




 本文探讨了小样本和不均衡样本在分类任务中的挑战,如过拟合和欠拟合,以及它们可能导致的模型偏差。解决方案包括数据采样技术,如过采样、欠采样和综合采样,以及采用代价敏感学习的算法。案例实战展示了在实际业务中,如何通过数据增强、选择合适的模型(如AdaCost)和调整超参数来优化模型性能。最终,找到合适的样本比例和代价系数能有效提高模型的F1分数。
本文探讨了小样本和不均衡样本在分类任务中的挑战,如过拟合和欠拟合,以及它们可能导致的模型偏差。解决方案包括数据采样技术,如过采样、欠采样和综合采样,以及采用代价敏感学习的算法。案例实战展示了在实际业务中,如何通过数据增强、选择合适的模型(如AdaCost)和调整超参数来优化模型性能。最终,找到合适的样本比例和代价系数能有效提高模型的F1分数。
01 小样本、不均衡样本在分类任务中普遍存在
随着计算能力、存储空间、网络的高速发展,人类所积累的数据量正在快速增长,而分类在数据挖掘中是一项非常重要的任务,已渐渐融入到了我们的日常生活中。

上述为机器学习领域分类任务的几个典型应用场景。在信用卡反欺诈场景中,大部分行为为正常刷卡,盗刷行为(为识别目标,定义为正样本)是小概率事件,甚至 1%都不到。同理,在用户离网告警场景中,大部分用户是正常的在网用户,离网用户(为识别目标,定义为正样本)只占非常小的一部分。可见,在很多建模场景中都存在识别目标样本数据量较少,样本极度不均衡的问题。
02 小样本、不均衡样本可能导致的问题
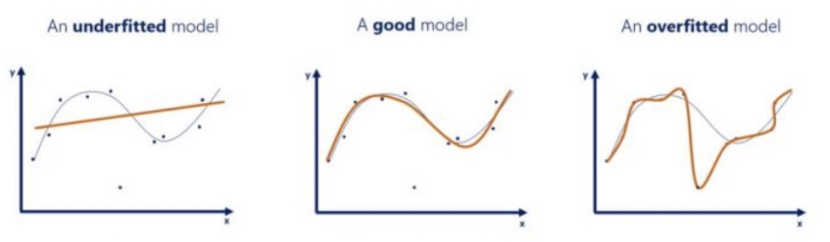
建模样本量不足,将导致模型陷入对小样本的过拟合以及对整体任务的欠拟合,缺乏泛化能力
过拟合是指模型对训练集“死记硬背”,记住了不适用于测试集的训练集性质或特点,没有理解数据背后的规律。导致其在训练样本中表现得过于优越,但在验证数据集以及测试数据集中表现不佳,即我们所说的“泛化能力差”。
正负样本比例严重失衡,信息的不均衡使得分类器更倾向于将数据样本判别为多数类
在一个极度不平衡的样本中,由于机器学习会针对每个样本数据进行学习,那么多数类样本带有的信息量比少数类样本信息量大,会对分类器的规则学习造成困扰,使得分类器存在将样本判别为多数类的倾向。具体表现为:多数类样本的查全率过高,少数类样本的查全率过低,而
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1260
1260

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









