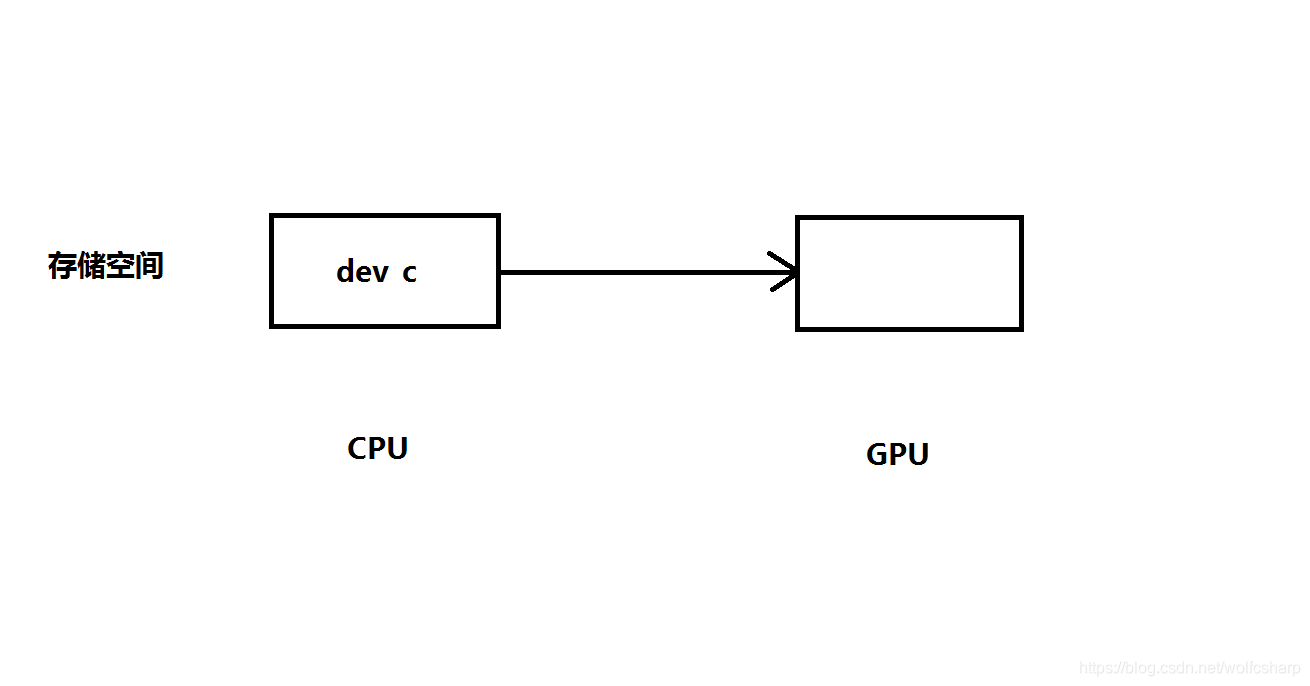
主机指针只能访问主机代码中的内存,设备指针只能访问设备代码中的内存。
cudaFree()函数:
类似于标准C中的free()函数,cudaFree用于释放在GPU上分配的空间。
cudaMemcpy()函数:
在主机代码中可以通过调用cudaMemcpy()函数来访问设备上的内存。这个函数调用的行为类似于标准C中的memcpy(),只不过多了一个参数来指定设备内存指针究竟是源指针还是目标指针。
函数参数说明,第一个参数是目标指针,第二个参数是源指针,第三个参数指明内存copy的大小,第四个参数指明内存copy的方向。
比如,目标指针是device,源指针是device,第四个参数设置为cudaMemcpyDeviceToHost,这个参数将指明运行时源指针是一个设备指针,而目标指针是一个主机指针。
查询设备信息
/*
//代码3.3查询设备
//时间:2019.07.20
*/
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <iostream>
int main(void)
{
cudaDeviceProp prop;
int count;
cudaGetDeviceCount(&count);
for (int i = 0; i < count; i++)
{
cudaGetDeviceProperties(&prop, i);
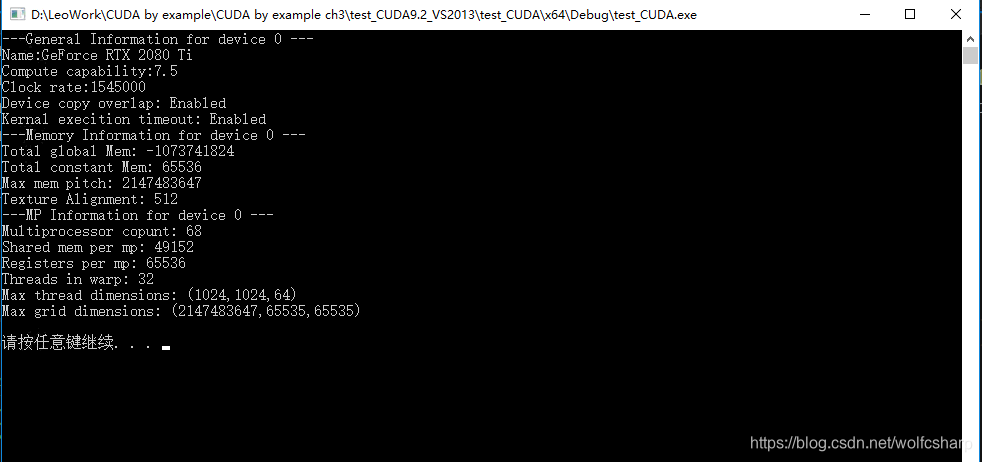
printf("---General Information for device %d ---\n", i);
printf("Name:%s\n", prop.name);
printf("Compute capability:%d.%d\n", prop.major, prop.minor);
printf("Clock rate:%d\n", prop.clockRate);
printf("Device copy overlap: ");
if (prop.deviceOverlap)printf("Enabled\n");
else printf("Disabled\n");
printf("Kernal execition timeout: ");
if (prop.kernelExecTimeoutEnabled)printf("Enabled\n");
else printf("Disabled\n");
printf("---Memory Information for device %d ---\n", i);
printf("Total global Mem: %ld\n", prop.totalGlobalMem);
printf("Total constant Mem: %ld\n", prop.totalConstMem);
printf("Max mem pitch: %ld\n", prop.memPitch);
printf("Texture Alignment: %ld\n", prop.textureAlignment);
printf("---MP Information for device %d ---\n", i);
printf("Multiprocessor copunt: %d\n", prop.multiProcessorCount);
printf("Shared mem per mp: %ld\n", prop.sharedMemPerBlock);
printf("Registers per mp: %d\n", prop.regsPerBlock);
printf("Threads in warp: %d\n", prop.warpSize);
printf("Max thread dimensions: (%d,%d,%d)\n",prop.maxThreadsDim[0],prop.maxThreadsDim[1],prop.maxThreadsDim[2]);
printf("Max grid dimensions: (%d,%d,%d)\n",prop.maxGridSize[0],prop.maxGridSize[1],prop.maxGridSize[2]);
printf("\n");
}
system("pause");
}
cudaGetDeviceCount()函数:
如果硬件设备中包含有多个CUDA设备,可以通过cudaGetDeviceCount()函数获得CUDA设备的数量。
结构体cudaDeviceProp
用于存储设备的相关属性
/**
* CUDA device properties
*/
struct __device_builtin__ cudaDeviceProp
{
char name[256]; /**< ASCII string identifying device */
size_t totalGlobalMem; /**< Global memory available on device in bytes */
size_t sharedMemPerBlock; /**< Shared memory available per block in bytes */
int regsPerBlock; /**< 32-bit registers available per block */
int warpSize; /**< Warp size in threads */
size_t memPitch; /**< Maximum pitch in bytes allowed by memory copies */
int maxThreadsPerBlock; /**< Maximum number of threads per block */
int maxThreadsDim[3]; /**< Maximum size of each dimension of a block */
int maxGridSize[3]; /**< Maximum size of each dimension of a grid */
int clockRate; /**< Clock frequency in kilohertz */
size_t totalConstMem; /**< Constant memory available on device in bytes */
int major; /**< Major compute capability */
int minor; /**< Minor compute capability */
size_t textureAlignment; /**< Alignment requirement for textures */
size_t texturePitchAlignment; /**< Pitch alignment requirement for texture references bound to pitched memory */
int deviceOverlap; /**< Device can concurrently copy memory and execute a kernel. Deprecated. Use instead asyncEngineCount. */
int multiProcessorCount; /**< Number of multiprocessors on device */
int kernelExecTimeoutEnabled; /**< Specified whether there is a run time limit on kernels */
int integrated; /**< Device is integrated as opposed to discrete */
int canMapHostMemory; /**< Device can map host memory with cudaHostAlloc/cudaHostGetDevicePointer */
int computeMode; /**< Compute mode (See ::cudaComputeMode) */
int maxTexture1D; /**< Maximum 1D texture size */
int maxTexture1DMipmap; /**< Maximum 1D mipmapped texture size */
int maxTexture1DLinear; /**< Maximum size for 1D textures bound to linear memory */
int maxTexture2D[2]; /**< Maximum 2D texture dimensions */
int maxTexture2DMipmap[2]; /**< Maximum 2D mipmapped texture dimensions */
int maxTexture2DLinear[3]; /**< Maximum dimensions (width, height, pitch) for 2D textures bound to pitched memory */
int maxTexture2DGather[2]; /**< Maximum 2D texture dimensions if texture gather operations have to be performed */
int maxTexture3D[3]; /**< Maximum 3D texture dimensions */
int maxTexture3DAlt[3]; /**< Maximum alternate 3D texture dimensions */
int maxTextureCubemap; /**< Maximum Cubemap texture dimensions */
int maxTexture1DLayered[2]; /**< Maximum 1D layered texture dimensions */
int maxTexture2DLayered[3]; /**< Maximum 2D layered texture dimensions */
int maxTextureCubemapLayered[2];/**< Maximum Cubemap layered texture dimensions */
int maxSurface1D; /**< Maximum 1D surface size */
int maxSurface2D[2]; /**< Maximum 2D surface dimensions */
int maxSurface3D[3]; /**< Maximum 3D surface dimensions */
int maxSurface1DLayered[2]; /**< Maximum 1D layered surface dimensions */
int maxSurface2DLayered[3]; /**< Maximum 2D layered surface dimensions */
int maxSurfaceCubemap; /**< Maximum Cubemap surface dimensions */
int maxSurfaceCubemapLayered[2];/**< Maximum Cubemap layered surface dimensions */
size_t surfaceAlignment; /**< Alignment requirements for surfaces */
int concurrentKernels; /**< Device can possibly execute multiple kernels concurrently */
int ECCEnabled; /**< Device has ECC support enabled */
int pciBusID; /**< PCI bus ID of the device */
int pciDeviceID; /**< PCI device ID of the device */
int pciDomainID; /**< PCI domain ID of the device */
int tccDriver; /**< 1 if device is a Tesla device using TCC driver, 0 otherwise */
int asyncEngineCount; /**< Number of asynchronous engines */
int unifiedAddressing; /**< Device shares a unified address space with the host */
int memoryClockRate; /**< Peak memory clock frequency in kilohertz */
int memoryBusWidth; /**< Global memory bus width in bits */
int l2CacheSize; /**< Size of L2 cache in bytes */
int maxThreadsPerMultiProcessor;/**< Maximum resident threads per multiprocessor */
int streamPrioritiesSupported; /**< Device supports stream priorities */
int globalL1CacheSupported; /**< Device supports caching globals in L1 */
int localL1CacheSupported; /**< Device supports caching locals in L1 */
size_t sharedMemPerMultiprocessor; /**< Shared memory available per multiprocessor in bytes */
int regsPerMultiprocessor; /**< 32-bit registers available per multiprocessor */
int managedMemory; /**< Device supports allocating managed memory on this system */
int isMultiGpuBoard; /**< Device is on a multi-GPU board */
int multiGpuBoardGroupID; /**< Unique identifier for a group of devices on the same multi-GPU board */
int hostNativeAtomicSupported; /**< Link between the device and the host supports native atomic operations */
int singleToDoublePrecisionPerfRatio; /**< Ratio of single precision performance (in floating-point operations per second) to double precision performance */
int pageableMemoryAccess; /**< Device supports coherently accessing pageable memory without calling cudaHostRegister on it */
int concurrentManagedAccess; /**< Device can coherently access managed memory concurrently with the CPU */
int computePreemptionSupported; /**< Device supports Compute Preemption */
int canUseHostPointerForRegisteredMem; /**< Device can access host registered memory at the same virtual address as the CPU */
int cooperativeLaunch; /**< Device supports launching cooperative kernels via ::cudaLaunchCooperativeKernel */
int cooperativeMultiDeviceLaunch; /**< Device can participate in cooperative kernels launched via ::cudaLaunchCooperativeKernelMultiDevice */
size_t sharedMemPerBlockOptin; /**< Per device maximum shared memory per block usable by special opt in */
int pageableMemoryAccessUsesHostPageTables; /**< Device accesses pageable memory via the host's page tables */
int directManagedMemAccessFromHost; /**< Host can directly access managed memory on the device without migration. */
};
cudaGetDeviceProperties()函数:
用于获得指定编号设备的属性信息,第一个参数是cudaDeviceProp类型的指针,第二个参数指定GPU设备编号,如果有N个GPU设备,设备编号从0开始一直到N-1。
cudaDeviceProp prop;
cudaGetDeviceProperties(&prop, 0);//获得第0个GPU设备的属性信息
设备属性的使用:选择一个符合条件约束的设备
/*
//代码3.4设备属性的使用:选择一个符合条件约束的设备
//时间:2019.07.20
*/
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <iostream>
int main()
{
cudaDeviceProp prop;
int dev;
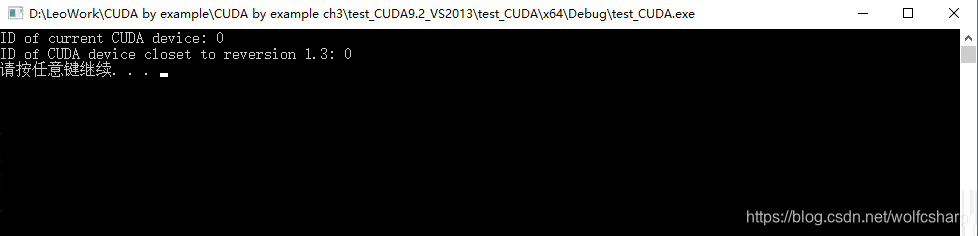
//获得当前的GPU设备
cudaGetDevice(&dev);
printf("ID of current CUDA device: %d\n", dev);
//筛选符合要求的设备
memset(&prop, 0, sizeof(cudaDeviceProp));
prop.major = 1;
prop.minor = 3;
cudaChooseDevice(&dev,&prop);
printf("ID of CUDA device closet to reversion 1.3: %d\n",dev);
//设置为筛选出来的GPU设备
cudaSetDevice(dev);
system("pause");
}
假设我们的代码对显卡的版本也有所要求,只有在版本为1.3及以上的计算功能集版本显卡上才能够运行,为了让我们的代码具有更好的鲁棒性,需要筛选出符合要求的GPU来执行代码。
根据cudaGetDeviceCount()和cudaGetDeviceProperties()中返回的结果,我们可以对每个设备进行迭代,并且查找主版本号大于1,或者主版本号为1且次版本号大于等于3的设备。
其实,CUDA运行时提供了一种自动方式来执行这个迭代操作:
首先,找出我们希望设备拥有的属性并将这些属性填充到一个cudaDeviceProp结构中
在填充完cudaDeviceProp之后,将其传递给cudaChooseDevice(),这样CUDA运行时将查找是否存在某个设备满足这些条件。cudaChooseDevice()函数将返回一个设备ID,这个ID就是符合我们筛选要求的GPU,然后我们可以将这个ID传递给cudaSetDevice(),之后所有的设备操作都将在这个设备上执行。
cudaGetDevice()函数:
获得当前运行使用的GPU ID。
输入参数为用于盛放设备ID的地址,cudaGetDevice()函数将用当前设备ID填充这个指针指向的内存。
cudaChooseDevice()函数:
根据cudaDeviceProp设定的筛选条件进行设备筛选。
第一个参数为用于盛放筛选结果的地址,第二个参数为cudaDeviceProp类型筛选条件的内存地址。
cudaSetDevice()函数:
设置使用指定的GPU。
输入参数为指定GPU的ID。
本章小结
1.__global__修饰符
2.cudaMalloc()函数
3.cudaFree()函数
4.cudaMemcpy()函数
5.cudaGetDeviceCount()函数
6.结构体cudaDeviceProp
7.cudaGetDeviceProperties()函数
8.cudaGetDevice()函数
9.cudaChooseDevice()函数
10.cudaSetDevice()函数

















 6755
6755

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









