



本文将带你深入探索这个激动人心的技术前沿,通过详细的Python代码实战和步骤讲解,一步步揭秘如何利用LangChain、RAG技术以及多智能体协作的理念,打造一个具备高级知识检索与问答能力的下一代机器人。我们不仅会展示核心组件的实现,还将探讨如何融入A2A/MCP等前沿协议的设计思想,展望其在构建更强大、更智能的AI系统中的广阔应用前景。无论你是AI开发者、产品经理,还是对前沿科技充满好奇心的探索者,这篇文章都将为你打开一扇通往未来智能知识交互的大门。准备好了吗?让我们一起启程,见证并参与这场AI赋能知识获取的深刻变革!
一、核心原理与架构:解构下一代知识问答机器人的“最强大脑”
要构建一个能够真正理解用户意图、精准检索信息并能与其他智能体高效协作的下一代知识问答机器人,我们需要深入理解其背后的核心技术原理和系统架构。这个“最强大脑”并非单一组件的堆砌,而是LangChain、RAG、AI智能体以及A2A/MCP等前沿协议协同作用的有机整体。
1.1 LangChain:智能应用的“神经中枢”
LangChain框架是整个系统的基石,它扮演着“神经中枢”的角色,负责连接和编排所有组件。其核心价值在于:
- 模块化与可组合性:LangChain提供了丰富的模块,如LLMs(大语言模型封装)、Chains(调用序列)、Indexes(数据结构化与检索)、Agents(智能体)、Memory(记忆模块)和Callbacks(回调系统)。这些模块可以像乐高积木一样灵活组合,快速构建出复杂的AI应用。
- LLM的强大驱动:LangChain使得与各种强大的LLM(如OpenAI的GPT系列、Anthropic的Claude、Google的Gemini等)的交互变得异常简单。LLM是智能体进行自然语言理解、推理、决策和内容生成的核心引擎。
- 工具(Tools)的集成:智能体需要与外部世界交互,执行特定的操作。LangChain允许开发者轻松定义和集成各种工具,例如搜索引擎、数据库查询器、代码执行器、API调用器等。智能体可以根据任务需求,自主选择并使用这些工具。
- 智能体(Agents)的实现:LangChain提供了构建智能体的核心机制。智能体能够接收用户输入,通过LLM进行思考和规划,决定调用哪个工具以及如何调用,然后观察工具的输出,并根据观察结果进行下一步行动,直到任务完成。常见的智能体类型如ReAct(Reasoning and Acting)Agent,通过“思考-行动-观察”的循环来解决问题。
在我们的知识问答机器人中,LangChain将负责:
- 接收用户的自然语言提问。
- 驱动核心LLM进行意图理解和任务拆解。
- 协调RAG流程的执行(调用检索工具)。
- 管理智能体与工具的交互。
- (在多智能体场景下)处理与其他智能体的通信(借助A2A协议的理念)。
1.2 RAG:为智能体注入“知识活水”
检索增强生成(RAG)是提升LLM回答质量和解决其“知识截止”问题的关键技术。其核心思想是在LLM生成回答之前,先从一个或多个外部知识源中检索与用户问题最相关的信息,并将这些信息作为上下文(Context)提供给LLM。
RAG的工作流程通常包括以下步骤:
- 知识库构建(Indexing/Embedding):
- 数据加载(Loading):从各种来源(如PDF、TXT、DOCX、网页、数据库等)加载原始文档。
- 文本分割(Splitting):将加载的文档分割成较小的文本块(Chunks),以便于后续的嵌入和检索。合适的分割策略对RAG效果至关重要。
- 向量嵌入(Embedding):使用预训练的文本嵌入模型(如OpenAI的
text-embedding-ada-002、Sentence Transformers等)将每个文本块转换为高维向量。这些向量能够捕捉文本的语义信息。 - 向量存储(Storing):将文本块及其对应的向量存储到专门的向量数据库(Vector Store/Vector Database)中,如FAISS、ChromaDB、Pinecone、Weaviate等。向量数据库支持高效的相似性搜索。
- 检索与生成(Retrieval & Generation):
- 用户提问(Query):用户提出问题。
- 查询向量化(Query Embedding):将用户的问题也通过同样的嵌入模型转换为查询向量。
- 相似性搜索(Similarity Search):在向量数据库中,使用查询向量搜索与之最相似(语义上最相关)的文本块向量,并召回对应的文本块。常用的相似性度量方法有余弦相似度、欧氏距离等。
- 上下文构建(Context Augmentation):将检索到的相关文本块组合起来,形成一个丰富的上下文信息。
- 增强生成(Augmented Generation):将原始的用户问题和检索到的上下文信息一起输入给LLM,提示LLM基于这些信息生成回答。这使得LLM的回答更加精准、具体,并能引用外部知识。
在我们的知识问答机器人中,RAG模块将确保智能体能够访问并利用最新的、领域特定的知识,从而提供远超通用LLM能力的回答。
1.3 AI智能体:自主决策与行动的执行者
AI智能体是系统的核心执行单元,它不仅仅是被动地响应指令,更具备一定程度的自主决策和行动能力。基于LangChain构建的智能体通常具备以下特征:
- 目标驱动:智能体被赋予一个或多个目标(例如,回答用户的问题、完成一项任务)。
- 环境感知:智能体能够感知其所处的环境,包括用户的输入、工具的输出以及其他智能体的状态(在多智能体系统中)。
- 规划与推理:智能体利用LLM的推理能力,根据当前目标和环境信息,规划实现目标的步骤序列。
- 工具使用:智能体能够选择并使用预定义的工具来获取信息或执行操作。例如,一个知识问答智能体可能会使用“RAG检索工具”来查询知识库,使用“计算器工具”来进行数学运算,或使用“搜索引擎工具”来获取实时信息。
- 学习与适应(高级特性):更高级的智能体可能具备从经验中学习和适应新情况的能力,但这通常需要更复杂的架构和训练机制。
在我们的系统中,核心的知识问答智能体将负责:
- 理解用户的复杂查询意图。
- 决定何时以及如何使用RAG检索工具来获取相关知识。
- 如果需要,调用其他辅助工具(如澄清问题、翻译等)。
- 整合检索到的信息和LLM的生成能力,形成最终答案。
1.4 多智能体协作:释放集体智慧
当单个智能体的能力不足以应对复杂任务时,多智能体协作就显得尤为重要。一个复杂的知识问答场景可能需要不同专长的智能体协同工作:
- 用户交互智能体:负责与用户直接沟通,理解用户需求,并将任务分发给其他智能体。
- RAG检索智能体:专门负责高效地从大规模知识库中检索信息。
- 数据分析智能体:如果问题涉及到数据分析,该智能体可以处理和解释数据。
- 领域专家智能体:针对特定领域(如法律、医疗、金融)的问题,可以有专门训练的智能体提供深度解答。
- 任务规划与协调智能体:在更复杂的系统中,可能需要一个“总指挥”智能体来协调其他智能体的工作流程。
1.5 A2A与MCP协议:赋能高效协作与互操作
为了实现多智能体之间的高效协作和工具的标准化调用,A2A(Agent-to-Agent)和MCP(Model Context Protocol)等前沿协议提供了重要的支撑:
A2A (Agent-to-Agent) Protocol:
- 核心目标:建立跨智能体的标准化通信协议,实现异构智能体间的互发现、互理解与互操作
关键要素:
- 服务发现机制(Agent Discovery)
- 标准消息协议(JSON-RPC/Protobuf)
- 能力描述框架(OWL-S扩展)
- 会话生命周期管理
应用场景:当知识问答系统需要调用外部专业智能体(如法律咨询、医疗诊断智能体)时,A2A协议可确保:
- 智能体能力的自动发现与验证
- 跨平台的任务委派与结果整合
- 会话状态的持久化与恢复
MCP (Model Context Protocol):
- 核心目标:建立模型与工具间的标准化交互规范,实现工具生态的解耦与即插即用
关键要素:
- 工具元数据描述
- 上下文传递规范(含多模态支持)
- 动态参数验证机制
- 错误处理标准化(RFC7807)
应用场景:当系统需要集成RAG检索、计算器等工具时,MCP协议可支持:
- 工具的自动注册与版本管理
- 输入输出的类型安全验证
- 跨模型的工具复用
系统整体架构设想图:
graph TD
User[用户] -->|自然语言提问| UIA[用户交互智能体]
subgraph "知识问答系统核心"
UIA -->|任务解析| CoreLLM[核心LLM]
CoreLLM -->|决策规划| UIA
UIA -->|A2A协议\n服务发现| SA1[法律智能体]
UIA -->|A2A协议\n任务委派| SA2[医疗智能体]
UIA -->|MCP调用\n参数校验| RAG[RAG检索工具]
RAG -->|向量查询| DB[(向量数据库)]
DB -->|语义匹配结果| RAG
RAG -->|结构化上下文| UIA
UIA -->|MCP调用\n工具组合| Tools[[工具集群]]
Tools --> Calc[计算器]
Tools --> Search[搜索引擎]
end
subgraph "知识库构建流水线"
Docs[原始文档] -->|预处理| Pipeline[嵌入流水线]
Pipeline -->|向量化存储| DB
end
UIA -->|自然语言回答| User
classDef agent fill:#f9f,stroke:#333,stroke-width:2px;
classDef tool fill:#ccf,stroke:#333,stroke-width:1px;
classDef llm fill:#9cf,stroke:#333,stroke-width:2px;
classDef db fill:#eee,stroke:#333,stroke-width:1px,dashed;
classDef protocol fill:#ff9,stroke:#333,stroke-width:1px;
class UIA,SA1,SA2 agent;
class RAG,Tools,Calc,Search tool;
class CoreLLM llm;
class DB db;
class A2A,MCP protocol;
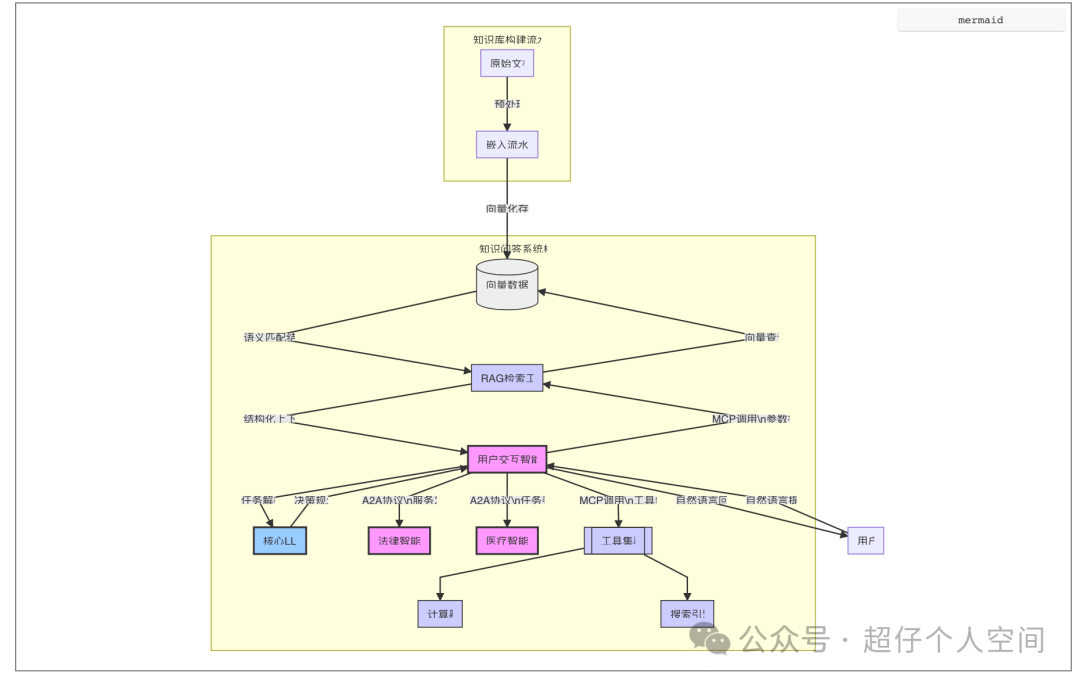
在这个架构中,用户通过用户交互智能体(一个核心的LangChain Agent)进行提问。该智能体利用LLM进行理解和规划,决定是直接回答、调用RAG工具从向量数据库检索知识、调用其他通用工具,还是通过A2A协议与其他专业智能体协作。MCP协议则可以用于规范化工具的调用接口。最终,整合所有信息后,由LLM生成高质量的答案返回给用户。
理解了这些核心原理和架构,我们就能更有针对性地进行后续的代码实战,一步步构建出这个强大的下一代知识问答机器人。
二、实战演练:用Python代码点亮下一代知识问答机器人
理论的阐述为我们描绘了下一代知识问答机器人的宏伟蓝图,现在,让我们卷起袖子,通过具体的Python代码示例,一步步点亮这个智能系统的核心组件。我们将重点演示如何构建一个基础的RAG流程,然后将其集成到一个LangChain智能体中,并探讨如何融入A2A/MCP的协作理念。
环境准备:
在开始之前,请确保你的Python环境已经就绪,并安装了必要的库。你可以通过pip轻松安装它们:
pip install langchain langchain-openai openai chromadb sentence-transformers tiktoken pypdf unstructured -q
# langchain: 核心框架
# langchain-openai: OpenAI的LLM和Embedding模型接口
# chromadb: 一个开源的向量数据库,用于存储文本嵌入
# sentence-transformers: 用于本地文本嵌入(如果不想用OpenAI的)
# tiktoken: OpenAI用于计算token的库
# pypdf: 用于加载PDF文档
# unstructured: 用于加载多种非结构化文档
同时,你需要在项目根目录下创建一个.env文件(或直接在代码中设置环境变量),并填入你的OpenAI API密钥:
OPENAI_API_KEY="your_openai_api_key_here"
2.1 构建RAG流程:从文档到可检索知识
我们的第一步是构建一个RAG流程,它能将原始文档处理成可供LLM检索和利用的知识。
步骤1:加载并分割文档
假设我们有一些本地的PDF或TXT文档作为知识源。
# rag_pipeline/document_processor.py
importos
fromdotenvimportload_dotenv
fromlangchain_community.document_loadersimportPyPDFLoader, TextLoader
fromlangchain.text_splitterimportRecursiveCharacterTextSplitter
load_dotenv()
# 示例:加载单个PDF文档
file_path = "./sample_document.pdf"# 替换成你的文档路径
# 创建一个虚拟的sample_document.pdf用于演示
ifnotos.path.exists(file_path):
try:
fromreportlab.pdfgenimportcanvas
c = canvas.Canvas(file_path)
c.drawString(100, 750, "这是第一页的示例内容,关于LangChain和RAG技术。")
c.drawString(100, 700, "LangChain是一个强大的框架,用于构建LLM应用。")
c.showPage()
c.drawString(100, 750, "RAG通过检索增强生成,提升LLM的回答质量。")
c.drawString(100, 700, "AI智能体可以利用RAG技术提供更精准的知识服务。")
c.save()
print(f"创建演示PDF: {file_path}")
exceptImportError:
print("请安装reportlab以创建演示PDF: pip install reportlab")
# 如果没有reportlab,可以手动创建一个简单的txt文件作为知识源
ifnotos.path.exists("sample_document.txt"):
withopen("sample_document.txt", "w", encoding="utf-8") asf:
f.write("这是示例文本内容,关于LangChain和RAG技术。\n")
f.write("LangChain是一个强大的框架,用于构建LLM应用。\n")
f.write("RAG通过检索增强生成,提升LLM的回答质量。\n")
f.write("AI智能体可以利用RAG技术提供更精准的知识服务。\n")
file_path = "./sample_document.txt"
print(f"创建演示TXT: {file_path}")
else:
file_path = "./sample_document.txt"
iffile_path.endswith(".pdf") andos.path.exists(file_path):
loader = PyPDFLoader(file_path)
eliffile_path.endswith(".txt") andos.path.exists(file_path):
loader = TextLoader(file_path, encoding="utf-8")
else:
print(f"示例文件 {file_path} 不存在或格式不支持,请创建它或修改路径。")
exit()
documents = loader.load()
# 分割文档成小块 (Chunks)
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
docs_chunks = text_splitter.split_documents(documents)
print(f"文档已加载并分割成 {len(docs_chunks)} 个文本块。")
# print(f"第一个文本块内容: \n{docs_chunks[0].page_content}")
步骤2:文本嵌入与向量存储
接下来,我们将这些文本块转换为向量,并存储到ChromaDB中。
# rag_pipeline/vector_store_builder.py
# (续上文 document_processor.py 中的 docs_chunks)
fromlangchain_openaiimportOpenAIEmbeddings
fromlangchain_community.vectorstoresimportChroma
# 初始化嵌入模型
embeddings_model = OpenAIEmbeddings()
# 将文本块嵌入并存储到ChromaDB
# persist_directory指定了向量数据库在磁盘上的存储位置,如果不存在会自动创建
vector_store_path = "./chroma_db_store"
vector_store = Chroma.from_documents(
documents=docs_chunks,
embedding=embeddings_model,
persist_directory=vector_store_path
)
vector_store.persist() # 持久化到磁盘
print(f"文本块已嵌入并存储到 ChromaDB: {vector_store_path}")
# 后续可以这样加载已存在的向量数据库
# vector_store_loaded = Chroma(persist_directory=vector_store_path, embedding_function=embeddings_model)
# print("已从磁盘加载向量数据库。")
现在,我们已经有了一个包含文档知识的向量数据库,可以用于后续的检索。
2.2 构建LangChain智能体:集成RAG能力的问答助手
我们将创建一个LangChain智能体,它能够使用我们刚刚构建的RAG流程(通过其检索器)作为工具来回答问题。
步骤1:创建RAG检索器工具
# agents/rag_qa_agent.py
importos
fromdotenvimportload_dotenv
fromlangchain_openaiimportChatOpenAI, OpenAIEmbeddings
fromlangchain_community.vectorstoresimportChroma
fromlangchain.tools.retrieverimportcreate_retriever_tool
fromlangchain.agentsimportAgentExecutor, create_openai_functions_agent# 使用OpenAI Functions Agent
fromlangchain_core.promptsimportChatPromptTemplate, MessagesPlaceholder
fromlangchain_core.messagesimportHumanMessage, AIMessage
load_dotenv()
# 加载之前创建的向量数据库和嵌入模型
vector_store_path = "./chroma_db_store"
embeddings_model = OpenAIEmbeddings()
ifnotos.path.exists(vector_store_path):
print(f"错误:向量数据库路径 {vector_store_path} 不存在。请先运行RAG流程构建部分。")
exit()
vector_store_loaded = Chroma(persist_directory=vector_store_path, embedding_function=embeddings_model)
retriever = vector_store_loaded.as_retriever(search_kwargs={"k": 3}) # k表示检索最相关的3个文档块
# 创建一个检索器工具
# 这个工具允许智能体使用我们的RAG检索器
retriever_tool = create_retriever_tool(
retriever,
"knowledge_base_retriever", # 工具名称
"Searches and returns relevant information from the knowledge base about LangChain, RAG, and AI agents."# 工具描述,告诉智能体何时使用它
)
tools = [retriever_tool]
步骤2:初始化LLM和智能体
我们将使用OpenAI的gpt-3.5-turbo模型,并创建一个能够使用OpenAI Functions的智能体,这种智能体在工具调用方面表现优秀。
# (续上文 rag_qa_agent.py)
# 初始化LLM
llm = ChatOpenAI(model="xxxxxx", temperature=0)
# 构建智能体的提示 (Prompt)
# 我们需要一个包含聊天历史和占位符的提示模板,以便智能体能够进行多轮对话
prompt_template = ChatPromptTemplate.from_messages([
("system", "You are a helpful assistant that answers questions based on a knowledge base. Use the 'knowledge_base_retriever' tool when necessary."),
MessagesPlaceholder(variable_name="chat_history", optional=True),
("human", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad"), # 用于存储智能体思考过程和工具调用结果
])
# 创建智能体
# create_openai_functions_agent 会根据LLM、工具和提示来构建智能体的核心逻辑
agent = create_openai_functions_agent(llm, tools, prompt_template)
# 创建智能体执行器
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True, handle_parsing_errors=True)
# 模拟聊天历史 (可选,用于多轮对话测试)
chat_history = []
# 测试智能体
if__name__ == "__main__":
print("你好,我是基于知识库的问答助手,有什么可以帮您?(输入 '退出' 来结束对话)")
whileTrue:
user_input = input("用户: ")
ifuser_input.lower() in ["退出", "exit", "quit"]:
print("问答助手:再见!")
break
response = agent_executor.invoke({
"input": user_input,
"chat_history": chat_history
})
print(f"问答助手: {response['output']}")
# 更新聊天历史
chat_history.append(HumanMessage(content=user_input))
chat_history.append(AIMessage(content=response['output']))
# 保持聊天历史在一定长度内,避免过长
iflen(chat_history) >6:
chat_history = chat_history[-6:]
运行与解读:
当你运行rag_qa_agent.py并提问(例如:“LangChain是什么?”或“RAG技术如何提升LLM性能?”),你会看到智能体(因为设置了verbose=True)的思考过程:
- 它会分析你的问题。
- 它会意识到需要从知识库中获取信息,因此决定调用
knowledge_base_retriever工具。 - 工具执行检索,从ChromaDB中找到相关的文档块。
- 智能体接收到检索结果,并将其与原始问题一起交给LLM。
- LLM基于这些信息生成最终答案。
这个例子清晰地展示了如何将RAG流程无缝集成到LangChain智能体中,使其具备了基于特定知识源进行问答的能力。
2.3 展望A2A/MCP:构建协作式知识问答网络(概念性探讨)
虽然完整的A2A/MCP代码实现超出了本文的篇幅,但我们可以探讨其核心理念如何赋能更高级的协作式知识问答网络。
场景设想:
假设我们的主RAG问答智能体(MainQAAgent)在处理一个非常专业的问题时(例如,“请分析一下XYZ公司最近的财报,并预测其下一季度的营收趋势”),意识到自己知识库中的信息不足或缺乏专业的分析能力。此时,它可以考虑将任务委托给一个专门的“财务分析智能体”(FinancialAnalystAgent)。
A2A协议的简化模拟:
我们可以用Python类和方法调用来模拟这种智能体间的通信。
# conceptual_collaboration/multi_agent_simulation.py
classBaseA2AAgent:
def__init__(self, agent_id: str, description: str):
self.agent_id = agent_id
self.description = description# 描述智能体的能力,用于服务发现
defprocess_request(self, request_payload: dict, sender_agent_id: str) ->dict:
"""处理来自其他智能体的请求"""
raiseNotImplementedError
classFinancialAnalystAgent(BaseA2AAgent):
def__init__(self):
super().__init__("financial_analyst_001", "Performs financial analysis and forecasting.")
defprocess_request(self, request_payload: dict, sender_agent_id: str) ->dict:
print(f"[FinancialAnalystAgent] 收到来自 [{sender_agent_id}] 的请求: {request_payload}")
ifrequest_payload.get("task_type") == "ANALYZE_FINANCIALS":
company = request_payload.get("company_symbol")
# 此处应有调用真实数据源和分析模型的逻辑
# 为简化,我们返回一个模拟结果
analysis_result = f"对 {company} 的分析:营收预计增长5%,利润平稳。"
return {"status": "SUCCESS", "result": analysis_result, "confidence": 0.85}
return {"status": "ERROR", "message": "不支持的任务类型"}
classMainQAAgent:
def__init__(self, known_agents: list[BaseA2AAgent]):
self.agent_id = "main_qa_agent_001"
self.known_agents = {agent.agent_id: agentforagentinknown_agents}
# 在真实A2A中,这里会有服务发现机制
defhandle_complex_query(self, query: str):
print(f"[MainQAAgent] 处理复杂查询: {query}")
if"财报分析"inqueryand"XYZ公司"inquery: # 简单判断是否需要委托
print(f"[MainQAAgent] 检测到需要财务分析,尝试委托给财务分析智能体...")
financial_agent_id = "financial_analyst_001"# 假设已知其ID
iffinancial_agent_idinself.known_agents:
payload = {
"task_type": "ANALYZE_FINANCIALS",
"company_symbol": "XYZ"
}
# 模拟A2A消息发送与接收
response = self.known_agents[financial_agent_id].process_request(payload, self.agent_id)
print(f"[MainQAAgent] 收到财务分析结果: {response}")
returnresponse.get("result", "未能获取分析结果。")
else:
return"抱歉,找不到合适的财务分析智能体。"
else:
# 否则,使用自身的RAG能力处理 (代码略,参考2.2节)
return"正在使用本地知识库处理您的请求... (模拟RAG回答)"
if__name__ == "__main__":
financial_agent = FinancialAnalystAgent()
main_agent = MainQAAgent(known_agents=[financial_agent])
query1 = "LangChain是什么?"
query2 = "请帮我做XYZ公司的财报分析,并预测其趋势。"
print(f"\n用户查询: {query1}")
print(f"主问答智能体回复: {main_agent.handle_complex_query(query1)}")
print(f"\n用户查询: {query2}")
print(f"主问答智能体回复: {main_agent.handle_complex_query(query2)}")
MCP协议的融入思路:
MCP可以用来标准化FinancialAnalystAgent如何声明其ANALYZE_FINANCIALS能力(工具)。例如,它可以发布一个MCP兼容的工具描述,说明该工具需要company_symbol作为输入,并返回包含analysis_result和confidence的结构化输出。这样,MainQAAgent(如果集成了MCP客户端能力)就可以动态发现并以标准方式调用这个工具,而无需硬编码其接口细节。
虽然上述只是概念性的模拟,但它清晰地展示了通过定义标准化的接口和消息格式,不同的AI智能体可以如何协同工作,共同完成更复杂的知识问答任务。这正是A2A和MCP协议致力于实现的目标,也是下一代知识问答机器人发展的关键方向。
通过这些实战演练,我们不仅掌握了构建具备RAG能力的LangChain智能体的核心技术,也对未来多智能体协作的广阔前景有了更具体的认识。接下来,我们将进一步探讨这些技术的应用场景、面临的挑战以及未来的发展趋势。
三、应用场景、挑战与未来展望:智能知识问答的星辰大海
通过前面的原理剖析和代码实战,我们已经初步领略了LangChain、RAG与多智能体协作在构建下一代知识问答机器人方面的强大潜力。然而,这仅仅是冰山一角。这项融合技术的应用场景远不止于此,其未来发展也充满了无限的想象空间,当然,前进的道路上也伴随着诸多挑战。
3.1 广阔的应用场景:赋能千行百业的知识引擎
基于LangChain、RAG和智能体协作的知识问答机器人,凭借其深度理解、精准检索和智能协作能力,能够在众多领域发挥关键作用:
- 企业级智能知识库与客服系统:
- 内部知识管理:企业内部往往积累了海量的文档、手册、规章制度和历史案例。通过构建RAG驱动的智能问答系统,员工可以快速、准确地获取所需信息,极大提升工作效率和决策质量。例如,新人入职培训、复杂技术问题查询、合规性检查等。
- 智能客服与技术支持:面对客户的各种咨询和技术难题,智能问答机器人可以7x24小时提供即时、精准的解答,分担人工客服的压力。结合多智能体协作,机器人甚至可以处理更复杂的售后流程,如故障诊断、派单维修等,并通过A2A协议与内部工单系统、物流系统智能体联动。
- 专业领域(金融、法律、医疗)的辅助决策:
- 金融投研与风控:金融分析师可以利用该系统快速检索和分析海量财报、研报、市场动态和监管政策,辅助投资决策和风险评估。例如,快速了解某公司的财务状况、行业对比、相关新闻事件影响等。
- 法律咨询与案件分析:律师和法务人员可以通过自然语言查询法律条文、判例、司法解释,辅助案件准备和法律文书撰写。结合RAG,系统可以确保引用信息的准确性和时效性。
- 医疗诊断辅助与文献检索:医生可以利用该系统查询最新的医学文献、临床指南、药品信息,辅助诊断和治疗方案制定。RAG技术可以帮助从海量医学文本中提取关键证据。
- 教育与科研领域的个性化学习与研究助理:
- 个性化辅导与答疑:学生可以随时向智能问答机器人提问,获取针对性的学习资料和解题思路。系统可以根据学生的学习进度和理解程度,动态调整回答的深度和广度。
- 科研文献检索与综述生成:科研人员可以利用该系统快速梳理特定领域的文献脉络,自动生成文献综述的初稿,发现潜在的研究空白和交叉点。
- 内容创作与媒体行业的智能助手:
- 智能写作与事实核查:记者和编辑可以利用该系统快速收集背景资料、核查事实信息、甚至生成新闻稿件的初稿,提升内容生产的效率和准确性。
- 个性化内容推荐与问答互动:媒体平台可以集成此类智能问答机器人,为用户提供更具互动性和深度的内容消费体验,例如,针对某篇深度报道,用户可以就感兴趣的细节进行追问。
- 个人智能助理的知识增强:
- 未来的个人AI助理将不仅仅是任务执行者,更是知识伙伴。通过集成强大的RAG和多智能体协作能力,个人助理可以帮助用户学习新技能、规划复杂事务、解答生活中的各种疑问,成为真正的“第二大脑”。
3.2 面临的挑战:通往理想之境的必经之路
尽管前景光明,但在实现理想的下一代知识问答机器人的道路上,我们仍需克服诸多挑战:
- RAG的深度与广度平衡:
- 检索质量:如何确保检索到的信息既全面又精准,避免引入噪声或遗漏关键信息,是RAG系统持续优化的核心。这涉及到分块策略、嵌入模型的选择、检索算法的优化等多个方面。
- 知识更新与维护:外部知识库是动态变化的,如何高效地更新向量数据库,确保LLM获取的是最新信息,是一个工程难题。
- 复杂查询理解:对于高度模糊、多意图或需要多步推理的复杂查询,如何准确拆解并进行有效检索,对RAG系统提出了更高要求。
- 智能体的鲁棒性与可控性:
- 工具使用的幻觉:智能体有时可能会错误地选择或使用工具,或者对工具的输出产生误解。提升智能体在工具使用上的准确性和鲁棒性至关重要。
- 规划能力的局限:对于长程、复杂任务,当前智能体的规划能力仍有提升空间,容易陷入循环或过早放弃。
- 可解释性与可信度:智能体的决策过程往往像一个“黑箱”,如何让用户理解其行为逻辑,建立信任,是一个重要议题。
- 多智能体协作的复杂性:
- 通信效率与开销:智能体间的频繁通信可能带来显著的延迟和资源消耗。设计高效的A2A通信机制和消息格式非常关键。
- 任务分配与协调:在复杂的协作网络中,如何动态、合理地分配任务,协调不同智能体的行动,避免冲突和资源浪费,是一个核心挑战。
- 一致性与冲突解决:不同智能体可能基于不同的信息或模型产生矛盾的判断或行动建议,如何有效解决冲突,达成共识,需要精巧的机制设计。
- 安全与信任:在开放的多智能体环境中,如何确保参与智能体的身份可信、行为可控,防止恶意智能体的破坏,是构建可信协作生态的前提。
- 协议标准化与生态建设:
- MCP、A2A等协议虽然指明了方向,但其大规模推广和业界共识的形成仍需时日。一个繁荣、开放、可互操作的智能体和工具生态系统的建立,离不开统一标准和社区的共同努力。
- 成本与资源:
- 无论是训练和微调LLM,还是大规模部署向量数据库和运行多个智能体实例,都需要大量的计算资源和资金投入。如何优化成本,让这些先进技术惠及更多开发者和用户,是商业化落地的重要考量。
3.3 未来展望:迈向更智能、更自主的知识交互新范式
展望未来,LangChain、RAG与多智能体协作技术将朝着更加智能、自主和融合的方向发展,开启知识交互的全新范式:
- 更主动的智能体(Proactive Agents):未来的知识问答机器人将不仅仅被动等待用户提问,更能根据用户的上下文、历史行为和潜在需求,主动提供有价值的信息和建议,成为真正的“智能伙伴”。
- 自学习与自适应的RAG系统:RAG系统将具备更强的自学习能力,能够根据用户反馈和交互历史,自动优化检索策略、更新知识库、甚至微调嵌入模型,实现持续的性能提升。
- 深度融合的多模态知识交互:知识的载体远不止文本。未来的系统将能够处理和理解图像、音频、视频等多模态信息,实现更丰富、更自然的知识问答体验。
- 可解释与可信AI的进步:随着可解释AI(XAI)技术的发展,我们将能更好地理解智能体的决策过程,提升其透明度和可信度,让人类用户更放心地依赖和协作。
- Agent-as-a-Service与开放生态:随着A2A、MCP等协议的成熟,将涌现出大量提供特定能力(如特定领域知识检索、专业数据分析、复杂任务执行)的“智能体即服务”(Agent-as-a-Service)。开发者可以像调用API一样,按需组合和调用这些智能体服务,快速构建出强大的应用。
- 与人类更深度的协作(Human-Agent Teaming):未来的知识问答系统将更强调与人类用户的协同进化。智能体辅助人类完成复杂认知任务,人类的反馈和指导又帮助智能体提升能力,形成良性循环。
- 通往通用人工智能(AGI)的探索:虽然道阻且长,但构建能够理解复杂世界、掌握海量知识、并能与其他智能体高效协作的复杂AI系统,无疑是人类在探索通用人工智能道路上迈出的坚实一步。
总而言之,我们正处在一个激动人心的技术变革的开端。LangChain、RAG与多智能体协作的融合,正在为我们打开通往一个知识获取和利用效率呈指数级提升的未来的大门。虽然挑战重重,但每一次技术的突破都将带来无限的机遇。作为开发者、创新者和这个时代的见证者,我们有理由对这个充满潜力的领域保持高度的关注和积极的探索。
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~

👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。


👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。

👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。

👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。

👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!


















 3971
3971

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









