







 极限学习机(ELM)是一种无须反向传播调整权重的前馈神经网络,适用于监督学习。文章提供了基于Matlab的ELM代码实现,包括回归预测和分类任务,展示了其在多输入预测和分类任务上的高效性能。数据集和详细注释使得该代码适合初学者学习。
极限学习机(ELM)是一种无须反向传播调整权重的前馈神经网络,适用于监督学习。文章提供了基于Matlab的ELM代码实现,包括回归预测和分类任务,展示了其在多输入预测和分类任务上的高效性能。数据集和详细注释使得该代码适合初学者学习。
目录
摘要:
极限学习机(Extreme Learning Machine, ELM)或“超限学习机”是一类基于前馈神经网络(Feedforward Neuron Network, FNN)构建的机器学习系统或方法,适用于监督学习和非监督学习问题。ELM在研究中被视为一类特殊的FNN,或对FNN及其反向传播算法的改进,其特点是隐含层节点的权重为随机或人为给定的,且不需要更新,学习过程仅计算输出权重。
本代码基于Maltab平台,分别搭建了两种极限学习机,第一种用于进行多输入单输出的回归预测拟合,第二种用于进行多输入单输出的分类。使用不同的数据集对以上两种极限学习机进行训练,两种极限学习机的构架均为一致,仅是执行的任务不同。使用自带的数据集进行学习和训练,最后测试了其效果,使用者可将数据集替换为自己的以实现不同的效果。结果表明极限学习机在学习多输入的预测和分类任务上可以达到十分优秀的效果。
本代码保证可完美运行,自带数据集,注释详细清楚,结构完整,非常适合初学者学习入门。
极限学习机原理的介绍:
极限学习机(ELM, Extreme Learning Machines)是一种前馈神经网络,最早由新加坡南洋理工大学黄广斌教授于2006年提出。其发表的文章中对于极限学习机的描述如下:该算法具有良好的泛化性能以及极快的学习能力极限学习机和标准神经网络的区别ELM 不需要基于梯度的反向传播来调整权重,而是通过 Moore-Penrose generalized inverse来设置权值。标准的单隐藏层神经网络结构如下:
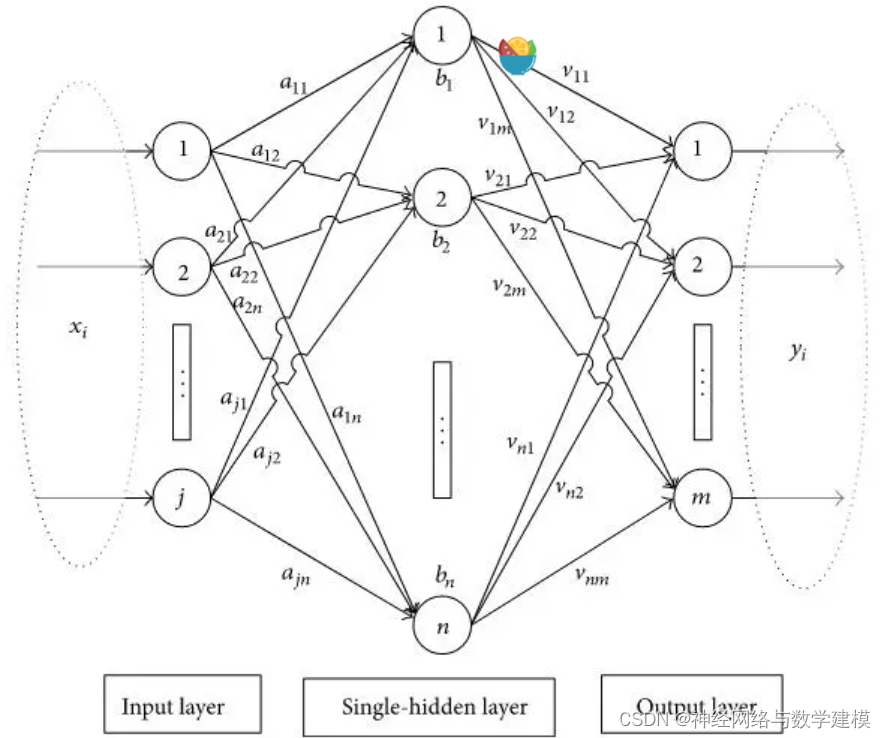
该网络为一个单隐藏层神经网络,其计算过程如下:
1输入值乘以权重值;2加上偏置值;3进行激活函数计算;4对每一层重复步骤1~3;5计算输出值;6误差反向传播;7重复步骤1~6而 ELM 则对其进行了如下改进:去除步骤4;用一次矩阵逆运算替代步骤6;去除步骤7。
机器学习领域有许多与ELM思路相当的算法,例如随机向量连接函数Random Vector Functional-Link, RVFL)和Schmidt等对前馈神经网络权重的随机化实验。因此,在ELM被提出后有观点认为,ELM不是一种独立的算法。并且有评论指出,ELM原作者为了凸显其工作的独立性而有意回避了对其它类似研究的引用。但也有观点认为,ELM通过发展,已成为独立的,且包含完整理论并与其它机器学习方法相联系的学习系统。
部分实现代码(以回归预测为例):
clearall
clc
%%1.导入数据
loadspectra_data.mat
%%2.随机产生训练集和测试集
temp=randperm(size(NIR,1));
%训练集-50个样本
P_train=NIR(temp(1:50),:)';
T_train=octane(temp(1:50),:)';
%测试集-10个样本
P_test=NIR(temp(51:60),:)';
T_test=octane(temp(51:60),:)';
N=size(P_test,2);
%%3.归一化数据
%3.1.训练集
[Pn_train,inputps]=mapminmax(P_train);
Pn_test=mapminmax('apply',P_test,inputps);
%3.2.测试集
[Tn_train,outputps]=mapminmax(T_train);
Tn_test=mapminmax('apply',T_test,outputps);
%%4.ELM训练
[IW1,B1,H1,TF1,TYPE1]=elmtrain(Pn_train,Tn_train,30,'sig',0);
%%5.ELM仿真测试
tn_sim01=elmpredict(Pn_test,IW1,B1,H1,TF1,TYPE1);
%计算模拟输出
%5.1.反归一化
T_sim=mapminmax('reverse',tn_sim01,outputps);
%%6.结果对比
result=[T_test'T_sim'];
%6.1.均方误差
E=mse(T_sim-T_test);
%6.2相关系数
N=length(T_test);
R2=(N*sum(T_sim.*T_test)-sum(T_sim)*sum(T_test))^2/((N*sum((T_sim).^2)-(sum(T_sim))^2)*(N*sum((T_test).^2)-(sum(T_test))^2));
代码实现效果:
回归任务:
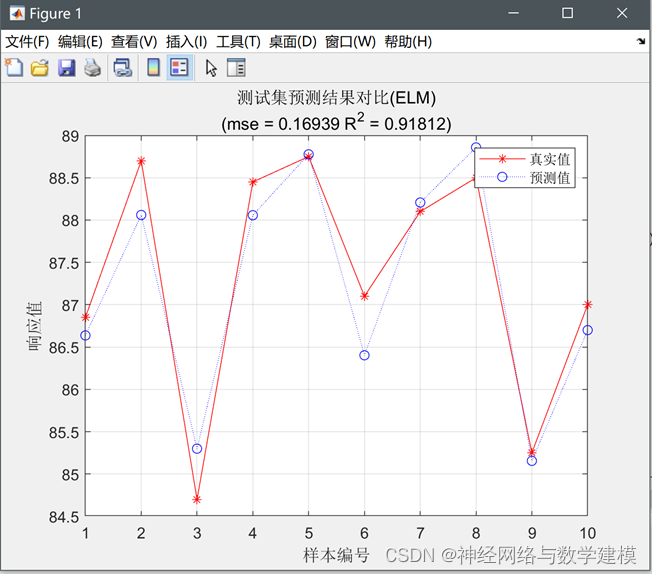
分类任务:


本文完整代码+数据集分享:


















 1483
1483

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









