







计算x^2-2*x最小值
import torch
import torch.nn as nn
import torch.optim as optim
# 定义神经网络模型(单参数优化器)
class QuadraticOptimizer(nn.Module):
def __init__(self, init_x=0.0):
super().__init__()
self.x = nn.Parameter(torch.tensor([init_x], dtype=torch.float32)) # 将x定义为可训练参数
def forward(self):
return self.x ** 2 - 2 * self.x
# 初始化
model = QuadraticOptimizer(init_x=3.0) # 初始值设为3.0(可任意设置)
optimizer = optim.SGD(model.parameters(), lr=0.1) # 使用随机梯度下降
# optimizer = optim.Adam(model.parameters(), lr=0.1) # 也可以使用Adam
# 训练过程
print("迭代过程:")
for epoch in range(50):
optimizer.zero_grad() # 清零梯度
y = model() # 前向计算
y.backward() # 反向传播
optimizer.step() # 更新参数
# 输出当前结果
current_x = model.x.item()
current_y = y.item()
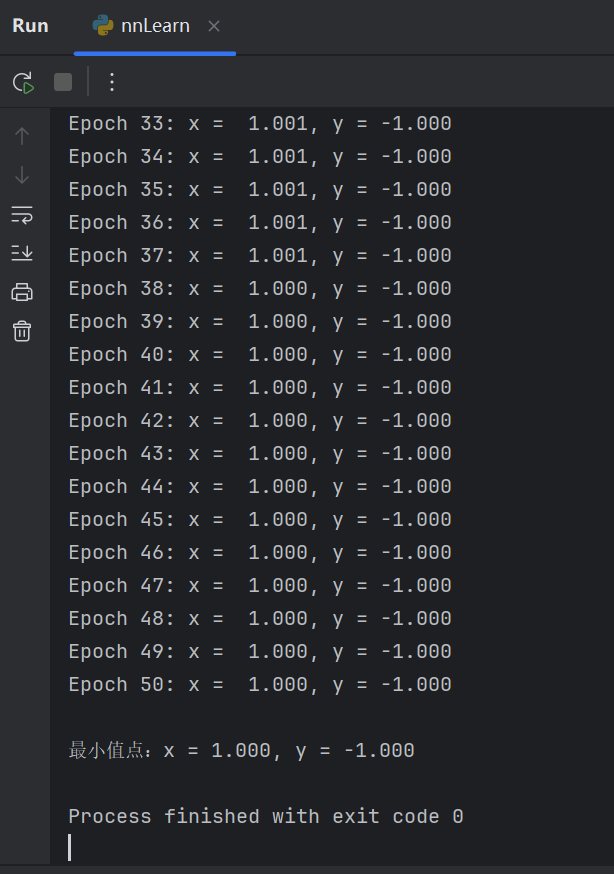
print(f"Epoch {epoch + 1:2d}: x = {current_x:6.3f}, y = {current_y:6.3f}")
# 最终结果
optimal_x = model.x.item()
optimal_y = optimal_x ** 2 - 2 * optimal_x
print(f"\n最小值点:x = {optimal_x:.3f}, y = {optimal_y:.3f}")
结果
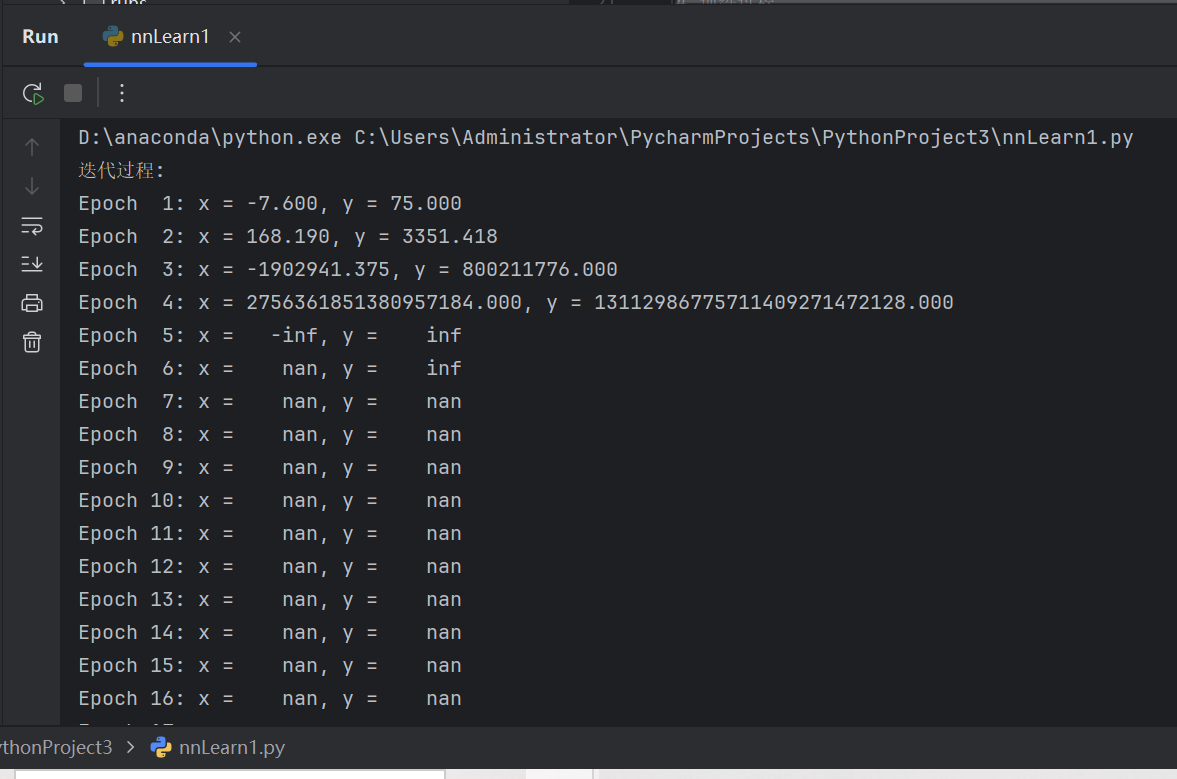
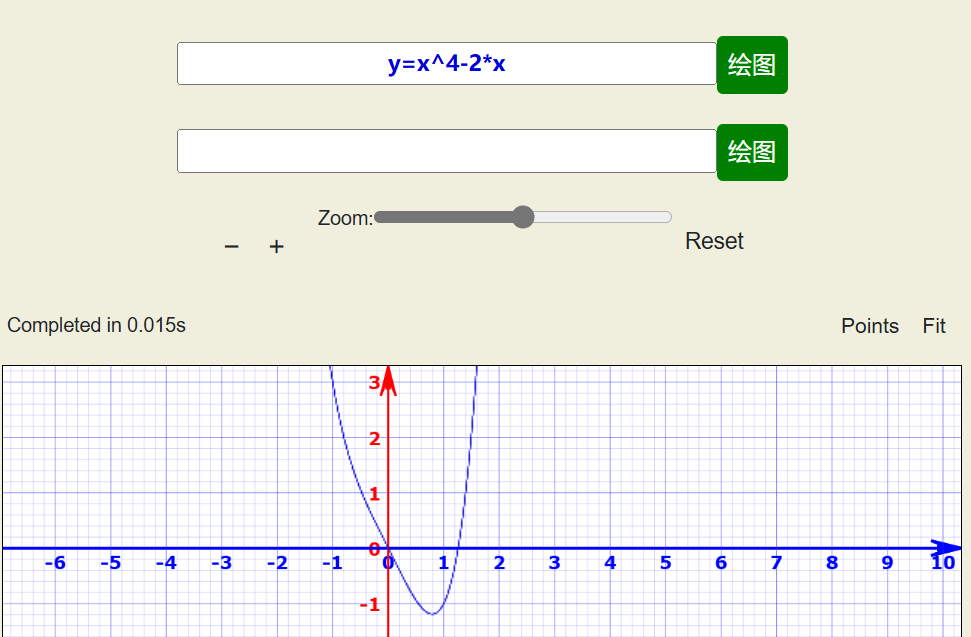
计算x^4-2*x最小值
学习率过高,产生梯度爆炸
修改
optimizer = optim.SGD(model.parameters(), lr=0.01) # 使用随机梯度下降
结果
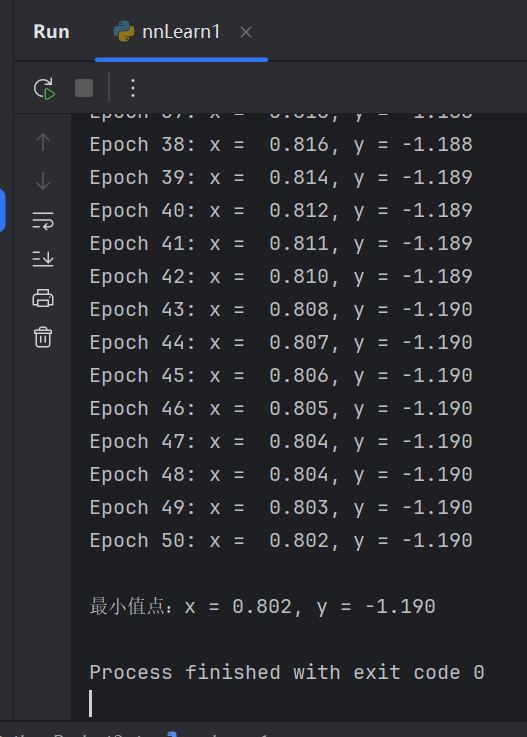
与函数图像基本吻合
计算-(x^4-2*x)最大值
import torch
import torch.nn as nn
import torch.optim as optim
# 定义神经网络模型(单参数优化器)
class QuadraticOptimizer(nn.Module):
def __init__(self, init_x=0.0):
super().__init__()
self.x = nn.Parameter(torch.tensor([init_x], dtype=torch.float32)) # 将x定义为可训练参数
def forward(self):
return -(self.x ** 4 - 2 * self.x)
# 初始化
model = QuadraticOptimizer(init_x=3.0) # 初始值设为3.0(可任意设置)
optimizer = optim.SGD(model.parameters(), lr=0.01) # 使用随机梯度下降
# optimizer = optim.Adam(model.parameters(), lr=0.01) # 也可以使用Adam
# 训练过程
print("迭代过程:")
for epoch in range(50):
optimizer.zero_grad() # 清零梯度
y = model() # 前向计算
(-y).backward() # 反向传播
optimizer.step() # 更新参数
# 输出当前结果
current_x = model.x.item()
current_y = y.item()
print(f"Epoch {epoch + 1:2d}: x = {current_x:6.3f}, y = {current_y:6.3f}")
# 最终结果
optimal_x = model.x.item()
optimal_y = -(optimal_x ** 4 - 2 * optimal_x)
print(f"\n最小值点:x = {optimal_x:.3f}, y = {optimal_y:.3f}")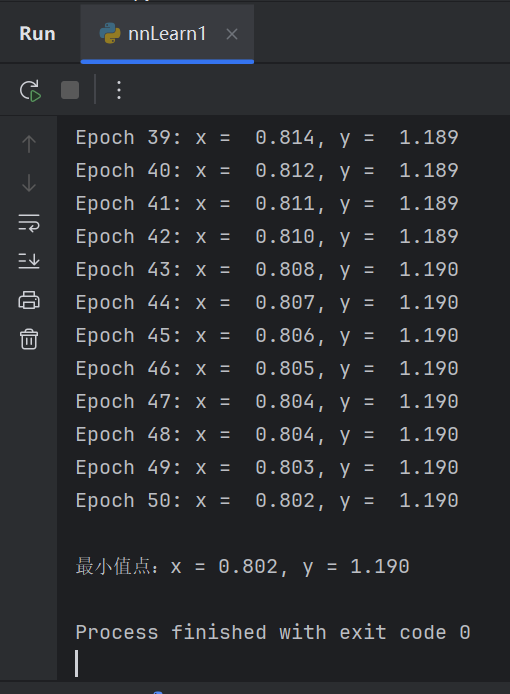
优化器
不同的优化器
from torch.optim._adafactor import Adafactor as Adafactor
from torch.optim.adadelta import Adadelta as Adadelta
from torch.optim.adagrad import Adagrad as Adagrad
from torch.optim.adam import Adam as Adam
from torch.optim.adamax import Adamax as Adamax
from torch.optim.adamw import AdamW as AdamW
from torch.optim.asgd import ASGD as ASGD
from torch.optim.lbfgs import LBFGS as LBFGS
from torch.optim.nadam import NAdam as NAdam
from torch.optim.optimizer import Optimizer as Optimizer
from torch.optim.radam import RAdam as RAdam
from torch.optim.rmsprop import RMSprop as RMSprop
from torch.optim.rprop import Rprop as Rprop
from torch.optim.sgd import SGD as SGD
from torch.optim.sparse_adam import SparseAdam as SparseAdamPyTorch学习之 torch.optim 的6种优化器及优化算法介绍_torch torch.optim.sgd-优快云博客
代码解析
训练流程
- 清零梯度(
optimizer.zero_grad()):在每次反向传播之前,需要将模型参数的梯度清零。因为在 PyTorch 中,梯度是累积的,如果不清零,新计算的梯度会和之前的梯度累加,导致模型无法正确更新。 - 前向计算:将输入数据传入模型,通过模型的各个层进行计算,得到模型的输出。这个过程是根据模型的结构和参数进行的正向计算。
- 反向传播(
loss.backward()):根据模型的输出和真实标签计算损失函数的值,然后调用backward()方法,PyTorch 会自动根据计算图反向传播误差,计算出每个需要求梯度的参数的梯度。 - 更新参数(
optimizer.step()):使用优化器根据计算得到的梯度更新模型的参数。优化器会根据预设的优化算法(如 SGD、Adam 等)来更新参数。
optimizer.zero_grad() # 清零梯度
在一次前向传播与反向传播完成之后,如果不把梯度清零,那么下一次反向传播计算得到的梯度就会和之前的梯度累加起来。
import torch
import torch.nn as nn
import torch.optim as optim
# 定义一个简单的线性模型
model = nn.Linear(1, 1)
optimizer = optim.SGD(model.parameters(), lr=0.1)
# 模拟两次前向传播和反向传播
for _ in range(2):
input_tensor = torch.tensor([[1.0]])
output = model(input_tensor)
loss = output.sum()
loss.backward()
# 查看梯度
for param in model.parameters():
print(param.grad)在这个示例中,由于没有调用 optimizer.zero_grad(),第二次反向传播之后得到的梯度是两次梯度的累加值。
在大多数深度学习任务中,每一次迭代我们都期望基于当前批次的数据来计算梯度,并且使用这些梯度更新模型参数。梯度累积会让梯度值失去其应有的意义,从而导致模型无法正确学习。
requires_grad=True
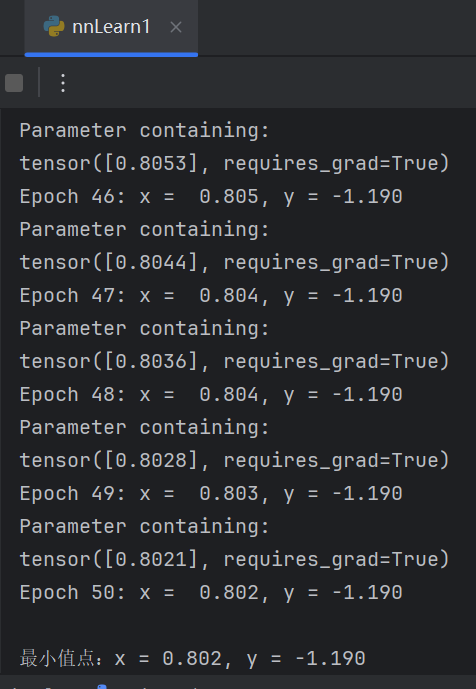
在深度学习里,梯度是进行参数更新的关键依据。PyTorch 采用自动求导机制(Autograd)来计算梯度。当一个张量的 requires_grad 属性被设置为 True 时,PyTorch 会追踪该张量上进行的所有操作,并构建一个计算图。在调用 backward() 方法时,就能够通过这个计算图反向传播误差,进而计算出该张量的梯度。
在进行推理时,通常不需要计算梯度,这样可以节省内存和计算资源。可以通过 with torch.no_grad(): 上下文管理器来临时禁用梯度计算:
import torch
x = torch.tensor([2.0], requires_grad=True)
# 禁用梯度计算
with torch.no_grad():
y = x ** 2
print(y.requires_grad) # 输出 False
















 1346
1346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









