







1 使用条件
- 可用的数据相对较少,并且需要尽可能的精确的评估模型(比K折交叉验证更精确一点)
- 在竞赛中使用
2 架构原理
你需要先了解K折交叉验证的相关原理:
什么是K折交叉验证_k折交叉验证 验证集或测试集-优快云博客![]() https://blog.youkuaiyun.com/weixin_65259109/article/details/144983997对于K折交叉验证可以这样理解,先将数据集按照索引升序进行排列,然后按照索引数量将数据集平均分成K段,从这K段中每次选出一段当作验证集进行验证,其他的当作训练集进行训练,得出分数后记录下来。按照上述流程选K次,每一段都有被选为验证集的可能(有且只有一次)。
https://blog.youkuaiyun.com/weixin_65259109/article/details/144983997对于K折交叉验证可以这样理解,先将数据集按照索引升序进行排列,然后按照索引数量将数据集平均分成K段,从这K段中每次选出一段当作验证集进行验证,其他的当作训练集进行训练,得出分数后记录下来。按照上述流程选K次,每一段都有被选为验证集的可能(有且只有一次)。
那么,带有重复的K折交叉验证就是再一次精进了数据的排序顺序。它在考虑如果将数据集划分为K段之后,数据本身索引的顺序就固定下来了。这相较于从数据集中随机抽取作为验证集而言,缺少一定的随机性。为了融合随机抽取和K折交叉验证的优点,带有打乱数据的重复K折验证产生。其核心是:
- 将数据打乱
- 对打乱后的数据进行K折交叉验证
- 将分数记录下来
- 将数据打乱
- 对打乱后的数据进行K折交叉验证
- ……
假设这样的循环重复p次,每个循环都是k折交叉验证。那么,我需要去训练p*k个模型,每个模型记录评估分数。
但是!基本原理是这个原理,实现的话是否使用两个for循环进行实现呢?事实上这样的架构是可以的,但更方便的是sklearn中的RepeatedKFold函数。
其核心思想是设置一个列表用于记录每次K折交叉验证的索引顺序,索引顺序用于K折交叉验证。对于每次重新打乱,只需要重新排列这个索引顺序列表即可。
对于模型取数据而言,它只会从RepeatedKFold函数中去得到原有数据的索引从而取训练或者验证模型。
其源代码如下:
from sklearn.model_selection import KFold
import numpy as np
class RepeatedKFold:
def __init__(self, n_splits=5, n_repeats=10, random_state=None):
self.n_splits = n_splits
self.n_repeats = n_repeats
self.random_state = random_state
def split(self, X):
rng = np.random.RandomState(self.random_state)
for _ in range(self.n_repeats):
# 每次重复时打乱数据
indices = np.arange(X.shape[0])
rng.shuffle(indices)
# 使用 KFold 进行划分
kf = KFold(n_splits=self.n_splits)
for train_index, val_index in kf.split(indices):
yield indices[train_index], indices[val_index]这个函数返回的是一个generator,其通过yield一次次返回每次重新运行的结果,想要了解generator的话请参考这个博文:
Python 生成器(generator)详细总结+示例_python generator-优快云博客![]() https://blog.youkuaiyun.com/Jairoguo/article/details/104508721下面是这个函数的官方指导文档:
https://blog.youkuaiyun.com/Jairoguo/article/details/104508721下面是这个函数的官方指导文档:
Type: RepeatedKFold
String form: RepeatedKFold(n_repeats=2, n_splits=2, random_state=42)
File: c:\users\10158\anaconda3\envs\tensorflow_dl\lib\site-packages\sklearn\model_selection\_split.py
Source:
class RepeatedKFold(_UnsupportedGroupCVMixin, _RepeatedSplits):
"""Repeated K-Fold cross validator.
Repeats K-Fold n times with different randomization in each repetition.
Read more in the :ref:`User Guide <repeated_k_fold>`.
Parameters
----------
n_splits : int, default=5
Number of folds. Must be at least 2.
n_repeats : int, default=10
Number of times cross-validator needs to be repeated.
random_state : int, RandomState instance or None, default=None
Controls the randomness of each repeated cross-validation instance.
Pass an int for reproducible output across multiple function calls.
See :term:`Glossary <random_state>`.
Signature: kf.split(X, y=None, groups=None)
Source:
def split(self, X, y=None, groups=None):
"""Generate indices to split data into training and test set.
Parameters
----------
X : array-like of shape (n_samples, n_features)
Training data, where `n_samples` is the number of samples
and `n_features` is the number of features.
y : array-like of shape (n_samples,)
The target variable for supervised learning problems.
groups : object
Always ignored, exists for compatibility.
Yields
------
train : ndarray
The training set indices for that split.
test : ndarray
The testing set indices for that split.
"""
if groups is not None:
warnings.warn(
f"The groups parameter is ignored by {self.__class__.__name__}",
UserWarning,
)
return super().split(X, y, groups=groups)
File: c:\users\10158\anaconda3\envs\tensorflow_dl\lib\site-packages\sklearn\model_selection\_split.py
Type: method
下面举几个常用的调用例子:
import numpy as np
from sklearn.model_selection import RepeatedKFold
train_data = np.array([[1, 2], [3, 4], [5, 6], [7, 8], [9, 10],[11,12],[13,14],[15,16],[17,18],[19,20]])
train_targets = np.array([1, 2, 3, 4, 5,6,7,8,9,10])
n_splits = 5 # 折数
n_repeats = 2 # 重复次数
kf = RepeatedKFold(n_splits=n_splits, n_repeats=n_repeats, random_state=42)
for i, (train_index, test_index) in enumerate(kf.split(train_data)):
print(f"Fold {i}:")
print(f" Train: index={train_index}")
print(f" Test: index={test_index}")其返回如下:

可以看到Fold 0-Fold 4是第一次打乱顺序,Fold 5-Fold 9是第二次打乱顺序。
3 代码实现
代码实现的关键在于借助索引拼接形成训练集和验证集,并且设置一个列表进行记录然后计算对应epoch的平均值用于可视化。
使用boston_housing数据集作为示例,了解这个情景请见:
认识波士顿房价数据集-优快云博客![]() https://blog.youkuaiyun.com/weixin_65259109/article/details/144978152以下是具体的代码:
https://blog.youkuaiyun.com/weixin_65259109/article/details/144978152以下是具体的代码:
from tensorflow.keras.datasets import boston_housing
import numpy as np
from sklearn.model_selection import RepeatedKFold
import tensorflow.keras as keras
from tensorflow.keras import layers
import matplotlib.pyplot as plt
(train_data,train_targets),(test_data,test_targets) = boston_housing.load_data()#回归问题目标值记为target,分类问题记为label
#数据标准化,包括训练集和测试集,不包括标签(预测值)
#先计算均值和方差
mean = train_data.mean(axis=0)
std = train_data.std(axis=0)
#对训练集、测试集进行标准化,减去均值除以标准差
train_data -= mean
train_data /= std
test_data -= mean
test_data /= std
def build_model():
model = keras.Sequential([
layers.Dense(64,activation='relu'),
layers.Dense(64,activation='relu'),
layers.Dense(1)
])
model.compile(
optimizer="rmsprop",
loss="mse",
metrics=['mae']
)
return model
# 设置K折交叉验证的参数
n_splits = 5 # 折数
n_repeats = 3 # 重复次数
kf = RepeatedKFold(n_splits=n_splits, n_repeats=n_repeats, random_state=42)
all_mse_histories = []#设置一个空列表用于存储所有的loss值(loss值取的是mse)
all_mae_histories = []#设置一个空列表用于存储所有的metrics值(metric值取的是mae)
# 进行K折交叉验证
for fold, (train_index, val_index) in enumerate(kf.split(train_data)):
# 划分训练集和验证集
x_train, x_val = train_data[train_index], train_data[val_index]
y_train, y_val = train_targets[train_index], train_targets[val_index]
# 构建和训练模型
model = build_model()
history = model.fit(
x_train,
y_train,
validation_data=(x_val,y_val),#这里相当于val_mse,val_mae = model.evaluate(val_data,val_targets,verbose=0)
epochs=50,
batch_size=16,
verbose=1
)
mae_hitory = history.history['val_mae']
all_mae_histories.append(mae_hitory)
# 计算每个 epoch 的平均 MAE
average_mae_history = [
np.mean([x[i] for x in all_mae_histories]) for i in range(50)
]
plt.plot(range(1,len(average_mae_history) + 1), average_mae_history)
plt.xlabel('Epochs')
plt.ylabel('Validation MAE')
plt.show()
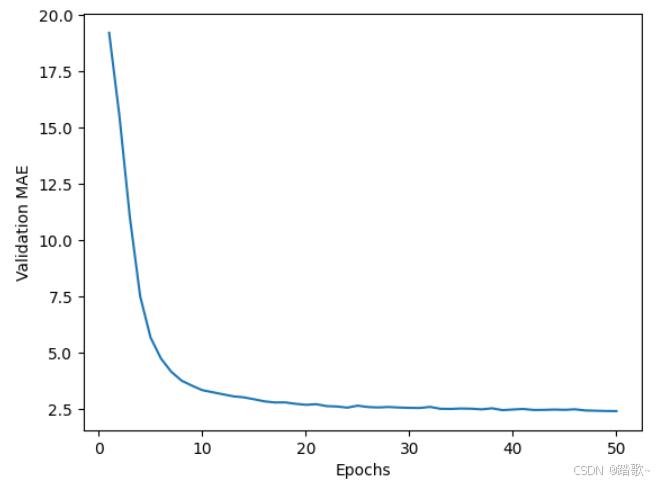
特别值得注意的是all_mae_histories.append(mae_hitory),这里每次添加的是一个列表,最后的all_mae_histories是一个二维的列表,每个子列表里面存储着对应模型的指标信息。
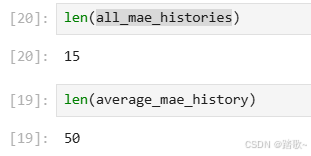
然后
# 计算每个 epoch 的平均 MAE
average_mae_history = [
np.mean([x[i] for x in all_mae_histories]) for i in range(50)
]这里是求每个子列表的对应位置的平均值。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











