



前言:在数据爆炸的时代,如何从海量信息里快速“捕获有价值的内容”,是各行业数字化进程中绕不开的核心挑战。Elasticsearch(简称 ES)作为 分布式全文搜索引擎的标杆性工具,凭借 毫秒级检索速度、灵活的索引定制能力、强大的分布式架构,成为了电商、医疗、金融、运维等众多领域 挖掘数据价值 的关键载体——小到电商平台的商品模糊搜索,大到医疗病历的精准匹配、金融交易的实时风控分析,都能看到 ES 在背后支撑。
本文将带您从底层逻辑入手,先看透 ES 与索引的核心原理;再通过电商、医疗、金融、运维等真实行业场景,手把手演示如何为业务定制专属索引;更会聚焦实战痛点,拆解认证失败、索引冲突、权限不足等高频报错的解决思路。无论您是刚接触 ES 的新手,还是希望深化实战能力的开发者、运维人员,都能从这些内容中找到让 ES 更顺手的方法,真正把它变成高效驾驭数据的利器。
一、Elasticsearch 与索引的核心原理
(一)Elasticsearch 是什么?
Elasticsearch(简称 ES)是一款分布式全文搜索引擎,核心能力是“快速存储、检索和分析海量数据”。无论是电商商品搜索、日志分析、医疗病历检索,还是金融交易监控,ES 都能通过分布式架构和高效的索引机制,实现毫秒级响应。
底层核心原理:
- 分布式分片:数据被拆分为多个
分片(Shard),分散存储在不同节点,既解决海量数据存储问题,又通过 并行查询 提升速度; - 倒排索引:不同于传统数据库 按行存数据,ES 提前建立 “关键词→文档” 的映射(比如 “感冒” 出现在哪些病历中),查询时直接定位结果,避免全表扫描;
- 近实时性:数据写入后默认1秒内可被检索(可通过
refresh_interval调整),平衡实时性与性能。
(二)索引(Index)的作用与原理
在 ES 中,索引 可以理解为 具有相同结构的数据集合,类似数据库中的 表,但功能更强大:
- 存储数据:按 文档(Document) 存储单条记录(类似数据库的 “行”);
- 定义结构:通过 映射(Mapping) 指定字段类型(文本、数值、日期等)、分词规则等;
- 优化检索:根据映射自动构建倒排索引,让不同类型的字段(如全文文本、精确关键词)用最优方式被检索。
通俗理解
- ES 想象成 智能图书馆:ES 是图书馆整体,负责管理所有 书籍(数据);
- 索引就是 按类别划分的书架(如 “医学类” “电商商品类” ),用来归类 同一类的书籍(数据);
- 倒排索引则是 关键词目录:比如查 “咳嗽”,目录直接告诉你哪几本书(文档,即 “某患者的病历数据” “某医学论文数据” 这类具体数据)里有这个词,不用一本本翻;
- 正排索引则是 书的正文本身:如果要找某本书里包含哪些关键词(比如想知道《常见感冒养护》这本 文档(数据) 里讲了哪些症状),得 逐页翻阅这本书 才能提取出 “鼻塞” “流涕” 这些关键词;
- 这里的 数据 ,可以是:电商场景里的 商品信息(名称、价格、描述)、医疗场景里的 病历记录(症状、诊断、治疗方案)、社交平台的 动态内容(文字、图片说明) 等——它们就像图书馆里 每一本具体的书,是 ES 要存储和检索的核心对象。
二、多行业索引创建典型案例
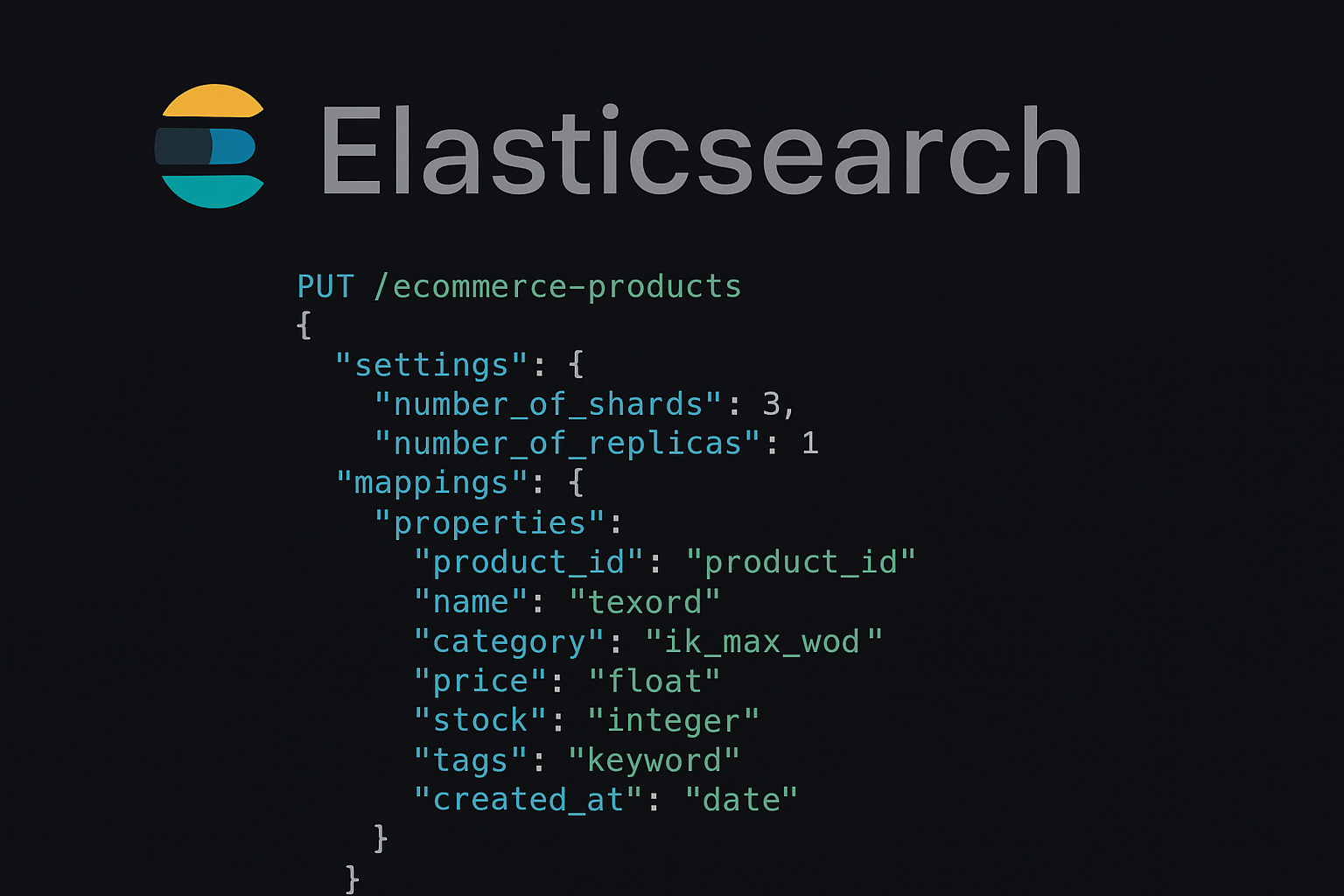
(一)电商零售行业:商品与订单索引
1. 商品搜索索引(全文检索优化)
PUT /products
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"name": { "type": "text", "analyzer": "ik_max_word" }, // 中文分词
"brand": { "type": "keyword" }, // 精确筛选品牌
"price": { "type": "double" },
"category": { "type": "keyword" },
"description": { "type": "text" }
}
}
}
2. 订单管理索引(时间与状态筛选)
PUT /orders
{
"mappings": {
"properties": {
"order_id": { "type": "keyword" },
"user_id": { "type": "keyword" },
"status": { "type": "keyword" }, // 待支付/已完成
"amount": { "type": "double" },
"created_at": { "type": "date" } // 支持时间范围查询
}
}
}
(二)人力资源行业:职位分布索引
PUT /job_distribution
{
"mappings": {
"properties": {
"job_title": { "type": "text" }, // 职位名模糊搜索
"industry": { "type": "keyword" }, // 行业精确筛选
"city": { "type": "keyword" },
"salary": { "type": "integer" }, // 薪资范围查询
"company_count": { "type": "integer" }
}
}
}
(三)企业运维行业:日志索引(带生命周期管理)
// 1. 创建日志索引模板(自动管理生命周期)
PUT /_index_template/nginx-logs
{
"index_patterns": ["nginx-logs-*"],
"template": {
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0,
"index.lifecycle.name": "nginx-log-policy" // 绑定生命周期策略
},
"mappings": {
"properties": {
"request_method": { "type": "keyword" },
"status": { "type": "integer" },
"@timestamp": { "type": "date" }
}
}
}
}
// 2. 生命周期策略(7天后自动删除)
PUT /_ilm/policy/nginx-log-policy
{
"policy": {
"phases": {
"delete": {
"min_age": "7d",
"actions": { "delete": {} }
}
}
}
}
(四)金融行业:交易与风控索引
PUT /financial_transactions
{
"mappings": {
"properties": {
"transaction_id": { "type": "keyword" },
"user_id": { "type": "keyword" },
"amount": { "type": "double" },
"type": { "type": "keyword" }, // 转账/消费
"timestamp": { "type": "date" },
"location": { "type": "geo_point" } // 地理坐标(检测异地交易)
}
},
"settings": {
"number_of_replicas": 2 // 高可用(金融数据不容丢失)
}
}
(五)社交平台行业:动态内容索引
PUT /social_posts
{
"mappings": {
"properties": {
"post_id": { "type": "keyword" },
"user_id": { "type": "keyword" },
"content": { "type": "text", "analyzer": "ik_max_word" }, // 中文内容分词
"topics": { "type": "keyword" }, // 话题标签(#科技)
"created_at": { "type": "date" }
}
}
}
(六)医疗行业:病历与论文索引
1. 病历索引(医疗术语优化)
PUT /medical_records
{
"settings": {
"analysis": {
"analyzer": {
"medical_analyzer": { // 医疗专用分词器(处理同义词)
"type": "custom",
"tokenizer": "standard",
"filter": ["lowercase", "medical_synonym"]
}
},
"filter": {
"medical_synonym": { // 医学同义词映射
"type": "synonym",
"synonyms": ["发烧,发热", "咳嗽,咳嗦", "头晕,头昏"]
}
}
}
},
"mappings": {
"properties": {
"patient_id": { "type": "keyword" },
"diagnosis": { "type": "text", "analyzer": "medical_analyzer" }, // 诊断结果
"disease_type": { "type": "keyword" }, // 疾病类型
"record_date": { "type": "date" }
}
}
}
2. 医学论文索引(多字段权重)
PUT /medical_papers
{
"mappings": {
"properties": {
"title": { "type": "text", "boost": 2 }, // 标题权重高于摘要
"abstract": { "type": "text" },
"keywords": { "type": "keyword" },
"publish_date": { "type": "date" }
}
}
}
三、常见报错及处理方案
(一)认证失败(401 Unauthorized)
报错信息:
{
"error": {
"root_cause": [
{
"type": "security_exception",
"reason": "unable to authenticate user [elastic] for REST request [/medical_records]"
}
],
"status": 401
}
}
处理步骤:
- 验证账号密码:通过 Kibana 重置密码
POST /_security/user/elastic/_password { "password": "new_password" } - 检查
elasticsearch.yml中xpack.security.enabled是否为true(启用认证时需一致)。
(二)索引已存在(400 Bad Request)
报错信息:
{
"error": {
"root_cause": [
{
"type": "resource_already_exists_exception",
"reason": "index [products/123...] already exists"
}
],
"status": 400
}
}
处理步骤:
- 查看现有索引:
curl -u 账号:密码 http://ip:9200/_cat/indices?v - 方案1:删除旧索引(谨慎,数据会丢失)
curl -u 账号:密码 -X DELETE "http://ip:9200/products" - 方案2:使用新名称(如
products_v2)。
(三)权限不足(403 Forbidden)
报错信息:
{
"error": {
"root_cause": [
{
"type": "security_exception",
"reason": "action [indices:admin/create] is unauthorized for user [app_user]"
}
],
"status": 403
}
}
处理步骤:
- 创建角色并授予权限:
POST /_security/role/medical_role { "indices": [{"names": ["medical_records"], "privileges": ["create_index", "write"]}] } - 将角色绑定到用户:
POST /_security/user/app_user { "password": "pwd", "roles": ["medical_role"] }
(四)集群状态异常(503 Service Unavailable)
报错信息:
{
"error": {
"root_cause": [
{
"type": "unavailable_shards_exception",
"reason": "primary shard is not active"
}
],
"status": 503
}
}
处理步骤:
- 查看集群状态:
curl -u 账号:密码 http://ip:9200/_cluster/health?pretty - 单节点环境将副本数设为0:
PUT /medical_records/_settings { "number_of_replicas": 0 } - 检查磁盘空间(ES 磁盘使用率超85%会阻止写入)。
(五)数据格式错误(400 Bad Request)
报错信息:
{
"error": {
"root_cause": [
{
"type": "mapper_parsing_exception",
"reason": "failed to parse field [age] of type [integer] with value '五十'"
}
],
"status": 400
}
}
处理步骤:
- 查看字段映射:
curl -u 账号:密码 http://ip:9200/medical_records/_mapping - 修正数据格式(如将“五十”改为
50),或修改映射(需重建索引)。
四、非命令行方式:更安全的索引查看与管理
命令行 curl 虽然便捷,但存在“密码明文暴露”的风险。在生产环境或对安全性要求高的场景,推荐使用 Kibana 可视化界面 或 编程语言客户端 替代,既能避免敏感信息泄露,又能提升操作效率。
(一)方法1:通过 Kibana 界面查看(推荐日常运维)
Kibana 是 Elasticsearch 官方配套的可视化工具,支持图形化操作,且密码仅在登录时输入,不会明文出现在命令或日志中。
操作步骤:
- 登录 Kibana:在浏览器中访问 Kibana 服务地址(默认端口
5601),例如http://172.20.0.14:5601,输入 Elasticsearch 的账号(如elastic)和对应密码。 - 进入 Dev Tools:在 Kibana 左侧菜单栏,找到 「Management」→「Dev Tools」(或直接搜索“Dev Tools”),打开控制台界面。
- 执行索引查询:在 Dev Tools 控制台中,输入 ES 的 REST API 查询语句,点击「运行」按钮(▶️)。例如,查询所有索引:
执行后,结果会以表格形式展示在右侧面板,与命令行GET /_cat/indices?vcurl效果一致,但全程通过图形界面操作,无需担心密码明文暴露。
(二)方法2:通过编程语言客户端查看(适合开发与自动化场景)
使用 Python、Java、JavaScript 等语言的 Elasticsearch 客户端库编写脚本,密码可存储在配置文件(而非硬编码到命令中),通过代码逻辑完成索引查询,安全性更高。
Python 客户端示例(结合配置文件):
-
安装依赖:
pip install elasticsearch configparser -
编写 Python 脚本(
es_index_check.py):from elasticsearch import Elasticsearch import configparser # 从配置文件读取 ES 连接信息(避免密码硬编码) config = configparser.ConfigParser() config.read('es_config.ini') # 配置文件路径,需与脚本同目录 es_host = config.get('es', 'host') es_port = config.get('es', 'port') es_user = config.get('es', 'user') es_password = config.get('es', 'password') # 连接 Elasticsearch es = Elasticsearch( hosts=[f"http://{es_host}:{es_port}"], basic_auth=(es_user, es_password) ) # 查询所有索引(带详细表头) response = es.cat.indices(v=True) print(response) -
配置文件(
es_config.ini)示例:[es] host = 172.20.0.14 port = 9200 user = elastic password = mzm.2025 # 配置文件可设置权限(如仅所有者可读),比命令行明文更安全 -
运行脚本:
python es_index_check.py脚本会输出与
curl -u elastic:mzm.2025 http://172.20.0.14:9200/_cat/indices?v一致的索引列表,但密码存储在配置文件中,避免了命令行明文暴露。
三种方式的对比
| 方式 | 安全性 | 操作难度 | 适用场景 |
|---|---|---|---|
命令行 curl | 低(密码可能明文暴露) | 简单 | 临时快速查询(测试环境) |
| Kibana 界面 | 高(密码仅登录时输入) | 直观 | 日常运维、可视化查询 |
| 编程语言客户端 | 高(密码可加密/配置文件存储) | 中等 | 自动化脚本、开发集成 |
推荐优先级:日常运维优先用 Kibana 界面(兼顾安全与便捷);开发或自动化场景用编程语言客户端(适合集成到系统中);仅临时测试时,可短期用命令行 curl。
五、总结
ES 的核心价值在于 让数据可被快速检索和分析,而索引设计是实现这一价值的关键——不同行业需根据业务场景(全文检索、多维度筛选、实时性要求等)定制映射和分片策略。同时,掌握常见报错的处理方法,能大幅提升运维效率。
无论是电商的商品搜索、医疗的病历检索,还是金融的风控分析,ES 都能通过灵活的索引机制和分布式架构,成为业务系统的 智能搜索引擎。



















 1479
1479

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











