




 本文详细介绍了ArrayList的构造方法、基础操作,包括添加、删除、修改元素,以及克隆和扩容机制。文章还探讨了ArrayList的性能优化,如预设容量以避免频繁扩容,以及在多线程环境下的使用注意事项。此外,对比了ArrayList与LinkedList在随机访问和插入删除操作上的性能差异,并分析了ArrayList的线程安全性问题。
本文详细介绍了ArrayList的构造方法、基础操作,包括添加、删除、修改元素,以及克隆和扩容机制。文章还探讨了ArrayList的性能优化,如预设容量以避免频繁扩容,以及在多线程环境下的使用注意事项。此外,对比了ArrayList与LinkedList在随机访问和插入删除操作上的性能差异,并分析了ArrayList的线程安全性问题。
🙏相见即是有缘,如果对你有帮助,给博主一个免费的点赞以示鼓励把QAQ☺
这里是温文艾尔の源码学习之路- 🙏作者水平欠佳,如果发现任何错误,欢迎批评指正
- 👋博客主页 温文艾尔の学习小屋
- 👋更多文章请关注温文艾尔主页
- 👋超详细ArrayList解析!
- 👋更多文章:
- 👋HashMap底层源码解析上(超详细图解+面试题)
- 👋HashMap底层源码解析下(超详细图解)
- 👋HashMap底层红黑树原理(超详细图解)+手写红黑树代码

文章目录
- 👋ArrayList底层源码
- 👋1 ArrayList继承关系
- 👋1.1 Cloneable的底层实现
- 👋1.2 RandomAccess标记接口
- 👋2 ArrayList构造方法源码解析
- 👋2.1 ArrayList()构造方法
- 👋2.2 ArrayList(int initialCapacity)构造方法
- 👋2.3 ArrayList(Collection<? extends E> c)构造方法
- 👋3 ArrayList基础方法
- 👋3.05 ArrayList中的各个变量
- 👋3.1添加方法
- 👋3.1.1 add(E e)
- 👋3.1.2 add(int index, E element)
- 👋3.1.3 addAll(Collection<? extends E> c)
- 👋3.1.4 addAll(int index, Collection<? extends E> c)
- 👋3.1.5 set(int index, E element)
- 👋3.1.6 get(int index)
- 👋3.1.7 remove(Object o)
- 👋3.1.8 clear()
- 👋4 扩展
- 👋4.1 转换方法toString()
- 👋4.2 迭代器Iterator iterator()
- 👋5 ArrayList相关面试题
- 👋5.1 ArrayList是如何扩容的
- 👋5.2 ArrayList频繁扩容导致添加性能急剧下降,如何处理?
- 👋5.3 ArrayList插入或删除元素一定比LinkedList慢吗
- 👋5.4 ArrayList是线程安全的吗
- 👋5.5 如何复制某个ArrayList到另一个ArrayList中去
- 👋5.6 已知成员变量集合存储N多用户名称,在多线程的环境下,使用迭代器在读取集合数据的同时如何保证还可以正常写入数据到集合中
- 👋5.7 ArrayList和LinkedList区别
👋ArrayList底层源码
ArrayList的类图示:
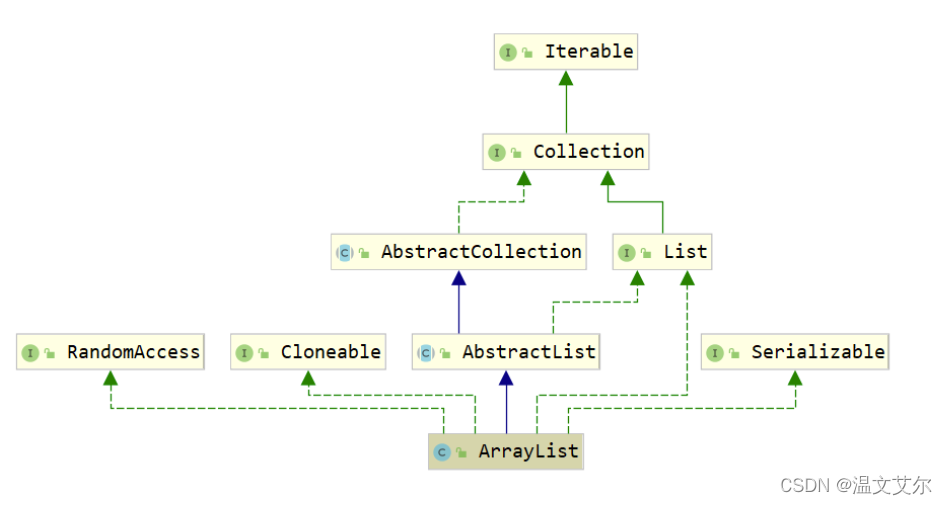
- ArrayList集合介绍
- List底层基于
动态数组实现
- List底层基于
- 数组结构介绍
增删慢:每次删除元素都需要更改数组长度,拷贝以及移动元素位置查询快:由于数组在内存中是一块连续空间,因此可以根据地址+索引的方式快速获取对应位置上的元素
👋1 ArrayList继承关系
Serializable标记性接口
介绍 类的序列化由实现java.io.Serializable接口的类启用。不实现此接口的类将不会使任何状态序列化或反序列化。可序列化类的所有子类型都是可序列化的,序列化接口没有方法或字段,仅用于标识可串行化的语义
- 序列化:将对象的数据写入到文件(写对象)
- 反序列化:将文件中对象的数据读取出来(读对象)
Cloneable标记性接口
- 介绍 一个类实现Cloneable接口来指示
Object.clone()方法,该方法对于该类的实例进行字段的复制是合法的。在不实现Cloneable接口的实例上调用对象的克隆方法会导致异常CloneNotSupportedException被抛出。简言之:克隆就是依据已有的数据,创造一份新的完全一样的数据拷贝 - 克隆的前提条件
- 被克隆对象所在的类必须
实现Cloneable接口 - 必须重写
clone()方法
- 被克隆对象所在的类必须
Serializable接口
- 由List实现使用,以表明它们支持
快速(通常为恒定时间)随机访问 - 此接口的主要目的是允许算法更改其行为,以便在应用于随机访问列表或顺序访问列表时提供良好的性能

👋1.1 Cloneable的底层实现
/**
* Returns a shallow copy of this <tt>ArrayList</tt> instance. (The
* elements themselves are not copied.)
*
* @return a clone of this <tt>ArrayList</tt> instance
*/
public Object clone() {
try {
ArrayList<?> v = (ArrayList<?>) super.clone();
v.elementData = Arrays.copyOf(elementData, size);
v.modCount = 0;
return v;
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError(e);
}
}
可以看到通过调用clone()方法,返回了一个ArrayList对象
v.elementData = Arrays.copyOf(elementData, size);
是我们能完成复制的关键,点进去
public static <T,U> T[] copyOf(U[] original, int newLength, Class<? extends T[]> newType)
{
@SuppressWarnings("unchecked")
T[] copy = ((Object)newType == (Object)Object[].class)
? (T[]) new Object[newLength]
: (T[]) Array.newInstance(newType.getComponentType(), newLength);
System.arraycopy(original, 0, copy, 0,
Math.min(original.length, newLength));
return copy;
}
我们原来数组中的数据通过System.arraycopy方法被拷贝到copy数组中,并将这个数组返回
克隆牵扯到浅拷贝和深拷贝,这里简述一下浅拷贝和深拷贝的区别
首先创建一个Student类
public class Student implements Cloneable {
private String name;
private Integer age;
public Student() {
}
public Student(String name, Integer age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
@Override
public Object clone() throws CloneNotSupportedException {
return super.clone();
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
浅拷贝实例
package ArrayListProject.CloneTest;
import java.util.ArrayList;
import java.util.List;
/**
* Description
* User:
* Date:
* Time:
*/
public class Test {
public static void main(String[] args) {
ArrayList list = new ArrayList();
Student stu = new Student("zs",18);
list.add("123");
list.add(stu);
System.out.println("未拷贝之前的数组:"+list);
ArrayList clone = (ArrayList)list.clone();
System.out.println("拷贝之后的数组:"+clone);
System.out.println("两个数组地址是否相等:"+(list==clone));
System.out.println("两个数组中的stu对象是否相等:");
System.out.println("list中的stu对象:"+list.get(1));
System.out.println("修改stu对象之前,clone中的stu对象:"+clone.get(1));
Student stu1 = (Student)list.get(1);
stu1.setName("ls");
System.out.println("修改stu对象之后,clone中的stu对象:"+clone.get(1));
System.out.println("两者stu对象的地址是否相同"+(list.get(1)==clone.get(1)));
}
}
未拷贝之前的数组:[123, Student{
name='zs', age=18}]
拷贝之后的数组:[123, Student{
name='zs', age=18}]
两个数组地址是否相等:false
两个数组中的stu对象是否相等:
list中的stu对象:Student{
name='zs', age=18}
修改stu对象之前,clone中的stu对象:Student{
name='zs', age=18}
修改stu对象之后,clone中的stu对象:Student{
name='ls', age=18}
两者stu对象的地址是否相同true
由此我们得出
- 克隆之后的对象是一个新对象,
list==clone为false可知二者地址不相同 - 由list.get(1)==clone.get(1)为true可知,两者中的
stu对象为同一对象 - 修改list中的stu对象,clone中的stu对象也会随之改变可知,克隆的是stu
对象的地址,并没有创建新的对象,它仅仅是拷贝了一份引用地址 - 基本数据类型可以达到
完全复制,而引用数据类型则不可以
深拷贝和浅拷贝不同,深拷贝中拷贝的对象是一个完全新的对象,他拷贝的并不是引用地址,而是实实在在的创建了一个对象

👋1.2 RandomAccess标记接口
- 由List实现使用,以表明它们支持快速(通常为恒定时间)随机访问
- 此接口的主要目的是允许算法更改其行为,以便在应用于随机访问列表或顺序访问列表时提供良好的性能
因此List实现RandomAccess在执行随机访问时,性能会比顺序访问更快
public interface RandomAccess {
}
我们通过一个案例来证明
我们以1000000个数据作为测试
package ArrayListProject.CloneTest;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class Test02 {
public static void main(String[] args) {
//创建ArrayList集合
List<String> list = new ArrayList<>();
//添加100W条数据
for (int i = 0; i < 1000000; i++) {
list.add(i+"a");
}
//测试随机访问时间
long startTime = System.currentTimeMillis();
for (int i = 0; i < list.size(); i++) {
//取出集合的每一个 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 755
755










 到【灌水乐园】发言
到【灌水乐园】发言









