




AI芯片面临的困境
随着工艺制程的进步,当今 AI 芯片的算力每两年半翻一番,增长非常迅速。但即便如此,由于 AI 应用的算力需求每 3-4 个月就翻番,芯片算力提升很难支撑 AI 应用大规模落地。此外,芯片领域的摩尔定律有放缓趋势,且国内先进工艺发展受限,亟需寻找新途径来突破工艺封锁。
行业衡量 AI 算力时,主要关注单位资源下的应用算力,包括算法时间(例如每秒处理的图片数量)、架构能效(例如每焦耳能耗处理的图片数量)和工艺面积(每平方毫米芯片面积容纳的 AI 核心数量)。
其中,芯片研发侧更关注架构能效与工艺面积指标,而应用开发侧更关注算法时间这样的指标。硬件和软件侧关注的指标差异带来了一定的优化空间,例如,使用一个算力相对较低的 U280 FPGA 芯片,搭配量化稀疏优化就能获得 6 倍于 V100 GPU 的 AI 计算能耗比。
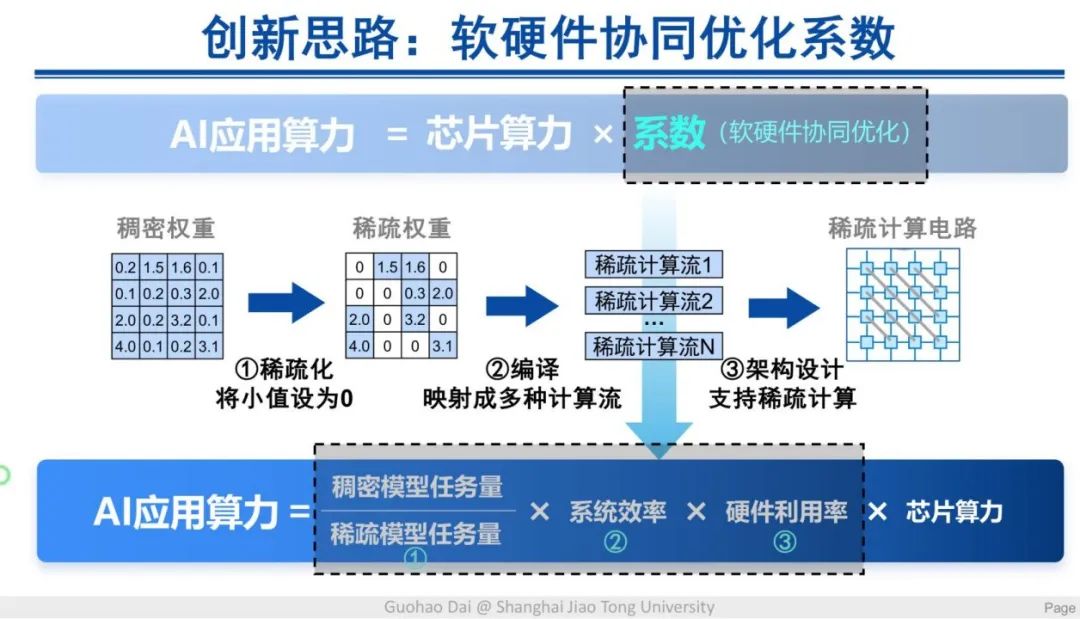
而稀疏计算是一种效果较好的软件优化方式,其流程是将一个稠密矩阵通过稀疏化的方式得出稀疏矩阵,再通过编译方法将其映射成不同的计算流,最终将这种计算流实现在硬件电路上。
但这一优化过程面临许多挑战,首先是稀疏化带来的精度损失,其次是编译过程中不同的稀疏数据对应的最优计算流各有差异,对编译方法提出了更高要求。最后,不同类型的稀疏数据所展现的非结构化稀疏数据的特性与结构化的硬件之间也存在很大矛盾。如何解决这些核心挑战,成为这一领域研究的重点。

方法论:稀疏计算范式
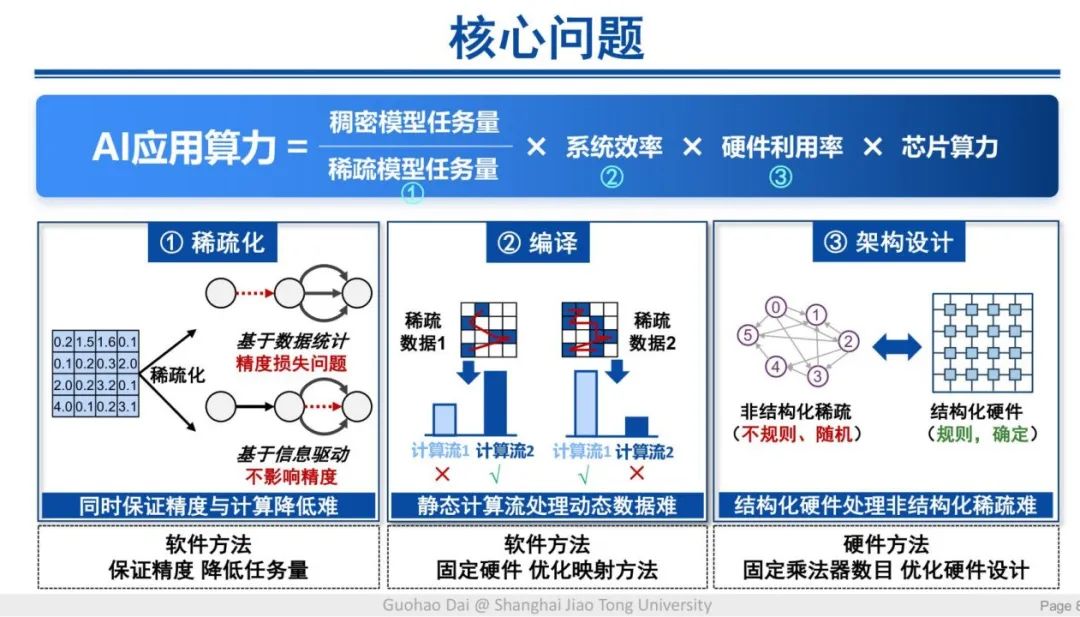
挑战一
传统的稀疏化方法一般采用权重剪枝等数据驱动手段,由于被剪枝的数据往往包含很多有用信息,因此这种方法很容易导致很大的精度损失,还会出现大量冗余计算。
面向这一挑战,信息驱动的稀疏化方法可以在兼顾模型精度的情况下,充分利用稀疏度来降低计算量。这里的稀疏化方法会提出稠密数据中包含有效信息的部分,或通过矩阵转置来提升稀疏效率。
挑战二
第二个挑战来自于不同稀疏数据与计算流之间的矛盾,使单一计算流难以充分利用硬件资源。同一个计算流对于不同类型的数据,平均的效率一般只有 80% 不到。针对这一挑战,团队提出了一种动态感知编译映射的新方法,即引入机器学习的方式,通过 AI 模型自适应地选择不同类型的计算流,适配不同类型的数据,从而大幅提升系统效率,部分场景甚至能接近理论最优水平。
挑战三
第三个挑战是稀疏任务的非结构化特征与硬件电路的结构化特征存在矛盾,导致硬件利用率低下。对此,团队采用结构化稀疏硬件的核心方法,即通过若干小的结构化稀疏来拼装成大的非结构化稀疏,可以实现较好的软硬协同优化效果。从微观层面来看,结构化的稀疏适合被硬件电路实现;从宏观层面来看,非结构化的稀疏又适合算法开发的软件需求。
总体而言,通过信息驱动的稀疏化方法可以将同等模型精度下的计算量降低 2 倍,通过动态感知编译映射方法可以将平均系统效率提升 2-4 倍,而结构化稀疏硬件可以将硬件利用率提升 2-8 倍。将以上三方面的工作结合起来,可以将同等硬件水平下的 AI 应用算例提升约 1 个数量级。

研究成果
系统优化
通过梳理过去行业中大模型推理引擎的发展并研究对比发现,当前模型的软件优化水平基本是趋同的,优化空间所剩不多。如果要进一步系统性地优化推理引擎,就要分析模型内部的计算逻辑。
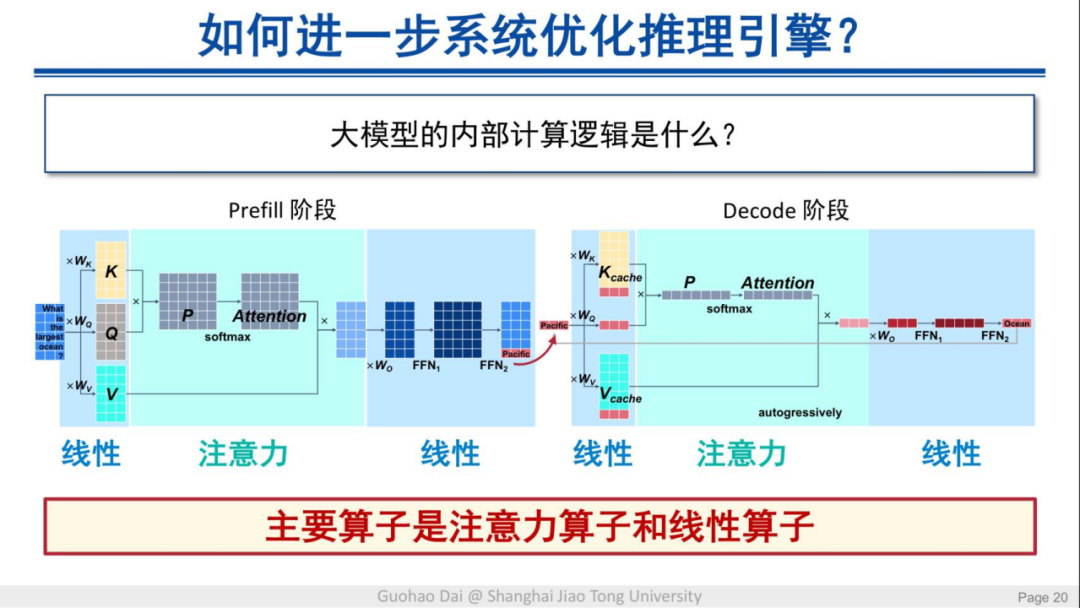
大模型主要的算子分别是注意力算子和线性算子。这些算子在模型内部基本都会表现成矩阵乘的形式,过去的优化工作主要是针对注意力算子和矩阵乘来做优化。目前,在模型的注意力和线性计算的过程中又发现了一些优化点。
论文:FlashDecoding++: Faster Large Language Model Inference with Asynchronization, Flat GEMM Optimization, and Heuristics,MLSys 24
在注意力算子优化方法中,要对算子分块并对每个分块来取局部最大值,再对这些局部最大值做统一处理。这一步骤引入了大量同步开销,每个块并不都需要取局部最大值,而只需在全局输入提前确定的最大值来引入异步操作,从而进一步降低延迟。另外,对于矮胖型的矩阵也可以引入矩阵乘优化,从而进一步加快模型计算。

模型软件性能优化虽然取得了不错的成果,但由于硬件层面的瓶颈日益明显,仅靠软件优化还是难以满足应用的算力需求。因此,研究者接下来的研究重点又转向了软硬件协同优化,通过联合数据信息和硬件信息来进一步释放芯片算力。
软硬件协同优化
软硬件协同优化的一个典型案例来自于微软亚洲研究院。
论文:FP8-LM: Training FP8 Large Language Models
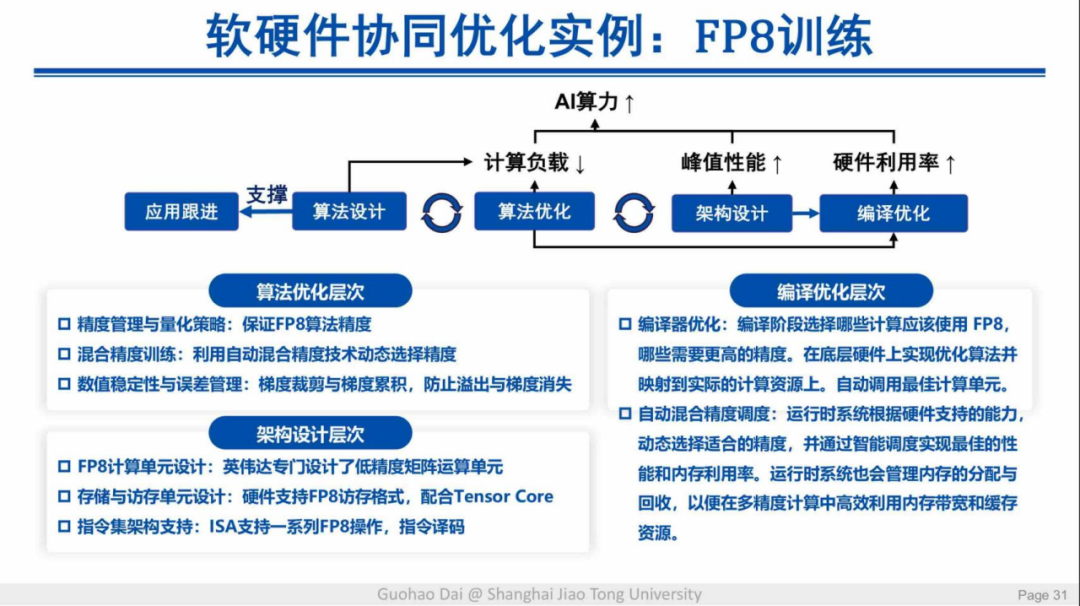
该案例结合了算法层面的优化与硬件架构的针对性设计,再加上编译层面的优化,用更少的 GPU 获得了更快的训练速度,整体的收敛性也有保证。
此外,团队还基于软硬件协同优化思想做了一系列工作。第一套工作涉及文生文和文生视频的模型。在大模型领域,文生文模型是典型的访存瓶颈应用,而视频生成模型是典型的计算瓶颈应用。这两类问题都可以通过稀疏方式来优化,分别降低缓存量和计算量的需求进而提高性能。
FlightLLM:大语言模型加速
对访存瓶颈应用的优化思想,主要是通过上文提到的灵活结构化稀疏硬件设计,同时结合非结构化与结构化的优势,从而在保证算法精度的同时实现硬件高效。基于这种思想,研究者提出了名为 FlightLLM的新方法。
论文:FlightLLM: Efficient Large Language Model Inference witha Complete Mapping Flow on FPGAs,FPGA 24
该方法的核心思想是可重构的稀疏 DSP 链,可以支持模型中不同算子的稀疏模式需求。
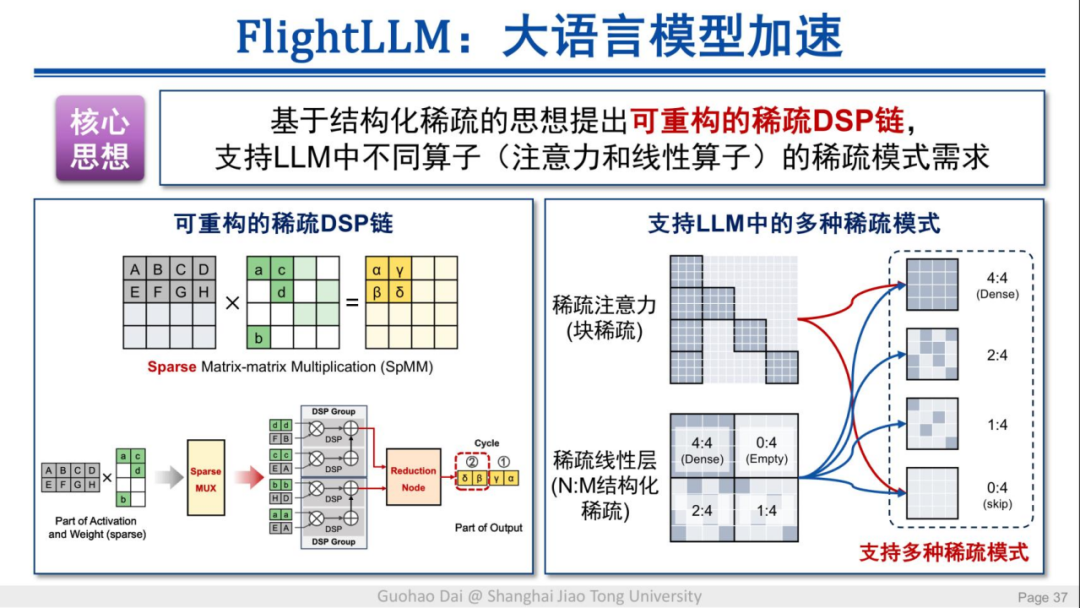
模型中的大量计算是通过 DSP 来完成的,通过可重构的稀疏 DSP 链,FPGA 芯片能将所有 decode 操作融合起来,从而有效降低访存需求。从最终的成果来看,单块 FPGA(16nm)就能实现 6 倍于 V100s GPU(12nm)的能效和 1.8 倍的性价比提升,端到端推理速度还快了 20%。
FlightVGM:文生视频加速
视频生成模型的工作机制与传统的视频编码相似,首先将输入的噪声视频进行分块处理,然后通过预测噪声不断地对视频去噪,最终生成视频。与传统视频编码不同的是,视频生成模型没有利用视频帧与帧之间的相似性。因此,团队将传统视频处理领域积累的经验运用在视频生成模型中,并提出了名为 FlightVGM 的方法。
论文:FlightVGM: Efficient Video Generation Model Inference withOnline Sparsification and Hybrid Precision on FPGAs,FGPA 25
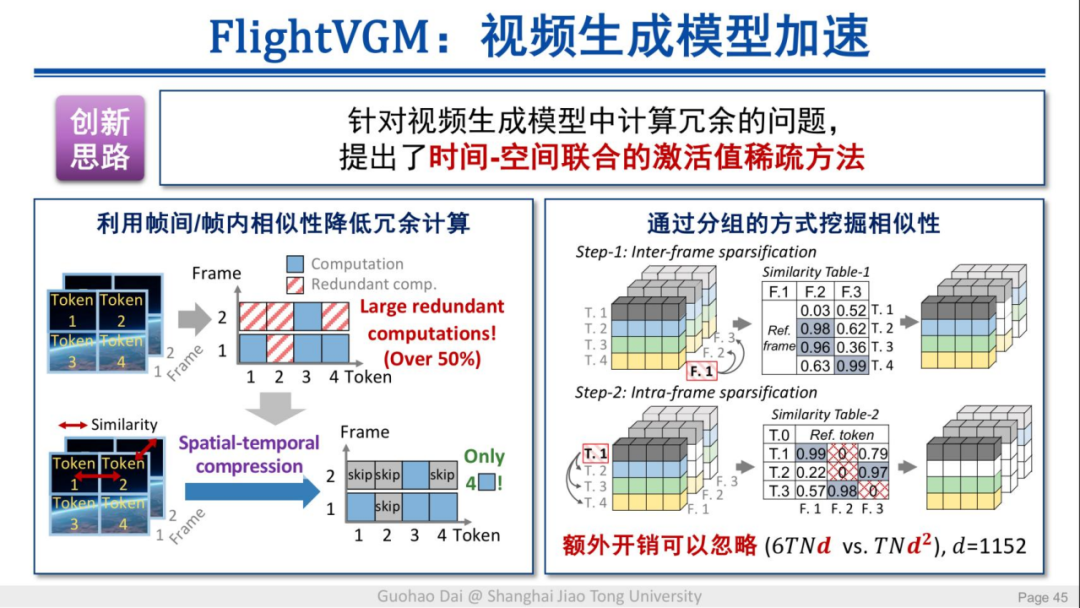
该方法提出了时间-空间联合的激活值稀疏,通过充分利用帧间与帧内的相似性来降低冗余计算。
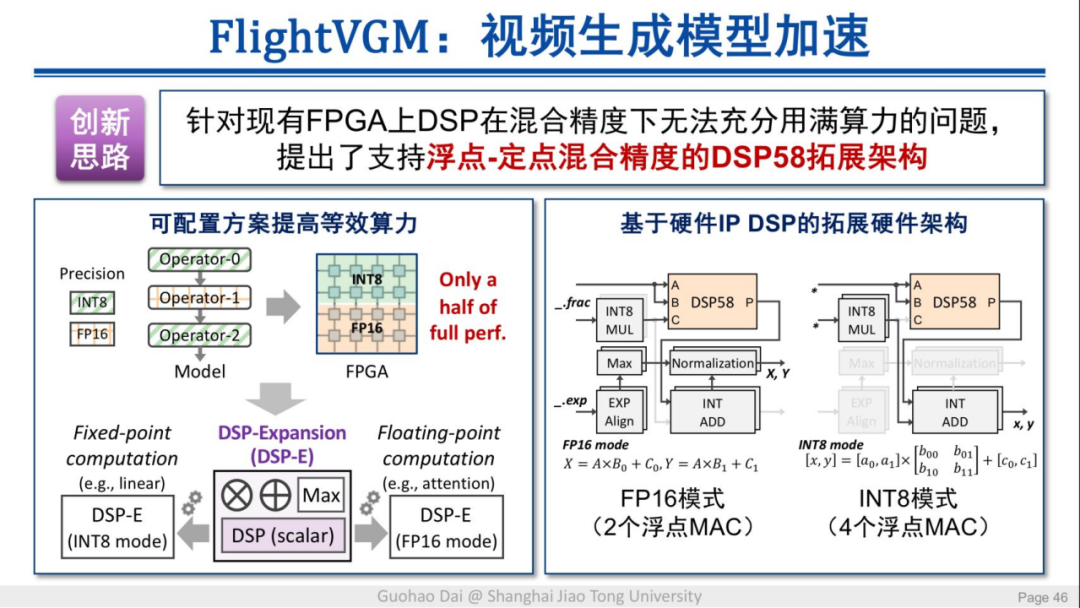
同时,在硬件实现层面,该工作提出了支持浮点-定点混合精度的 DSP58 拓展架构,从而充分利用硬件算力。
最终结果,FlightVGM 在单块 V80 FPGA 芯片上,相比峰值算力是自身 21 倍的 3090 GPU 获得了 1.3 倍的性能和 4.49 倍的能效。
总体而言,FlightLLM 和 FlightVGM 两种方法都通过软硬件协同的方式获得了数量级的效率提升,使应用侧可以在算力受限的情况下满足用户需求。
从稀疏推理到稀疏训练
当前,大多数大模型都是基于 Nvidia 的 GPU 来训练,训练后部署在不同类型的推理硬件上。如果能在训练端就应用稀疏等优化方式,推理侧就可能获得更好的优化空间,即在稀疏硬件架构的支持下,需要建立从训练到推理的完整稀疏计算范式。
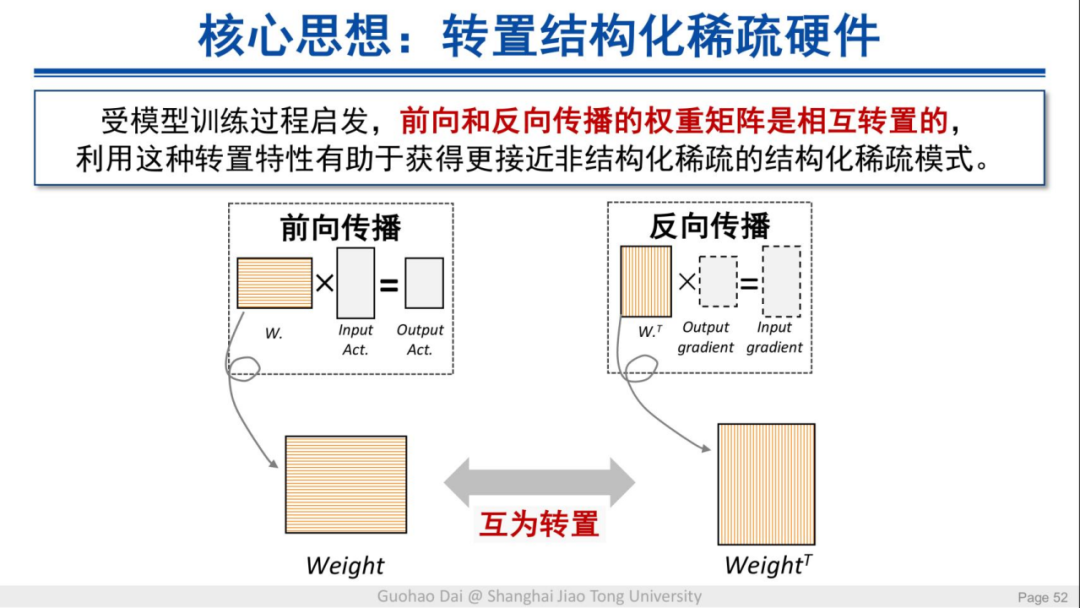
这一过程的核心思想是转置结构化稀疏硬件。受模型训练过程启发,前向和反向传播的权重矩阵是相互转置的,利用这种特性有助于获得更接近非结构化稀疏的结构化稀疏模式。
论文:TB-STC: Transposable Block-wise N:M Structured Sparse Tensor Core,HPCA 25
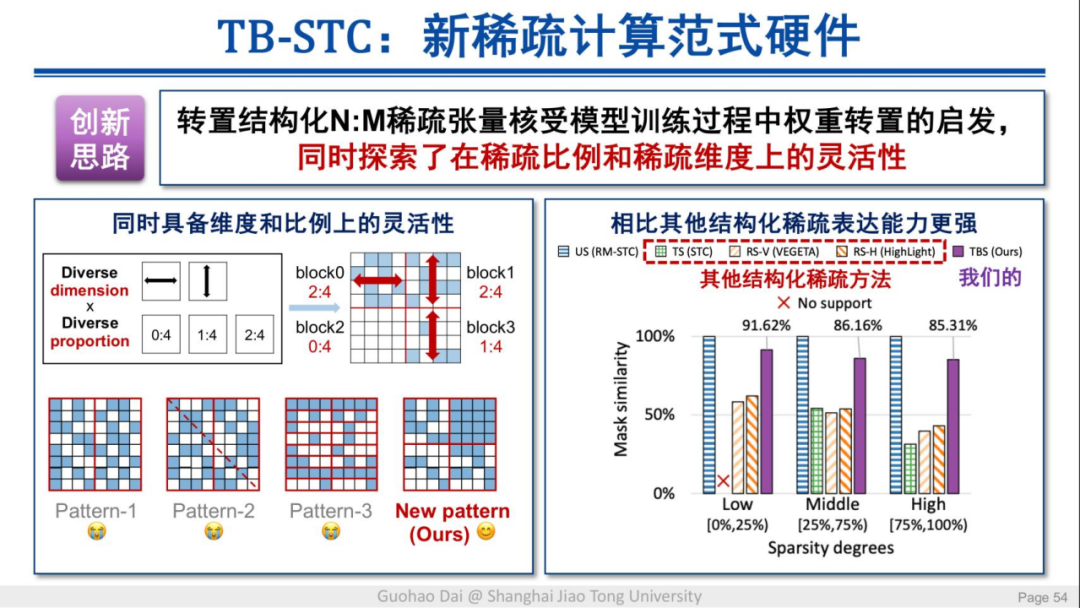
团队还提出了名为 TB-STC 的稀疏计算范式硬件,其同时具备维度和比例上的灵活性,同时可以实现自适应的格式转换。
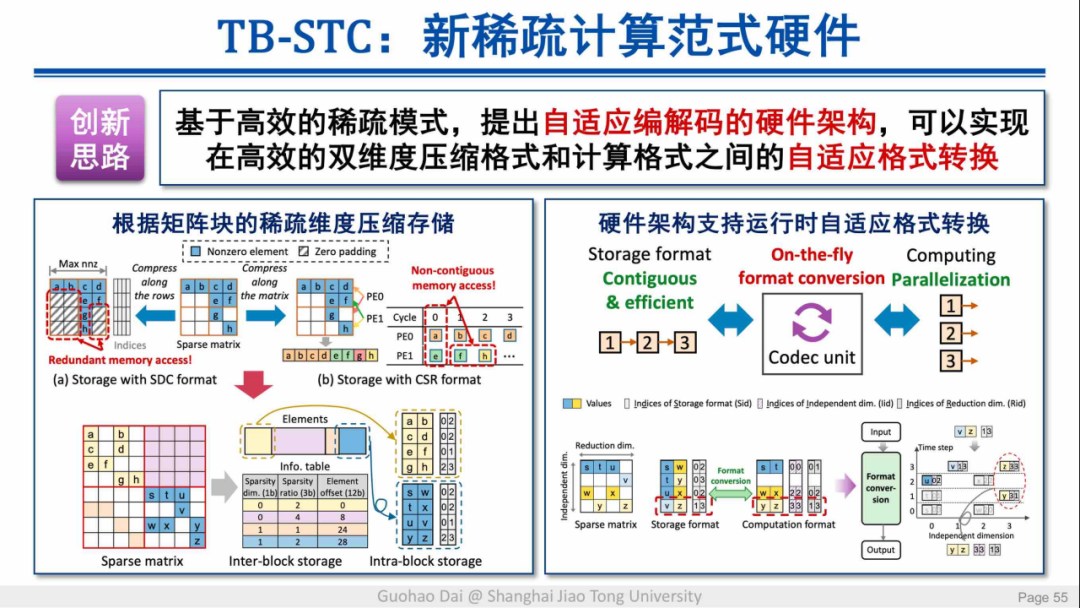
这一硬件在多种主流的深度学习模型上实现了平均 2.31 倍的加速,并且其精度损失非常小,从而进一步向前推动了能效与准确率的帕累托边界。

总结与展望
当前,业界在 AI 软硬件优化方面都在从不同路径努力探索,提出了高扩稀疏 Tensor Core、高效稀疏模型、稀疏模型新架构和新的硬件设计、封装方式等创新。整体而言,通向 AGI 的道路可以总结为计算能力和模型能力两个发展路径:
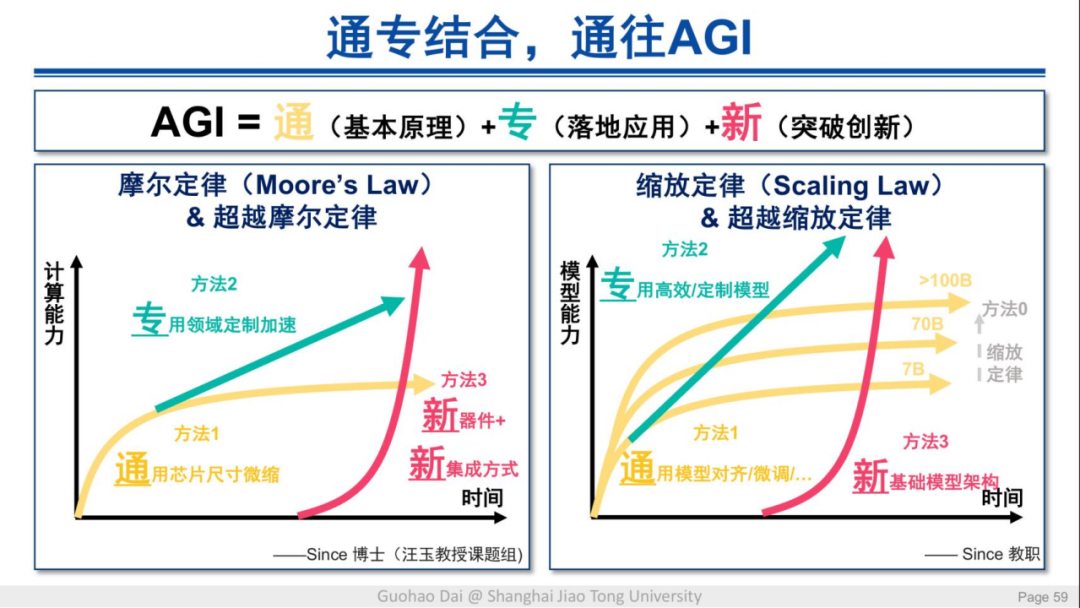
在上图中,左边属于硬件层面的提升,右边是软件层面的提升,两者结合就在推动 AI 能力不断增强。软硬层面的结合,又能区分出多个领域的改进路线:

此外,要进一步提升 AI 应用层面的能力,不仅需要学术层面的研究,还要大规模地将研究成果与工程能力结合落地到产业中。目前,团队已经与国内产业界紧密合作,帮助国产厂商实现了异构千卡混合训练优化,相比同构训练,集群算力利用效率高达93.1~97.6%,同时还在构建大规模的研究 + 工程算力底座,已经支撑了包括上海算法创新研究院、上交人工智能学院集群、上海 AI Lab 等算力底座的建设。
不久前,团队还联合信通院等单位完成了浦江跨域异构算力网络的实验验证。这些工作都为应用开发厂团队减轻了针对底层不同架构硬件进行优化的压力和负担,使厂商可以将更多精力集中在上层开发的创新工作中。
【达摩链接】生态系列内容
“达摩链接”生态系列讲座作为连接达摩院与学术界、产业界的社区活动,通过组织内外部的沙龙、讲座等形式,旨在促进前沿技术的分享交流,推动技术成果的转化、合作与应用落地。
为了让更多开发者、学术研发人员能够深入了解“达摩链接”生态系列讲座的分享内容,我们现将精彩要点整理成文。本文为分享人观点/研究数据,仅供参考,不代表本账号观点和研究内容。


















 2273
2273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









