







1 基本认识
不管将对数据进行什么样的操作,对数据本身的理解包括对生成数据的业务的理解总是首要的。假设我现在要使用Keras对波士顿房价数据集进行回归,那么我首先要去了解这个数据集是什么样子的。
首先,需要找到数据集的来源,一般在来源网站会有对数据集的描述。
使用bing或者google搜索引擎,将会出现高质量的数据集的可能的来源。
Boston Housing price regression dataset![]() https://keras.io/2.15/api/datasets/boston_housing/其官网的指示文档如下所示:
https://keras.io/2.15/api/datasets/boston_housing/其官网的指示文档如下所示:
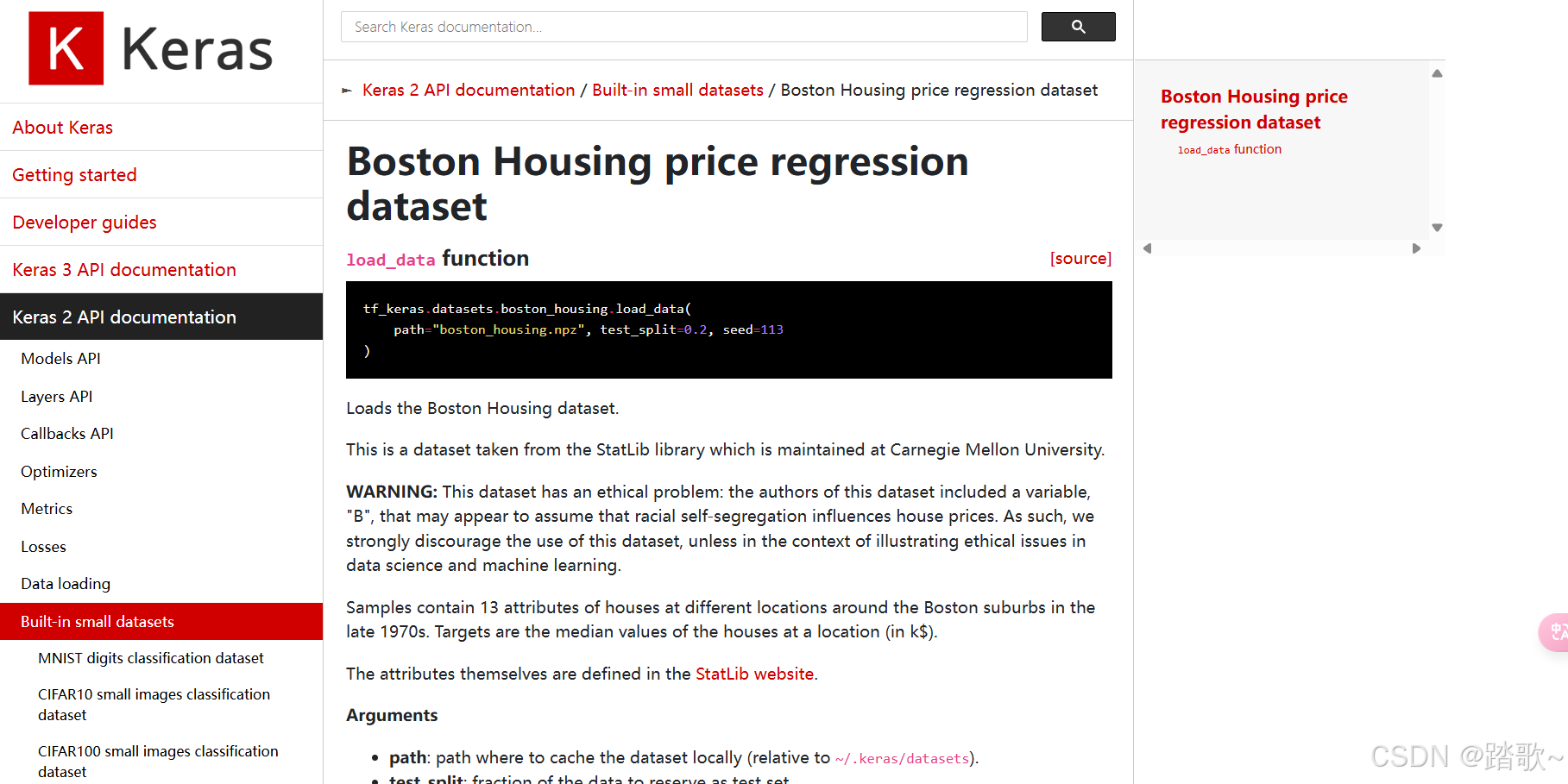
对于数据集的描述只有其有13个属性,目标值是某个位置房屋价格的中位数。并没有对属性当中的数值做过多的解释,但是做数据分析对数据的理解是十分必要的。所以,我们要对其进行溯源。

lib.stat.cmu.edu/datasets/boston![]() https://lib.stat.cmu.edu/datasets/boston进入发现描述分为三部分:
https://lib.stat.cmu.edu/datasets/boston进入发现描述分为三部分:
1、数据的来源是一篇论文。

2、每列属性值的含义

可以这样理解,作者为了探究房价的影响因素和预测房价,对每个自住房屋进行了特征的收集以便描述和区别每一栋自住房屋。也就是构建了许多特征来映射到自主房屋。即房价=f(特征1,特征2,特征3……)。
可以看到数据集给出的标签的描述是资助房屋的中位数价值,这说明是我们想要预测的变量。同时,中位数说明了其可能是按照区域来划分自住房屋,每个区域平均出一个假象的房屋,搜集描述这个房屋房价的特征,然后去探究特征和房价的映射关系。
前面的是属性值,可以确定这些属性值大多是连续值。明确数据结构之后可能会影响我们后续在数据处理时的处理方法。按照类别分类的属性值有:
CHAS Charles River 虚拟变量(如果区域边界为河流,则为 = 1;否则为 0)
放射状高速公路可达性 RAD 指数
3、数据示例
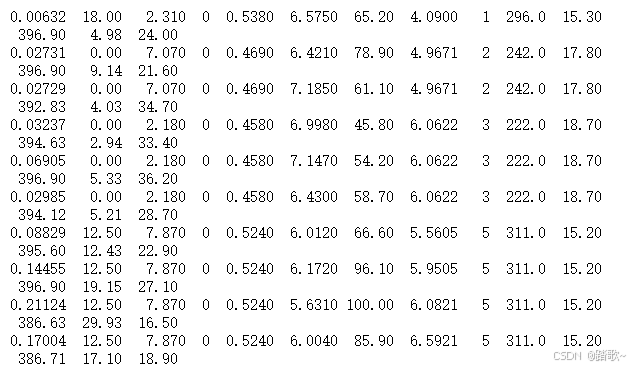
可以印证,有13个属性列,一个标签列。并且数据结构也和我们预想的一样。
2 函数
这个数据集只有一个函数,参数也不多。

2.1 load_data函数参数

2.2 load_data函数返回



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











