




具体的错误演示大概如下所示:
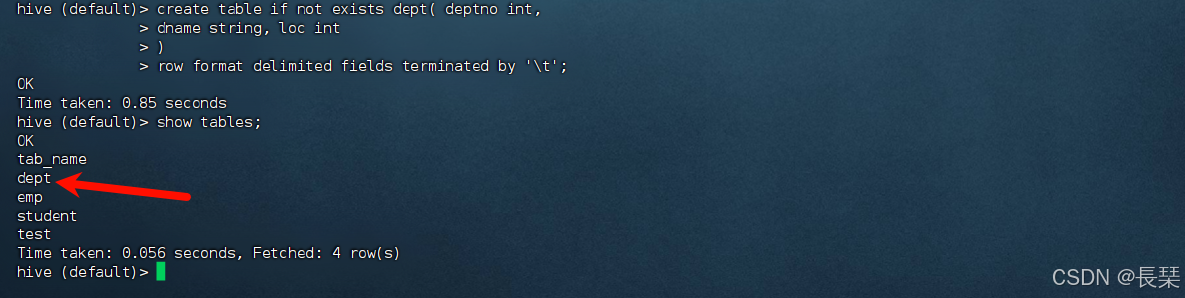
我们先创建一个表
create table if not exists dept( deptno int,
dname string, loc int
)
row format delimited fields terminated by '\t';
我们向表中插入几条数据,然后就会报错如下图
insert into table dept values(1,'accounting',1700),(0,'researc',180),(2,'sale',190),(0,'operations',1700);
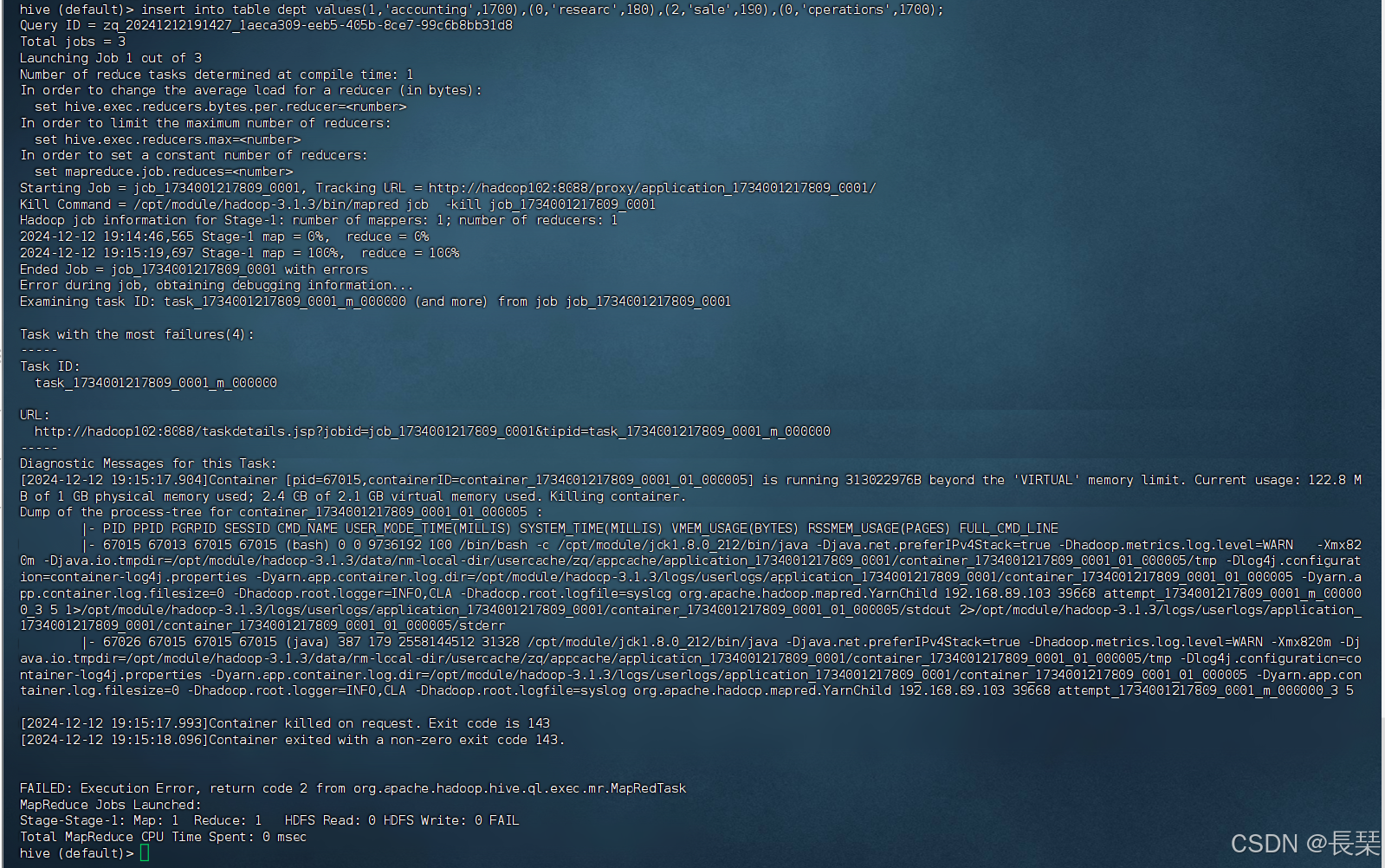
错误信息如下:
hive (default)> insert into table dept values(1,'accounting',1700),(0,'researc',180),(2,'sale',190),(0,'operations',1700);
Query ID = zq_20241212191427_1aeca309-eeb5-405b-8ce7-99c6b8bb31d8
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1734001217809_0001, Tracking URL = http://hadoop102:8088/proxy/application_1734001217809_0001/
Kill Command = /opt/module/hadoop-3.1.3/bin/mapred job -kill job_1734001217809_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2024-12-12 19:14:46,565 Stage-1 map
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1237
1237

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











