










翻译后修饰(PTM),也称为共价修饰,是蛋白质翻译后的化学修饰过程。通过对肽链进行蛋白水解切割,向单个氨基酸添加各种官能团(例如磷酸化),或通过改变氨基酸残基的化学性质(例如瓜氨酸化),各种PTM会创建或破坏共价键,从而改变蛋白质的结构,定位和功能,在几乎所有的细胞信号通路和网络中发挥重要作用,并确定细胞动力学和可塑性。尽管已发现350多种类型的PTM,但由于缺乏足够的分析数据,因此只有少数PTM得到了很好的表征。PTM底物及其位点的实验鉴定是劳动密集型的,并且通常受到酶促反应的可用性和优化的限制。计算机模拟预测可能是进行初步分析并大大减少需要进一步体内或体外确认的潜在靶标数量的有前途的策略。
预测蛋白质的翻译后修饰(Post-Translational Modifications, PTMs)位点是功能研究和机制解析的重要步骤。以下是常见翻译后修饰类型及其预测方法、工具和数据库的详细总结:
一、常见翻译后修饰类型及预测工具
1. 磷酸化(Phosphorylation)
修饰位点:丝氨酸(S)、苏氨酸(T)、酪氨酸(Y)。
预测工具:
NetPhos:基于神经网络的通用磷酸化位点预测(https://services.healthtech.dtu.dk/service.php?NetPhos-3.1)。
GPS:支持激酶特异性预测(如预测某个激酶催化的磷酸化位点)(http://gps.biocuckoo.cn/)。
PhosphoSitePlus:整合已知实验数据的磷酸化位点数据库(https://www.phosphosite.org/)。
实验验证:质谱、抗磷酸化抗体。
2. 泛素化(Ubiquitination)
修饰位点:赖氨酸(K)。
预测工具:
UbPred:基于机器学习的泛素化位点预测(http://www.ubpred.org/)。
GPS-Uber:支持泛素化和其他修饰的预测(http://gps.biocuckoo.cn/)。
dbPTM:整合泛素化位点的数据库(https://awi.cuhk.edu.cn/dbPTM/)。
实验验证:泛素化抗体、质谱、突变赖氨酸(K→R)。
3. 乙酰化(Acetylation)
修饰位点:赖氨酸(K)。
预测工具:
PAIL:预测蛋白质的乙酰化位点(http://bdmpail.biocuckoo.org/)。
GPS-PAIL:结合乙酰化特异性的预测工具(http://pail.biocuckoo.cn/)。
PLMD:乙酰化数据库(http://plmd.biocuckoo.org/)。
实验验证:抗乙酰化抗体(如抗-Ac-K)、质谱。
4. 甲基化(Methylation)
修饰位点:赖氨酸(K)、精氨酸(R)。
预测工具:
MASA:预测精氨酸甲基化位点(http://bioinfo.ncu.edu.cn/MASA.aspx)。
BPB-PPMS:赖氨酸甲基化预测(http://www.biomine.org/BPB-PPMS/)。
MethK:甲基化数据库(https://methk.net/)。
实验验证:质谱、甲基化特异性抗体。
5. SUMO化(SUMOylation)
修饰位点:赖氨酸(K)。
预测工具:
SUMOsp:预测SUMO化位点(http://sumosp.biocuckoo.org/)。
GPS-SUMO:结合SUMO化特异性的预测工具(http://sumo.biocuckoo.cn/))。
SUMOmune:整合实验数据的SUMO化数据库(http://sumosp.biocuckoo.org/online.php)。
实验验证:抗SUMO抗体、质谱。
6. 糖基化(Glycosylation)
类型:N-糖基化(天冬酰胺,N)、O-糖基化(丝氨酸/苏氨酸,S/T)。
预测工具:
NetNGlyc:预测N-糖基化位点(https://services.healthtech.dtu.dk/service.php?NetNGlyc-1.0)。
NetOGlyc:预测O-糖基化位点(https://services.healthtech.dtu.dk/service.php?NetOGlyc-4.0)。
GlycoEP:综合糖基化预测工具(http://www.imtech.res.in/raghava/glycoep/)。
实验验证:凝集素印迹(Lectin blot)、质谱。
二、综合预测工具和数据库
1. 多修饰整合工具
GPS:支持磷酸化、泛素化、乙酰化等多种修饰预测(http://gps.biocuckoo.cn/)。
dbPTM:整合所有已知PTM位点的数据库(https://awi.cuhk.edu.cn/dbPTM/)。
PTMcode:分析PTM的功能关联性(http://ptmcode.embl.de/)。
2. 蛋白质序列分析平台
UniProt:提供已知PTM注释(https://www.uniprot.org/)。
PhosphoSitePlus:综合磷酸化和其他修饰的数据库(https://www.phosphosite.org/)。
三,其他数据库
3.1 PhosphoSitePlus
PhosphoSitePlus数据库(https://www.phosphosite.org/)是一个由CST和NIH联合开发免费的翻译后修饰预测数据库,整合了大量来自高通量测序预测和科学研究实验验证的结果,为蛋白质翻译后修饰的研究提供了全面的信息和工具。该数据库主要包括磷酸化、甲基化、乙酰化、泛素化等,共收录了59499个蛋白的600798个翻译后修饰位点。通过查询蛋白质可以获得蛋白质基本信息(结构域、亚细胞定位)以及蛋白质发生修饰的类型、修饰位点、抗体、修饰相关疾病,以及激酶底物序列。
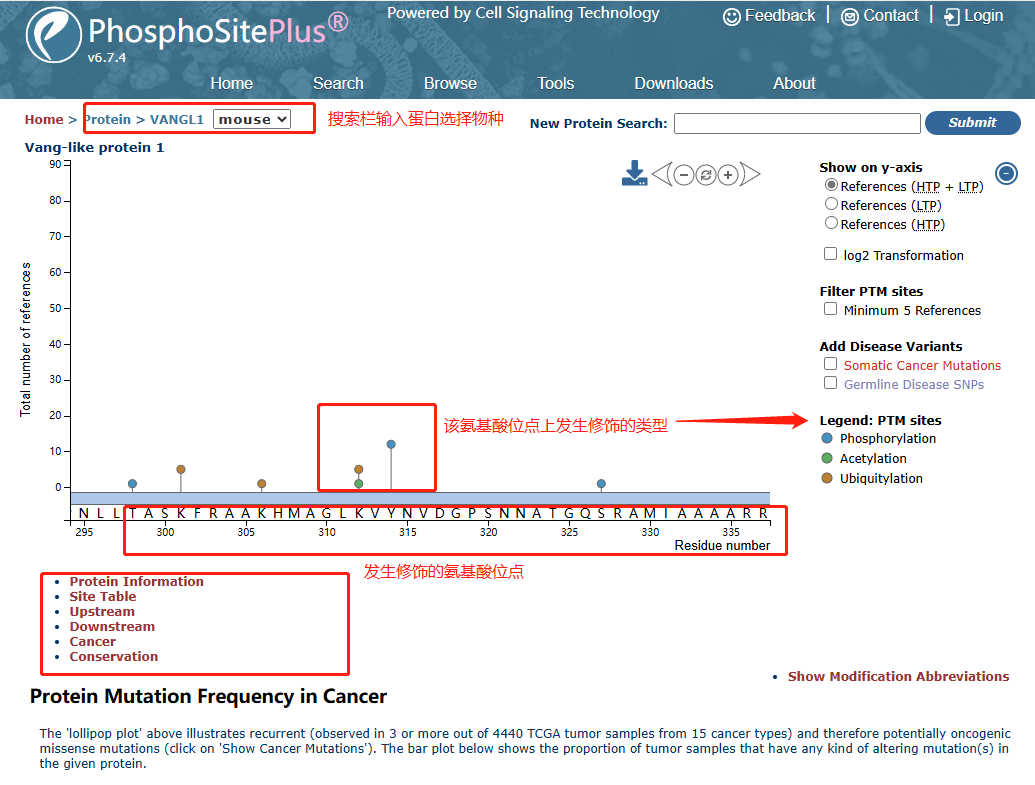
图2.1PhosphoSitePlus数据库使用
3.2 qPTM
qPTM(quantification of Post-Translational Modifications,http://qptm.omicsbio.info)是中山大学肿瘤防治中心刘泽先教授团队收集并整合PTMs文献的数据库,涉及从600多个已发表研究中收集的四种不同生物体(人、大鼠、小鼠、酵母)中40728个蛋白质在2596种条件下的660 030个非冗余PTM位点,修饰类型包括6种(磷酸化、乙酰化、糖基化、甲基化、SUMO化以及泛素化修饰)。通过搜索特定物种的蛋白,即可获得前人研究的修饰发生的位点以及实验条件和参考文献。
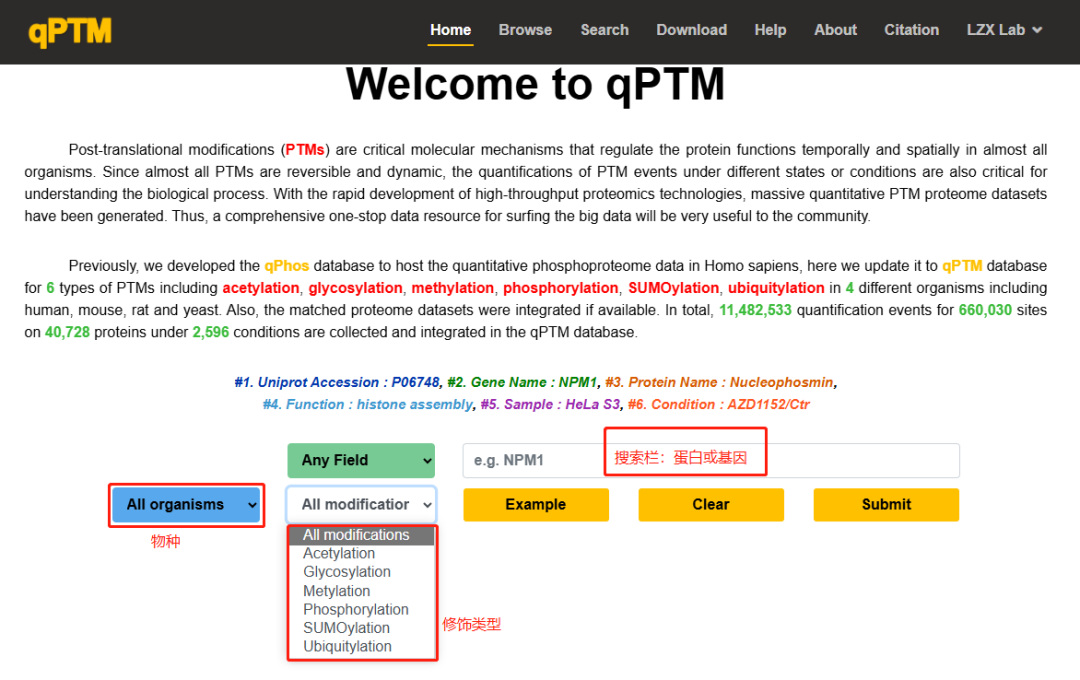
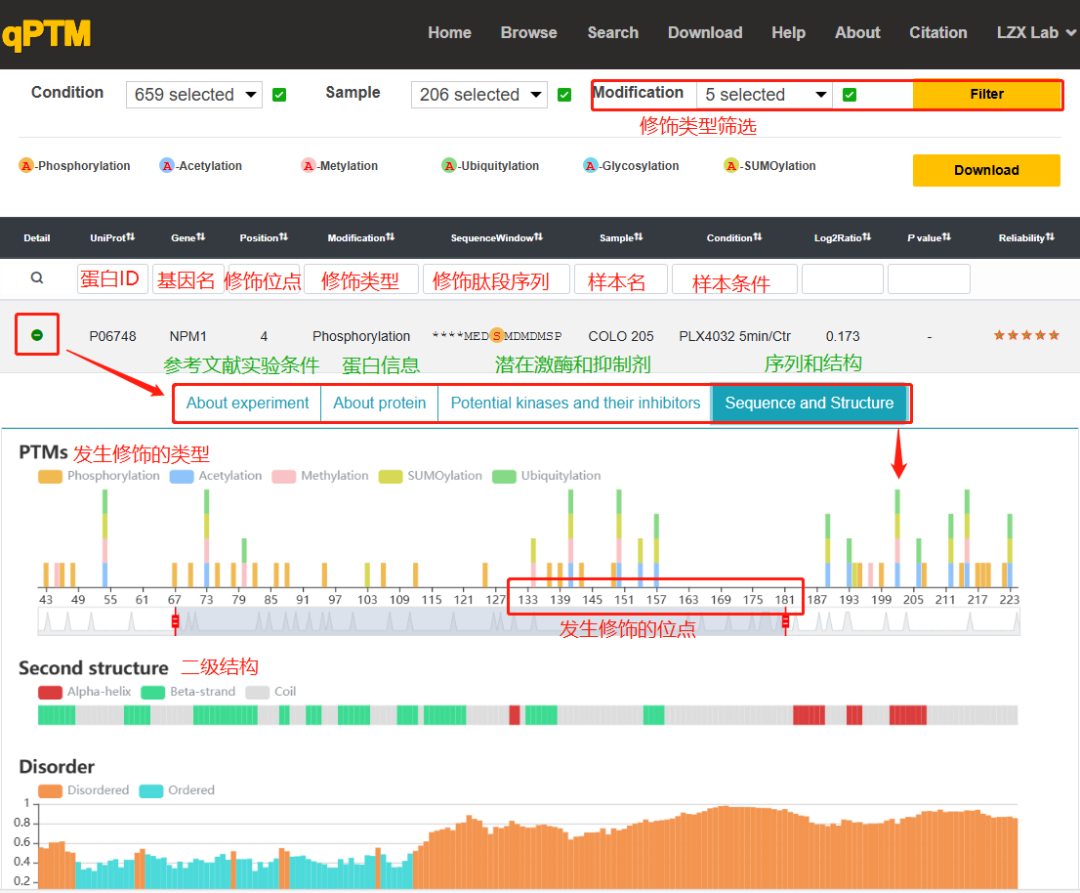
图2.2 qPTM数据库使用
3.3 dbPTM
dbPTM(https://awi.cuhk.edu.cn/dbPTM/index.php)是蛋白质翻译后修饰 (PTM) 的综合资源,整合来自40+数据库、70+种修饰类型、已经被实验/文献证实的PTM位点和预测位点共2235664个,其中重点修饰类型包括磷酸化、糖基化和硫修饰。通过搜索蛋白可获得蛋白二级结构、修饰位点信息、上游调节蛋白、位点功能以及疾病相关信息。
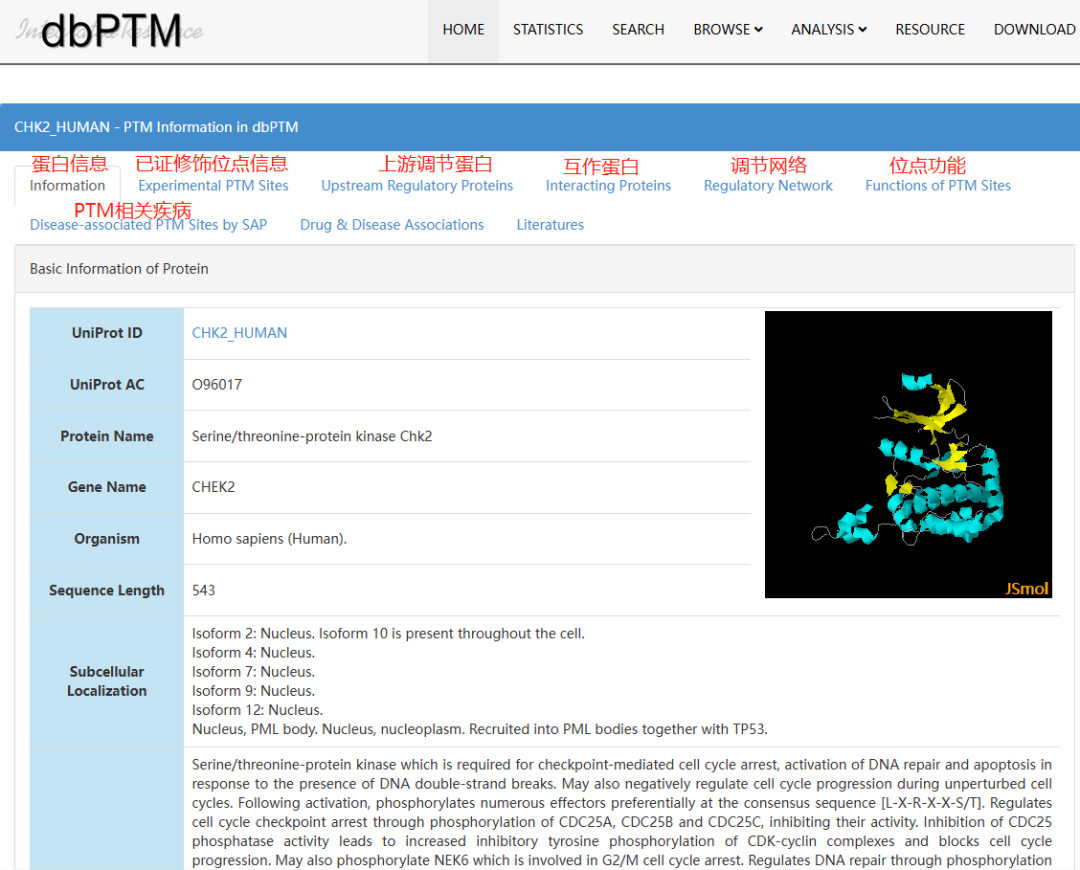
图2.3dbPTM数据库使用
3.4 Plant PTM Viewer
Plant PTM Viewer(http://www.psb.ugent.be/PlantPTMViewer)是植物蛋白翻译后修饰数据库,包含8种不同植物(拟南芥、水稻、大豆、小立碗藓、番茄、玉米、小麦、莱茵衣藻)大约128920个蛋白334255个PTM位点的33种蛋白质修饰。通过该网站我们可以检索目的蛋白在植物中的修饰情况,此外还可以搜索同源序列中的保守翻译后修饰位点。
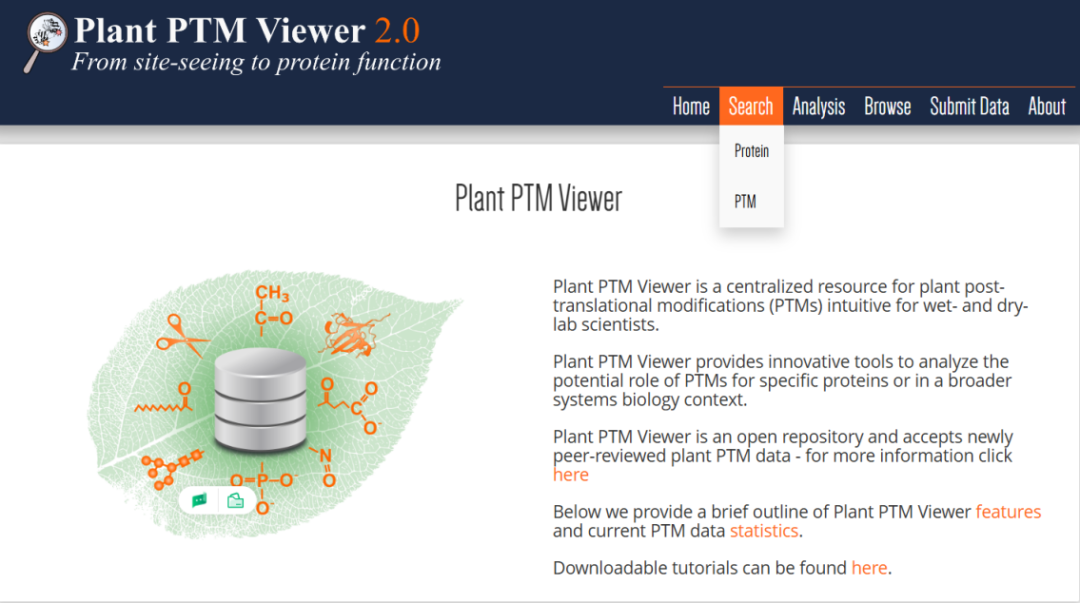
图2.4Plant PTM Viewer数据库使用
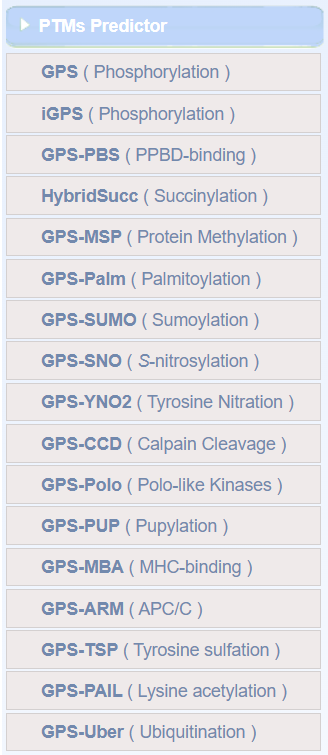
此处重点介绍http://biocuckoo.cn
因为有很多PTM翻译后修饰种类都集成到了其中

各种PTM预测工具在左侧:
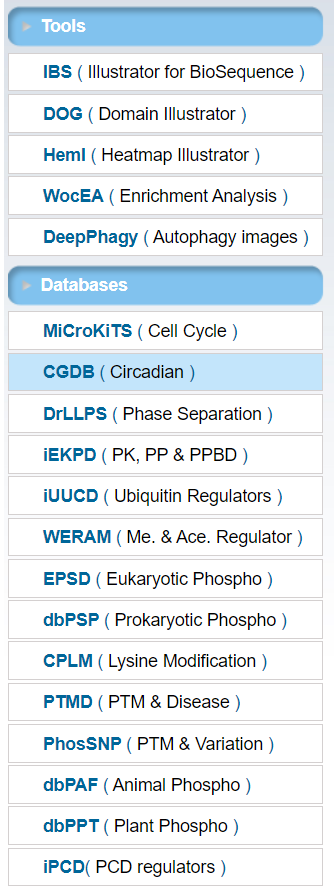
另外,该团队还开发了很多工具和数据库:
四、预测步骤和注意事项
1. 预测流程
输入蛋白质序列:从UniProt获取目标蛋白的FASTA格式序列。
选择预测工具:根据修饰类型选择工具(如磷酸化用NetPhos,泛素化用UbPred)。
设置参数:调整阈值(如p>0.5为高置信度位点)。
交叉验证:使用多个工具预测同一修饰,取交集位点提高可靠性。
结合实验数据:参考数据库(如PhosphoSitePlus)中的已知位点。
2. 注意事项
假阳性和假阴性:预测工具基于已有数据训练,新位点可能未被覆盖。
物种特异性:部分工具针对特定物种(如人类、小鼠)优化。
功能相关性:预测位点需结合功能实验(如突变后功能丧失)。
四、实验验证方法
质谱(Mass Spectrometry):直接鉴定修饰位点。
抗体检测:使用修饰特异性抗体(如抗磷酸化抗体)。
定点突变(Site-Directed Mutagenesis):将预测位点突变(如S→A),观察功能变化。
蛋白质稳定性实验:如环己酰亚胺(CHX)追踪蛋白降解速率。
五、示例:磷酸化位点预测流程
输入序列:从UniProt获取B的FASTA序列(如UniProt ID XXXX)。
使用NetPhos:预测丝氨酸、苏氨酸和酪氨酸的磷酸化位点。
使用PhosphoSitePlus:查询已知的B磷酸化位点(如S10、S20)。
交叉验证:结合GPS预测结果,筛选高置信度位点。
实验验证:通过体外激酶实验和质谱确认A是否磷酸化这些位点。
还有其他的数据库:

参考:
翻译后修饰位点的预测需要结合生物信息学工具和实验验证。通过多工具交叉验证、参考已知数据库,并设计合理的功能实验,可以高效定位关键修饰位点,解析蛋白质功能调控机制。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









