



大数据专业的同学有没有在初次学习Spark大数据分析的时候,老是搞不清楚Scala版本与Spark的哪个版本兼容,该分别使用哪一个版本呢?还有,假如你是用的是Maven管理依赖的话,是不是不知道该下载哪个Maven安装包呢?这些问题这篇文章帮你解答!!!
1、首先我们来看如何看Scala版本与Spark版本是否兼容
我们打开下面这个网址:
Maven Repository: Search/Browse/Explore
打开如下图所示,这个网址用于查所需要的依赖如何在IDEA中的pom.xml中写,我们也可用来查看Scala版本与Spark版本是否兼容,我们在如图的搜索框中输入spark并回车搜索
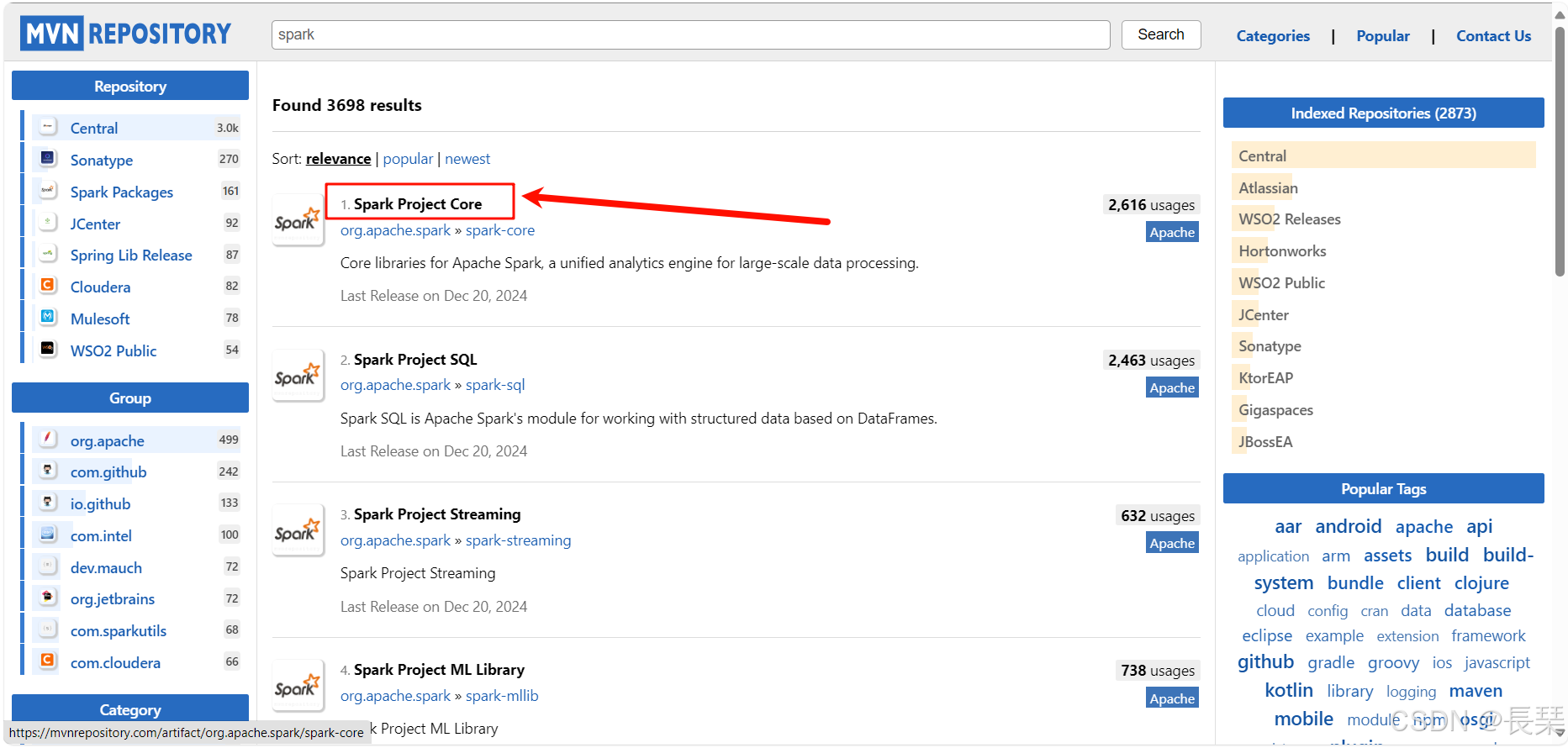
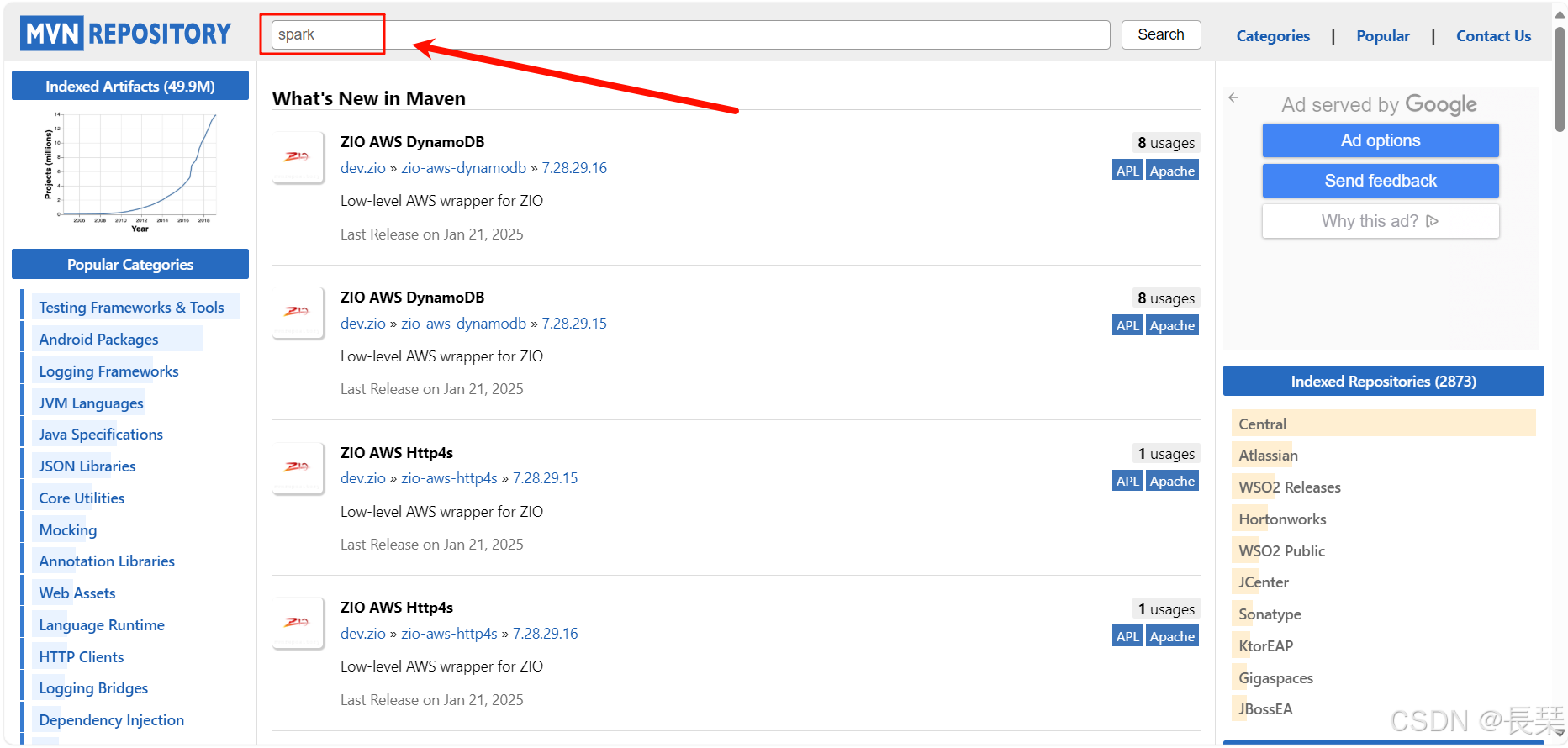 得到如下结果,我们点开Spark-core这个,就可以看到如何在pom.xml中写Spark-core的配置了,如果需要你也可以看到Spark SQL、Spark Streaming等都有,可以自行查看
得到如下结果,我们点开Spark-core这个,就可以看到如何在pom.xml中写Spark-core的配置了,如果需要你也可以看到Spark SQL、Spark Streaming等都有,可以自行查看
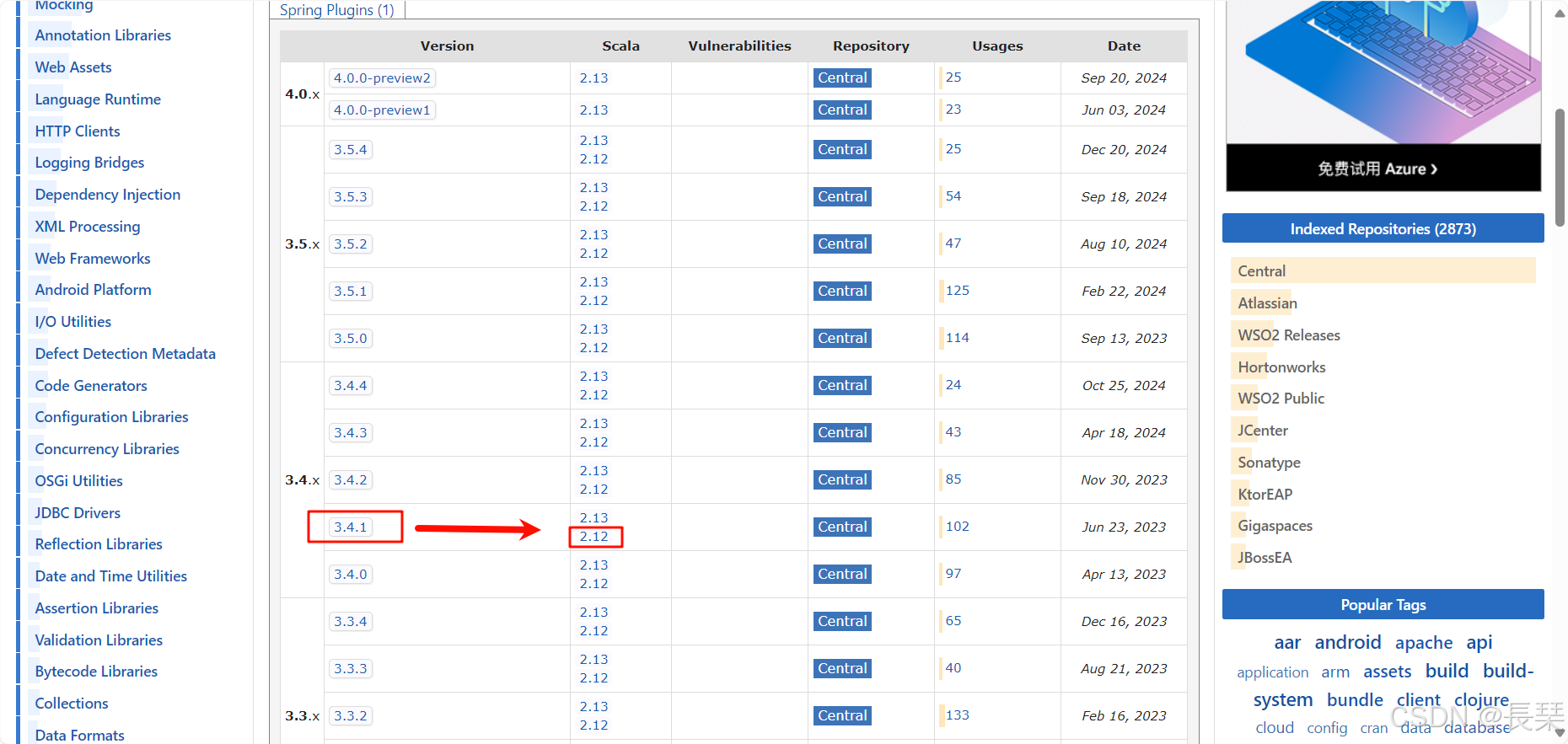
 进去后下滑会看到相关的Spark版本和Scala版本信息,我们以Spark3.4.1版本举例,它兼容的Scala版本是Scala2.12.x和Scala2.13.x版本,这里就解决了如何知道Spark版本与Scala版本是否兼容的问题
进去后下滑会看到相关的Spark版本和Scala版本信息,我们以Spark3.4.1版本举例,它兼容的Scala版本是Scala2.12.x和Scala2.13.x版本,这里就解决了如何知道Spark版本与Scala版本是否兼容的问题
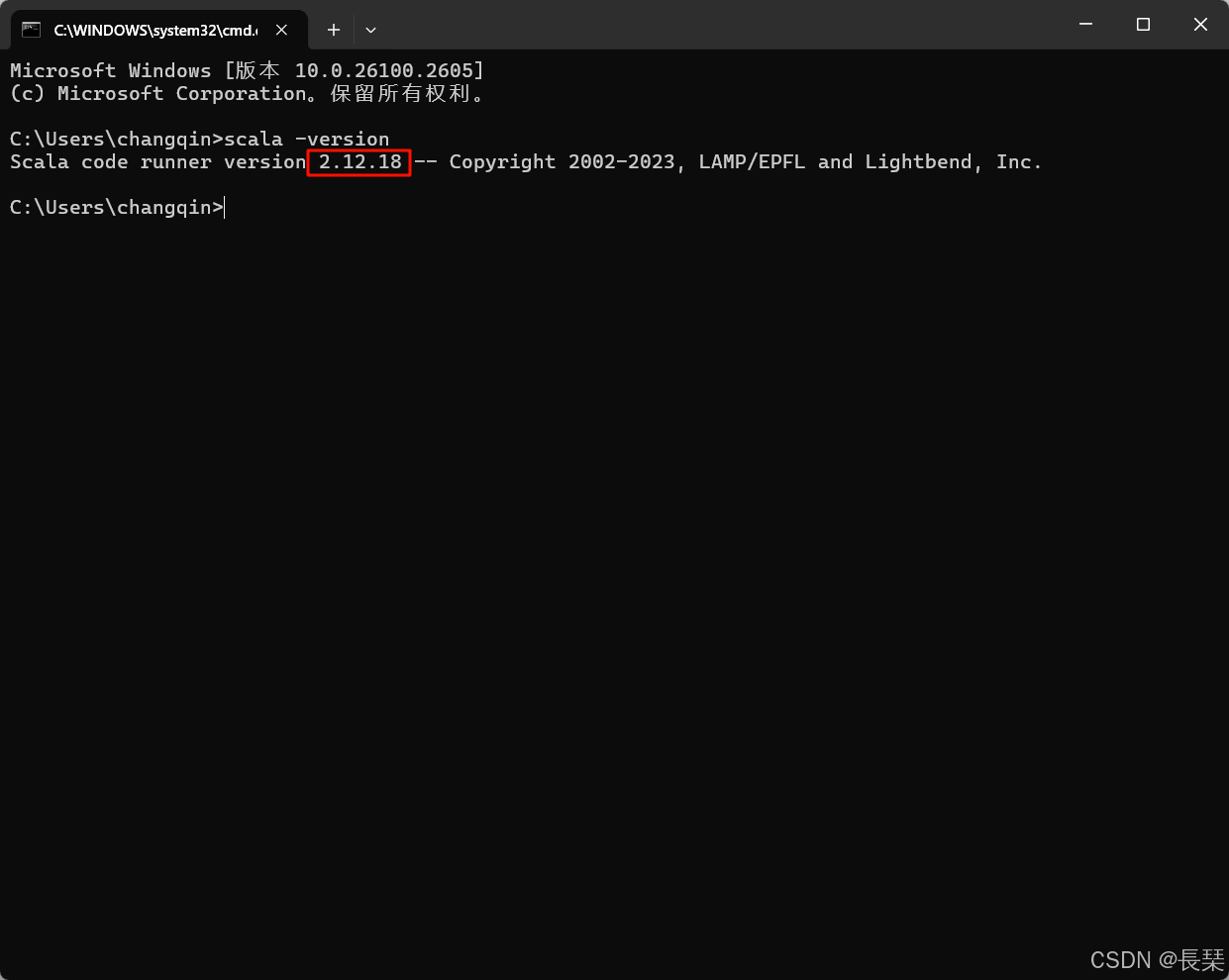
这里简单介绍一下如何查看自己安装的Scala版本,首先win+R然后输入cmd并回车
然后输入scala -version并回车,可以看到我的是2.12.18版本(属于上面表中的2.12),至于如何安装Scala并配置好环境变量可以去看我往期文章http://【用IDEA开发基于Spark3.4.1和Scala2.12.18的Spark项目的sbt方式配置,超详细哦 - 优快云 App】https://blog.youkuaiyun.com/weizhigongzi/article/details/144381627?sharetype=blog&shareId=144381627&sharerefer=APP&sharesource=weizhigongzi&sharefrom=link
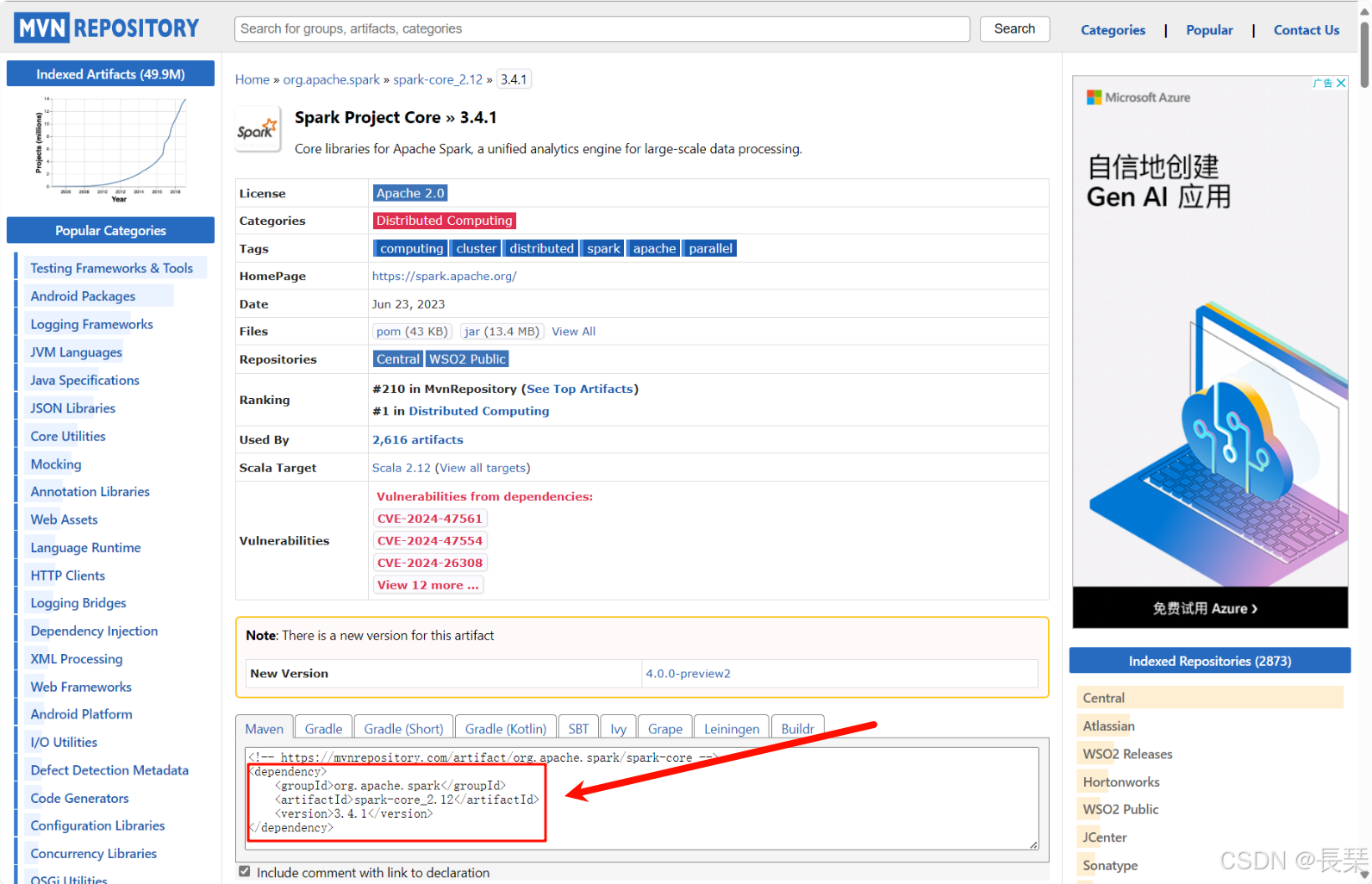
我们点击表中2.12的字样就可以跳转到如何写配置的界面,我们可以看到Spark3.4.1版本且用的是Scala2.12.x版本的Spark-core在pom.xml中应该如下写配置,其它组件的也是同样的查看方法
2、下面我们该介绍如何选择依赖管理工具Maven的版本了
我们打开Maven安装包的下载网址https://maven.apache.org/download.cgi
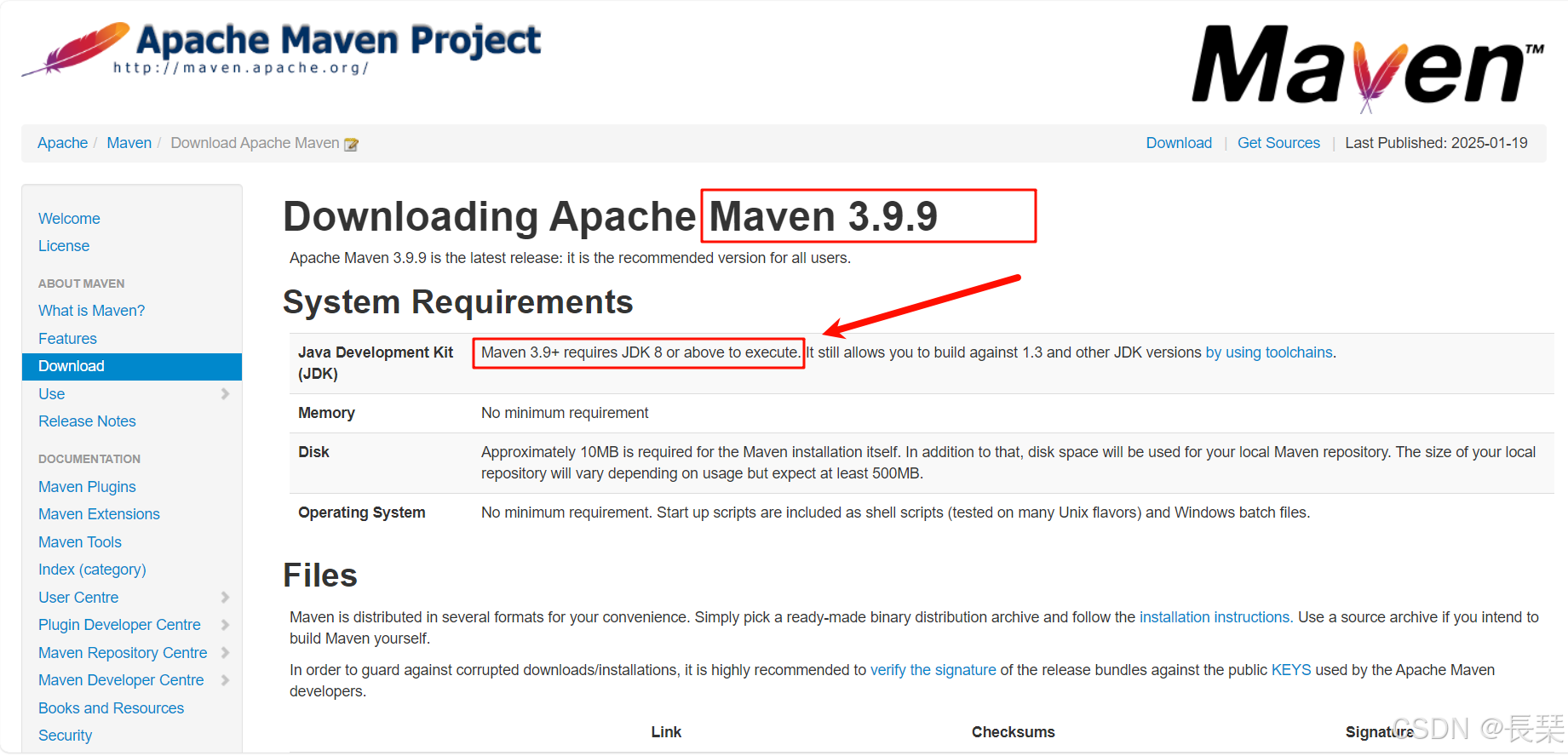
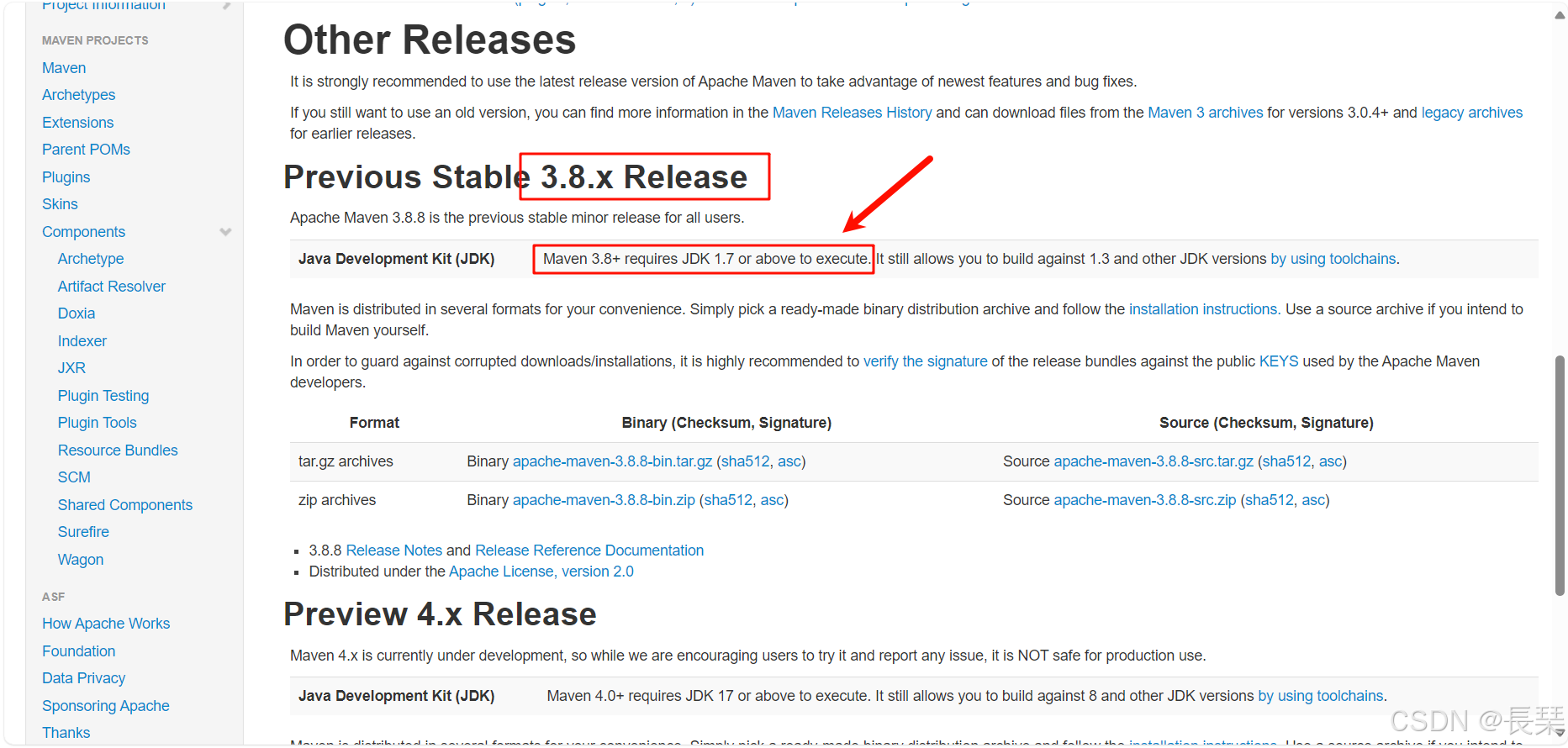
从上面的两张图中我们可以看到这时的最新版本为3.9.9版本,而它的要求里面也明确写了要JDK8及以上才行,而第二张图中的3.8.x版本要求则是JDK1.7及以上,这里说一下,当下载Maven安装包时,主要需要考虑的是Maven与你的JDK版本是否兼容,但还需要注意Maven版本与你的IDEA版本的兼容问题。Maven本身是一个项目管理工具,用于构建和管理Java项目,它的运行依赖于JDK。因此,确保Maven支持的JDK版本与你安装的JDK版本匹配是至关重要的,你不需要考虑Maven版本是否与你的Spark版本或Scala版本是否兼容。还有就是为啥上面的两个版本中一个是JDK8,一个是JDK1.7,如下,也就是说JDK8也可以叫做JDK1.8,而JDK1.7也可以叫做JDK7。
- 在Java 8(JDK8)及以前的版本中,版本号使用“1.x”的形式,如Java 1.4、Java 1.5、Java 1.6、Java 1.7。这种表示方法中,主版本号是1,后面跟着小数点和一个次版本号。
- 从Java 9开始,Oracle改变了版本号的表示方式,去掉了小数点,直接使用整数表示主版本号,如Java 9、Java 10、Java 11等。
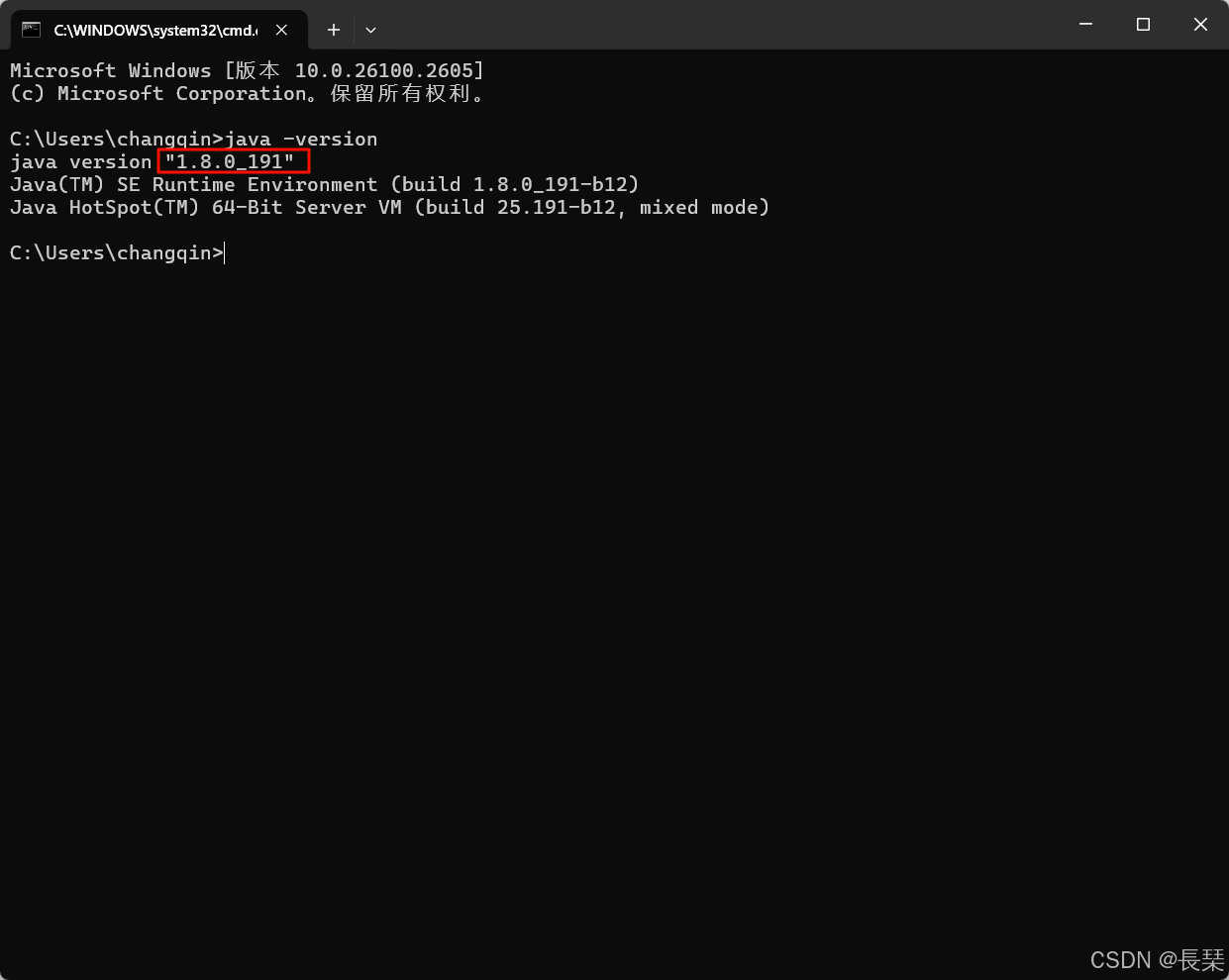
如何查看自己的JDK版本呢,win+R输入cmd并回车,然后再输入java -version查看JDK版本,可以看到我的是JDK1.8(也就是JDK8),是一个比较旧的版本了
常用的IDEA版本与Maven版本的兼容对照如下:
- 1.IDEA 2024 兼容maven 3.9.6及之前的所用版本
- 2.IDEA 2023 兼容maven 3.9.5及之前的所用版本
- 3.IDEA 2022 兼容maven 3.8.5及之前的所用版本
- 4.IDEA 2021 兼容maven 3.8.1及之前的所用版本
- 5.IDEA 2020 兼容Maven 3.6.3及之前所有版本
- 6.IDEA 2018 兼容Maven3.6.1及之前所有版本
我个人比较推荐使用3.5.4或者3.6.3版本,这两个版本都是我常用的两个版本且对大多数的IDEA版本都有很好的兼容性
至此,教程完毕!!!


















 1702
1702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











