



注:本次我用到的Scala版本为Scala2.12.18版本,Spark版本为3.4.1版本,IDEA版本为IntelliJ IDEA 2019.2.3 x64版本(IDEA版本如果是其它的版本的话,可能有些许地方不一样,但都是同样的道理)
下载安装Scala2.12.18
The Scala Programming Language
打开上面的网址,点击install

跳转后找到下图所示的地方点进去

找到Scala2.12.18版本点进去

下滑找到Windows平台的zip包下载

下载下来解压到任意一个地方,最好是放在此处之后不再移动,因为要配环境变量,移动了后要重新配环境变量

如果是Win11系统请打开设置照下面的顺序点进去

在用户变量里点击新建(要配置系统变量也行,同样的操作)

找下面图中的内容输入变量名,点击浏览目录,到解压的目录的bin文件夹所在的同级路径下点击确定再确定


点击Path点编辑

点击新建,加入如图所示内容,点击确认、确认再确认即可

win+R输入cmd回车,在命令框输入scala -version回车,出现如图情况说明成功了(直接键入scala就可以在命令行写scala程序了,要退出来键入:quit回车即可,scala编程这里就不介绍了,感兴趣的可以自己去学习哦)

打开IDEA,然后安装scala插件,按如下图示,先点击配置(configure),然后点击插件(plugin)
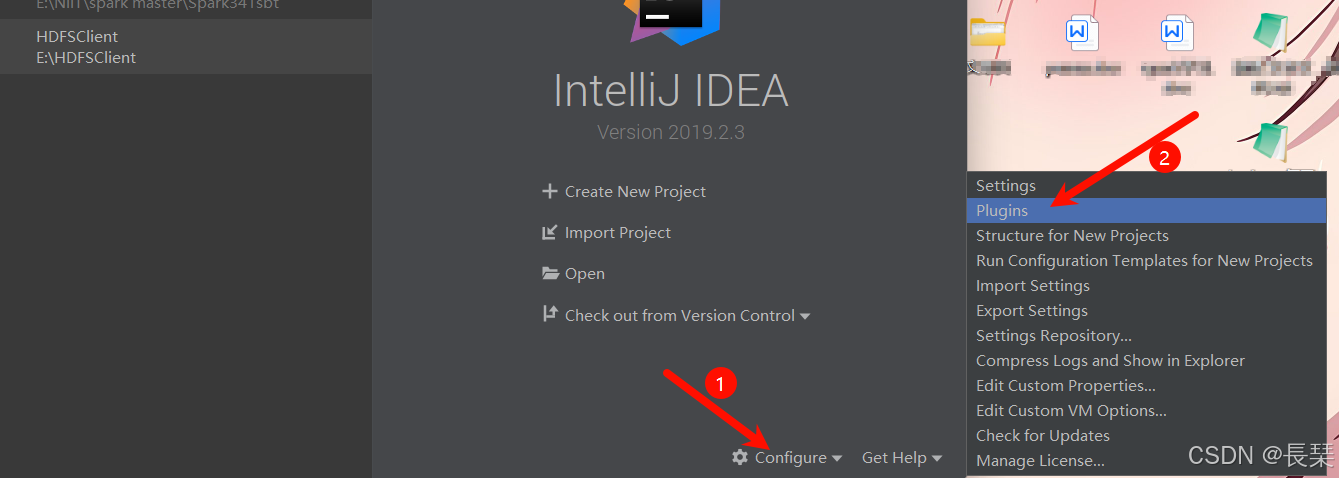
然后再搜索框输入scala,安装如下图标的插件,如果没有安装过会显示install按钮,如果已经安转过的就会像我的一样显示installed,安装好后点击OK回到主界面,然后重启IDEA
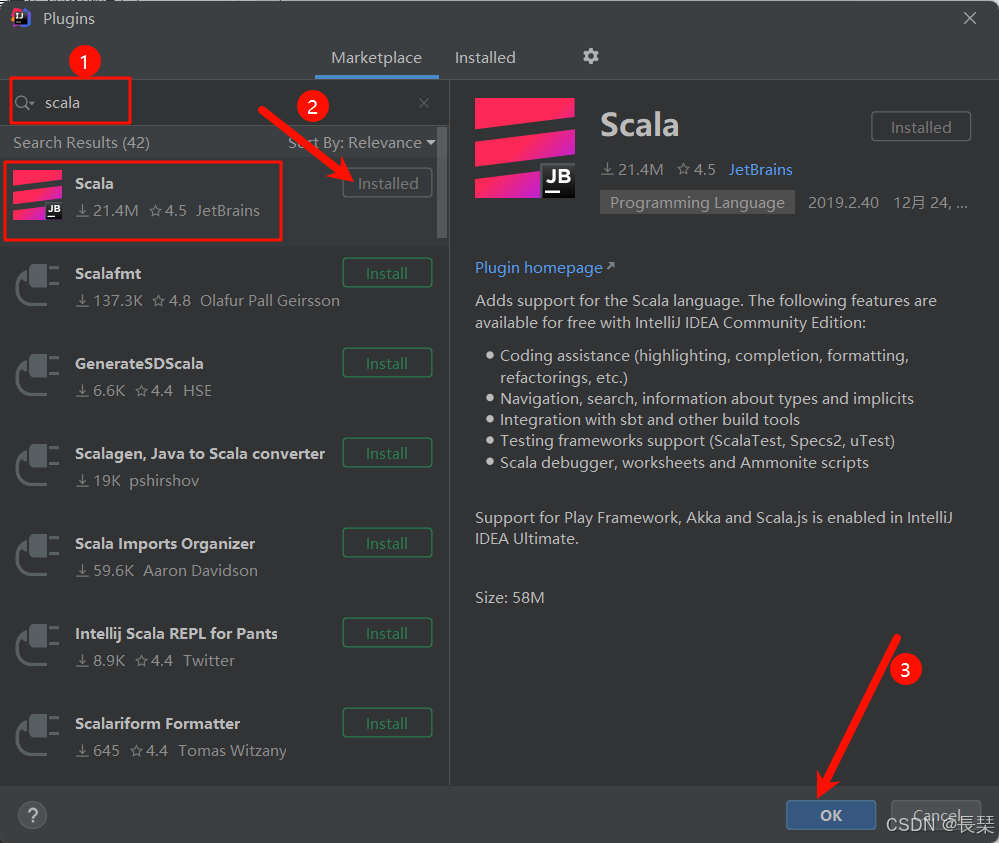
重新打开IDEA,新建项目

照下图点击操作

图中的名称、地址自己填,唯独注意的是jdk版本选择自己当前所安装的jdk(建议jdk1.8以上,如果没安装好jdk的请先安装好哦),sbt版本用默认就行(IDEA版本和我一样的就像我一样即可),scala版本选择2.12.18版本,最后点击finally

进去后等待构建成功

配置sbt依赖
这里只演示基于sbt添加spark-sql和spark-core依赖,其它的依赖自己添加即可
展开项目,在build.sbt文件里配置

添加如下配置,其中包含了将国外源改为国内的阿里源,然后点击如图所示位置下载依赖

name := "SparkSbt"
version := "0.1"
scalaVersion := "2.12.18"
lazy val root = (project in file("."))
.settings(
// 指定国内源
resolvers += "central" at "https://maven.aliyun.com/repository/public",
// 屏蔽默认的maven central源
externalResolvers := Resolver.combineDefaultResolvers(resolvers.value.toVector, mavenCentral = false),
updateOptions := updateOptions.value.withCachedResolution(true),
libraryDependencies += "org.apache.spark" %% "spark-core" % "3.4.1",
libraryDependencies += "org.apache.spark" %% "spark-sql" % "3.4.1"
)
等待成功即可

创建Spark项目结构如下,一般在scala下创建包,再在包中创建Spark项目

在创建好的包下创建项目


代码测试,写好后点一下代码界面,右键点运行

package Test
import org.apache.spark.{SparkConf, SparkContext}
object RDD {
def main(args:Array[String]): Unit ={
//创建SparkContext对象
val conf = new SparkConf().setAppName("RDDtest1").setMaster("local[2]")
val sc = new SparkContext(conf)
// Spark处理逻辑代码
val datas = Array(8,10,3,9,5)
val distData = sc.parallelize(datas)
val i: Int = distData.reduce((a, b) => a + b)
//关闭SparkContext对象
println(i)
sc.stop()
}
}
运行如下图,结果正确

至此,教程完毕。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











