









一、__call__函数的用法
注意调用内置函数(__call__)和类中其他函数的区别。
代码:
class test:
def __call__(self, name):
print("* ",name)
def others(self,name):
print("** ",name)
person = test()
person("Mary")
person.others("Mary")
输出:
* Mary
** Mary
二、Compose
对图像进行一系列预处理的操作
- 该组合将首先从图像中心裁剪出一个10x10的区域。
- 然后,将图像转换为PyTorch张量。
- 最后,确保张量的数据类型为浮点数,以便进一步标准化或用于深度学习模型。
Example:
>>> transforms.Compose([
>>> transforms.CenterCrop(10),
>>> transforms.PILToTensor(),
>>> transforms.ConvertImageDtype(torch.float),
>>> ])
三、ToTensor
transboard内容参考
代码:
from PIL import Image
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
img_path="data/train/ants_image/0013035.jpg"
img_PIL=Image.open(img_path)
# print(img_PIL)
trans_totensor=transforms.ToTensor()
img_tensor=trans_totensor(img_PIL)
writer=SummaryWriter("logs")
writer.add_image("test",img_tensor)
writer.close()
终端:
tensorboard --logdir=logs
输出网址: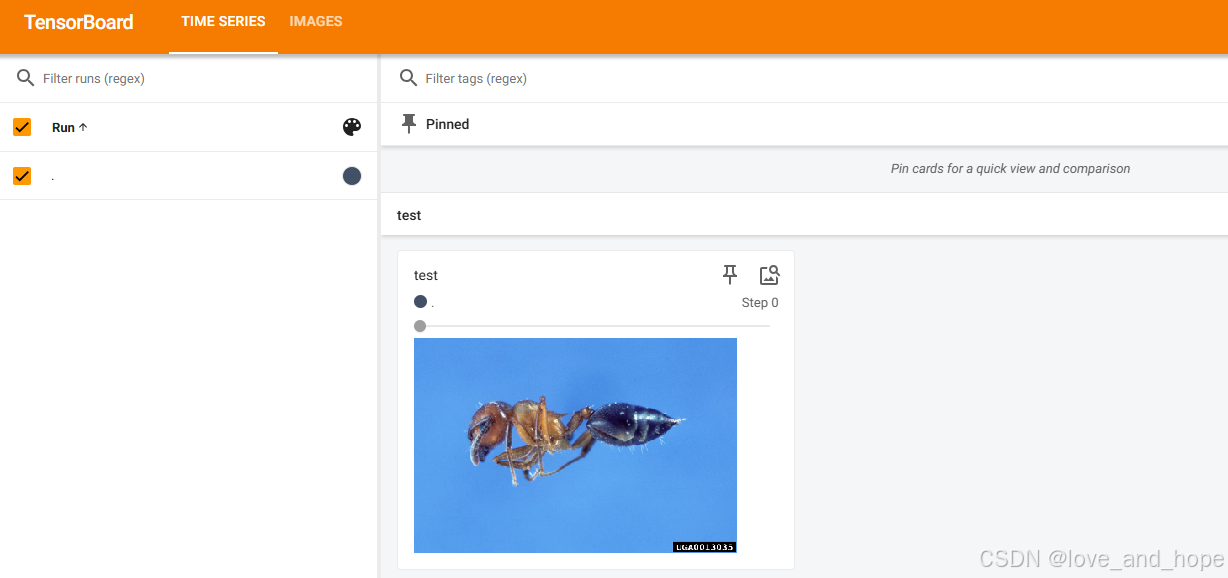
四、Normalize
归一化,需要均值和标准差
class Normalize(torch.nn.Module):
"""Normalize a tensor image with mean and standard deviation.
This transform does not support PIL Image.
Given mean: ``(mean[1],...,mean[n])`` and std: ``(std[1],..,std[n])`` for ``n``
channels, this transform will normalize each channel of the input
``torch.*Tensor`` i.e.,
``output[channel] = (input[channel] - mean[channel]) / std[channel]``
.. note::
This transform acts out of place, i.e., it does not mutate the input tensor.
Args:
mean (sequence): Sequence of means for each channel.
std (sequence): Sequence of standard deviations for each channel.
inplace(bool,optional): Bool to make this operation in-place.
"""
def __init__(self, mean, std, inplace=False):
super().__init__()
_log_api_usage_once(self)
self.mean = mean
self.std = std
self.inplace = inplace
def forward(self, tensor: Tensor) -> Tensor:
"""
Args:
tensor (Tensor): Tensor image to be normalized.
Returns:
Tensor: Normalized Tensor image.
"""
return F.normalize(tensor, self.mean, self.std, self.inplace)
def __repr__(self) -> str:
return f"{self.__class__.__name__}(mean={self.mean}, std={self.std})"
用 tensorboard 显示以下效果
代码:
from PIL import Image
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
img_path="data/train/ants_image/0013035.jpg"
img_PIL=Image.open(img_path)
# print(img_PIL)
trans_totensor=transforms.ToTensor()
img_tensor=trans_totensor(img_PIL)
writer=SummaryWriter("logs")
writer.add_image("test",img_tensor,1)
#第一个列表是图像各通道的均值,表示每个通道(通常是RGB三通道)的均值分别为0.5。
#第二个列表是图像各通道的标准差,同样分别为R、G、B通道提供的标准差值。
trans_normalize=transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
img_norm=trans_normalize(img_tensor)
writer.add_image("test",img_norm,2)
writer.close()
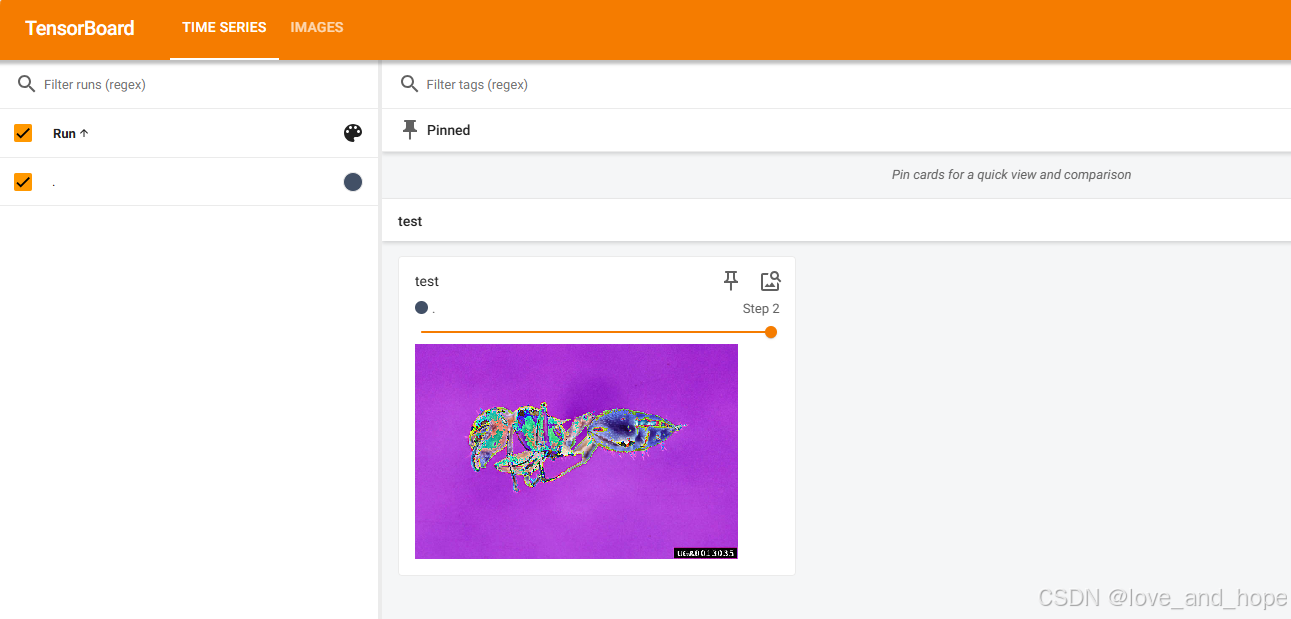
五、Resize
class Resize(torch.nn.Module):
"""Resize the input image to the given size.
If the image is torch Tensor, it is expected
to have [..., H, W] shape, where ... means an arbitrary number of leading dimensions
.. warning::
The output image might be different depending on its type: when downsampling, the interpolation of PIL images
and tensors is slightly different, because PIL applies antialiasing. This may lead to significant differences
in the performance of a network. Therefore, it is preferable to train and serve a model with the same input
types. See also below the ``antialias`` parameter, which can help making the output of PIL images and tensors
closer.
Args:
size (sequence or int): Desired output size. If size is a sequence like
(h, w), output size will be matched to this. If size is an int,
smaller edge of the image will be matched to this number.
i.e, if height > width, then image will be rescaled to
(size * height / width, size).
.. note::
In torchscript mode size as single int is not supported, use a sequence of length 1: ``[size, ]``.
interpolation (InterpolationMode): Desired interpolation enum defined by
:class:`torchvision.transforms.InterpolationMode`. Default is ``InterpolationMode.BILINEAR``.
If input is Tensor, only ``InterpolationMode.NEAREST``, ``InterpolationMode.BILINEAR`` and
``InterpolationMode.BICUBIC`` are supported.
For backward compatibility integer values (e.g. ``PIL.Image[.Resampling].NEAREST``) are still accepted,
but deprecated since 0.13 and will be removed in 0.15. Please use InterpolationMode enum.
max_size (int, optional): The maximum allowed for the longer edge of
the resized image: if the longer edge of the image is greater
than ``max_size`` after being resized according to ``size``, then
the image is resized again so that the longer edge is equal to
``max_size``. As a result, ``size`` might be overruled, i.e the
smaller edge may be shorter than ``size``. This is only supported
if ``size`` is an int (or a sequence of length 1 in torchscript
mode).
antialias (bool, optional): antialias flag. If ``img`` is PIL Image, the flag is ignored and anti-alias
is always used. If ``img`` is Tensor, the flag is False by default and can be set to True for
``InterpolationMode.BILINEAR`` only mode. This can help making the output for PIL images and tensors
closer.
.. warning::
There is no autodiff support for ``antialias=True`` option with input ``img`` as Tensor.
"""
def __init__(self, size, interpolation=InterpolationMode.BILINEAR, max_size=None, antialias=None):
super().__init__()
_log_api_usage_once(self)
if not isinstance(size, (int, Sequence)):
raise TypeError(f"Size should be int or sequence. Got {type(size)}")
if isinstance(size, Sequence) and len(size) not in (1, 2):
raise ValueError("If size is a sequence, it should have 1 or 2 values")
self.size = size
self.max_size = max_size
# Backward compatibility with integer value
if isinstance(interpolation, int):
warnings.warn(
"Argument 'interpolation' of type int is deprecated since 0.13 and will be removed in 0.15. "
"Please use InterpolationMode enum."
)
interpolation = _interpolation_modes_from_int(interpolation)
self.interpolation = interpolation
self.antialias = antialias
def forward(self, img):
"""
Args:
img (PIL Image or Tensor): Image to be scaled.
Returns:
PIL Image or Tensor: Rescaled image.
"""
return F.resize(img, self.size, self.interpolation, self.max_size, self.antialias)
def __repr__(self) -> str:
detail = f"(size={self.size}, interpolation={self.interpolation.value}, max_size={self.max_size}, antialias={self.antialias})"
return f"{self.__class__.__name__}{detail}"
代码:
from PIL import Image
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
img_path="data/train/ants_image/0013035.jpg"
img_PIL=Image.open(img_path)
# print(img_PIL)
# ToTensor
trans_totensor=transforms.ToTensor()
img_tensor=trans_totensor(img_PIL)
writer=SummaryWriter("logs")
writer.add_image("test",img_tensor,1)
# Normalize
#第一个列表是图像各通道的均值,表示每个通道(通常是RGB三通道)的均值分别为0.5。
#第二个列表是图像各通道的标准差,同样分别为R、G、B通道提供的标准差值。
trans_normalize=transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
img_norm=trans_normalize(img_tensor)
writer.add_image("test",img_norm,2)
# Resize
trans_resize=transforms.Resize((512,512))
img_resize=trans_resize(img_norm)
writer.add_image("test",img_resize,3)
writer.close()
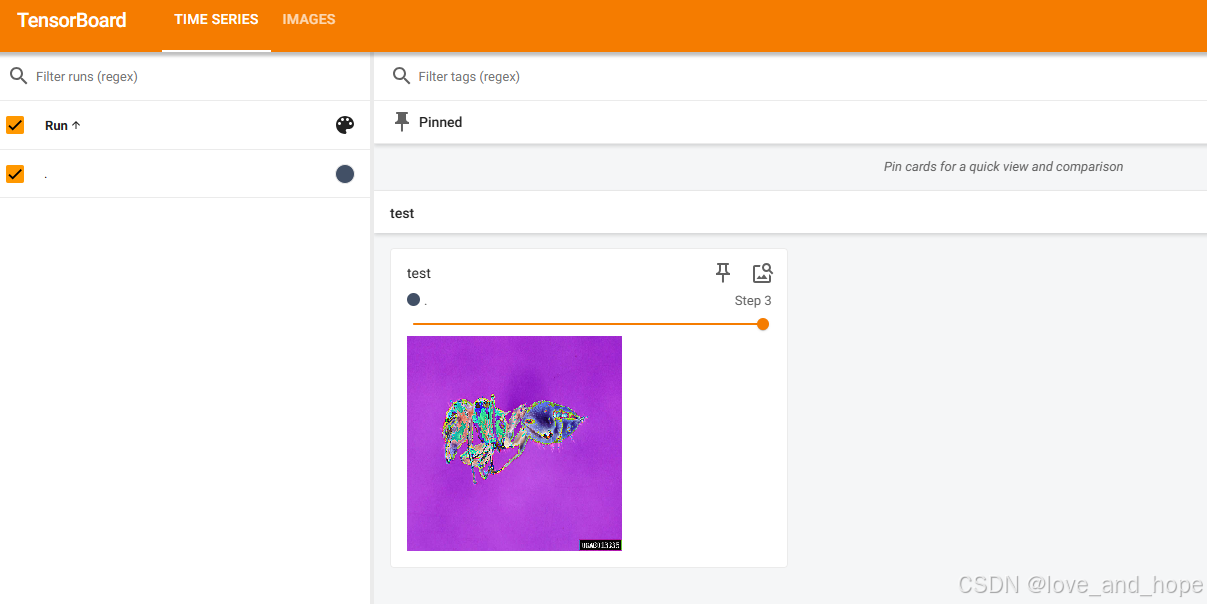
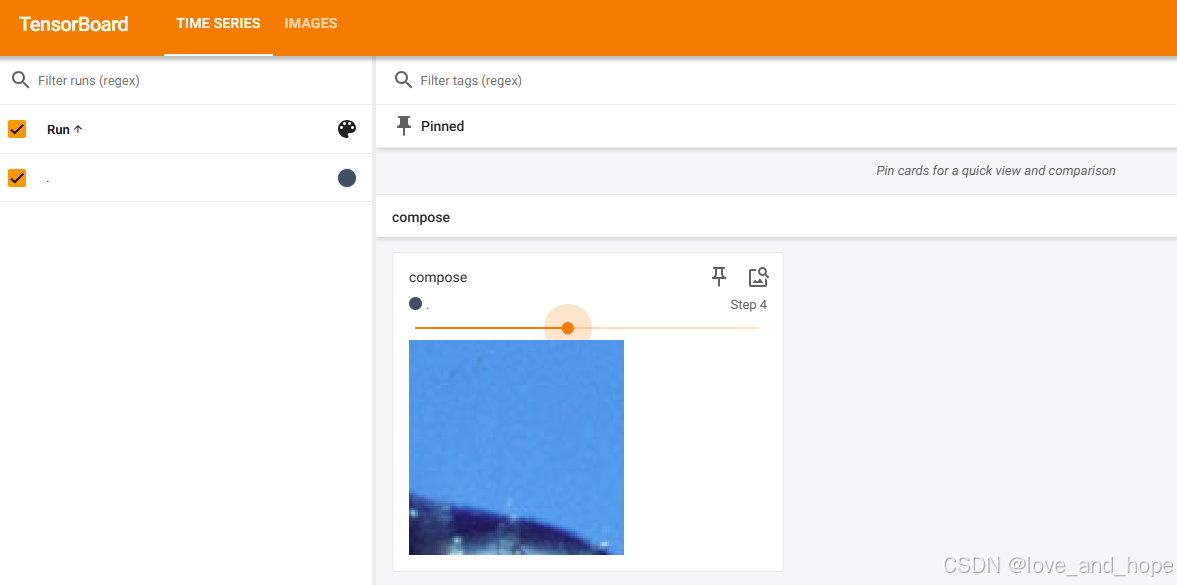
六、Compose补充使用
代码(step 4 的效果与上面的图片相同)
from PIL import Image
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
img_path="data/train/ants_image/0013035.jpg"
img_PIL=Image.open(img_path)
# print(img_PIL)
# ToTensor
trans_totensor=transforms.ToTensor()
img_tensor=trans_totensor(img_PIL)
writer=SummaryWriter("logs")
writer.add_image("test",img_tensor,1)
# Normalize
#第一个列表是图像各通道的均值,表示每个通道(通常是RGB三通道)的均值分别为0.5。
#第二个列表是图像各通道的标准差,同样分别为R、G、B通道提供的标准差值。
trans_normalize=transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
img_norm=trans_normalize(img_tensor)
writer.add_image("test",img_norm,2)
# Resize
trans_resize=transforms.Resize((512,512))
img_resize=trans_resize(img_norm)
# Compose
trans_compose=transforms.Compose([trans_totensor,trans_normalize,trans_resize])
img_compose=trans_compose(img_PIL)
writer.add_image("test",img_compose,4)
writer.close()
七、RandomCrop
class RandomCrop(torch.nn.Module):
"""Crop the given image at a random location.
If the image is torch Tensor, it is expected
to have [..., H, W] shape, where ... means an arbitrary number of leading dimensions,
but if non-constant padding is used, the input is expected to have at most 2 leading dimensions
Args:
size (sequence or int): Desired output size of the crop. If size is an
int instead of sequence like (h, w), a square crop (size, size) is
made. If provided a sequence of length 1, it will be interpreted as (size[0], size[0]).
padding (int or sequence, optional): Optional padding on each border
of the image. Default is None. If a single int is provided this
is used to pad all borders. If sequence of length 2 is provided this is the padding
on left/right and top/bottom respectively. If a sequence of length 4 is provided
this is the padding for the left, top, right and bottom borders respectively.
.. note::
In torchscript mode padding as single int is not supported, use a sequence of
length 1: ``[padding, ]``.
pad_if_needed (boolean): It will pad the image if smaller than the
desired size to avoid raising an exception. Since cropping is done
after padding, the padding seems to be done at a random offset.
fill (number or tuple): Pixel fill value for constant fill. Default is 0. If a tuple of
length 3, it is used to fill R, G, B channels respectively.
This value is only used when the padding_mode is constant.
Only number is supported for torch Tensor.
Only int or tuple value is supported for PIL Image.
padding_mode (str): Type of padding. Should be: constant, edge, reflect or symmetric.
Default is constant.
- constant: pads with a constant value, this value is specified with fill
- edge: pads with the last value at the edge of the image.
If input a 5D torch Tensor, the last 3 dimensions will be padded instead of the last 2
- reflect: pads with reflection of image without repeating the last value on the edge.
For example, padding [1, 2, 3, 4] with 2 elements on both sides in reflect mode
will result in [3, 2, 1, 2, 3, 4, 3, 2]
- symmetric: pads with reflection of image repeating the last value on the edge.
For example, padding [1, 2, 3, 4] with 2 elements on both sides in symmetric mode
will result in [2, 1, 1, 2, 3, 4, 4, 3]
"""
@staticmethod
def get_params(img: Tensor, output_size: Tuple[int, int]) -> Tuple[int, int, int, int]:
"""Get parameters for ``crop`` for a random crop.
Args:
img (PIL Image or Tensor): Image to be cropped.
output_size (tuple): Expected output size of the crop.
Returns:
tuple: params (i, j, h, w) to be passed to ``crop`` for random crop.
"""
_, h, w = F.get_dimensions(img)
th, tw = output_size
if h + 1 < th or w + 1 < tw:
raise ValueError(f"Required crop size {(th, tw)} is larger then input image size {(h, w)}")
if w == tw and h == th:
return 0, 0, h, w
i = torch.randint(0, h - th + 1, size=(1,)).item()
j = torch.randint(0, w - tw + 1, size=(1,)).item()
return i, j, th, tw
def __init__(self, size, padding=None, pad_if_needed=False, fill=0, padding_mode="constant"):
super().__init__()
_log_api_usage_once(self)
self.size = tuple(_setup_size(size, error_msg="Please provide only two dimensions (h, w) for size."))
self.padding = padding
self.pad_if_needed = pad_if_needed
self.fill = fill
self.padding_mode = padding_mode
def forward(self, img):
"""
Args:
img (PIL Image or Tensor): Image to be cropped.
Returns:
PIL Image or Tensor: Cropped image.
"""
if self.padding is not None:
img = F.pad(img, self.padding, self.fill, self.padding_mode)
_, height, width = F.get_dimensions(img)
# pad the width if needed
if self.pad_if_needed and width < self.size[1]:
padding = [self.size[1] - width, 0]
img = F.pad(img, padding, self.fill, self.padding_mode)
# pad the height if needed
if self.pad_if_needed and height < self.size[0]:
padding = [0, self.size[0] - height]
img = F.pad(img, padding, self.fill, self.padding_mode)
i, j, h, w = self.get_params(img, self.size)
return F.crop(img, i, j, h, w)
def __repr__(self) -> str:
return f"{self.__class__.__name__}(size={self.size}, padding={self.padding})"
代码:
from PIL import Image
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
img_path="data/train/ants_image/0013035.jpg"
img_PIL=Image.open(img_path)
# print(img_PIL)
# ToTensor
trans_totensor=transforms.ToTensor()
img_tensor=trans_totensor(img_PIL)
writer=SummaryWriter("logs")
writer.add_image("test",img_tensor,1)
# Normalize
#第一个列表是图像各通道的均值,表示每个通道(通常是RGB三通道)的均值分别为0.5。
#第二个列表是图像各通道的标准差,同样分别为R、G、B通道提供的标准差值。
trans_normalize=transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
img_norm=trans_normalize(img_tensor)
writer.add_image("test",img_norm,2)
# Resize
trans_resize=transforms.Resize((512,512))
img_resize=trans_resize(img_norm)
# Compose
trans_compose=transforms.Compose([trans_totensor,trans_normalize,trans_resize])
img_compose=trans_compose(img_PIL)
# RandomCrop
trans_randomcrop=transforms.Compose([transforms.ToTensor(),transforms.RandomCrop((100,100))])
for i in range(10):
img=trans_randomcrop(img_PIL)
writer.add_image("compose",img,i)
# writer.add_image("test",img_compose,4)
writer.close()
输出:
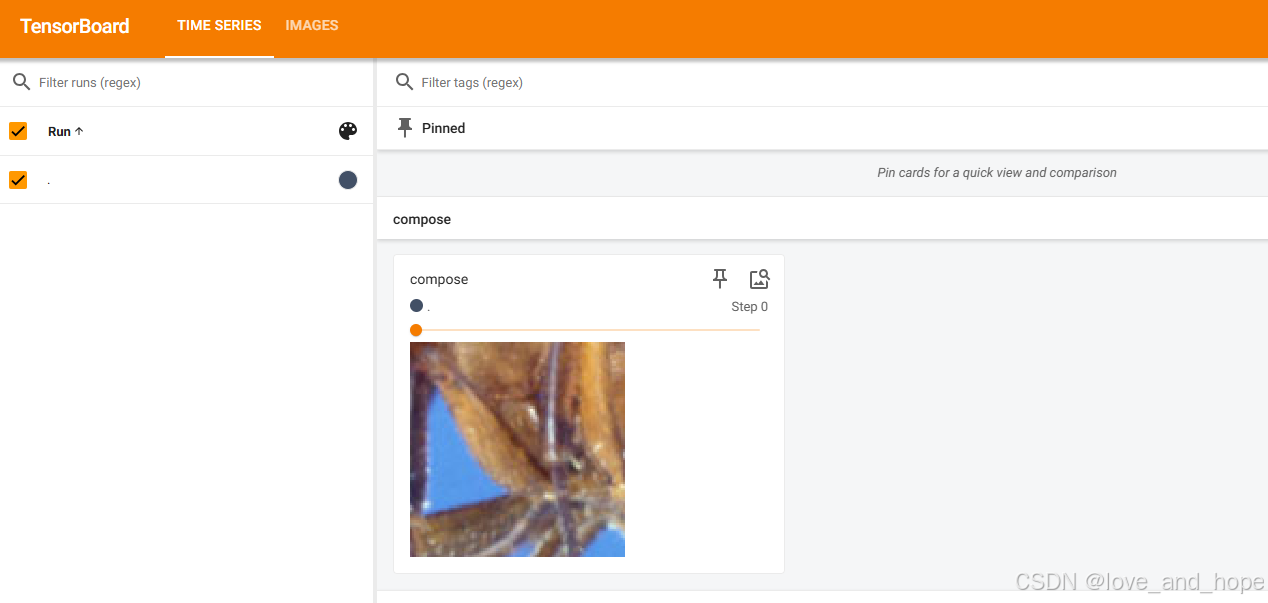

















 851
851

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









