







1.前言
在详细的介绍了哈希之后,那么由哈希思想构成的函数有哪些呢?哈希思想能够应用在哪呢?
本章重点:
着重介绍哈希函数的接口以及哈希思想的相关应用场景。
2.unordered_set函数
2.1 预备知识
【unordered_set】是STL中的容器之一,不同于普通容器,它的查找速度极快,常用来存储各种经常被检索的数据,因为容器的底层是【哈希表】。除此之外,还可以借助其特殊的性质,解决部分难题。
关联式容器如下所示:
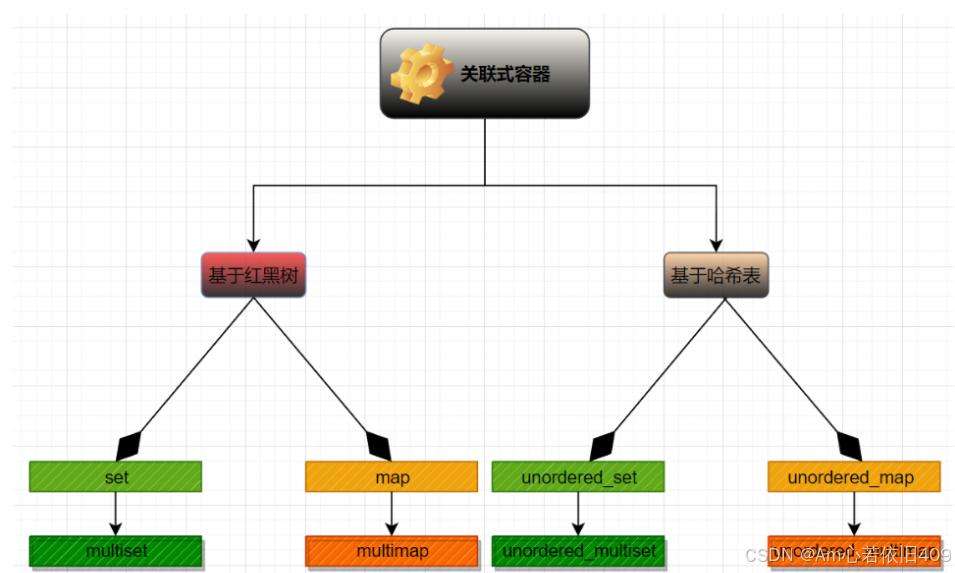
关联式容器基于底层实现的结构不同,所以分成了如上四种形式。
那么由引出了什么是关联式容器呢?
我们之前学习到的vector,list,string,deque等都是序列式容器,序列式容器就是底层的数据结构是以线性序列的数据结构。
- 【关联式容器】 则比较特殊,其中存储的是
<key, value>的 键值对,这就意味着可以按照 键值大小key以某种特定的规则放置于适当的位置,关联式容器 没有首尾的概念,因此没有头插尾插等相关操作,本文中学习的unordered_set,unordered_map就属于 关联式容器
2.2 为什么要有unordered_set
我们前面学习了set,他的查找效率是Log(N),但是当数据过多时,他的查找效率是基于高度的,有时候效率也不一定能理想的达到Log(N)。因此有天才大佬提出了,能不能提供一种查询效率接近于O(1)的容器呢。于是unordered_set就出现了。
2.3 unordered_set介绍
unordered_ set 是 存储 没有特定顺序的唯一元素的容器,允许基于它们的值快速检索单个元素。
- 在unordered_set中,元素的值同时也是唯一标识它的键。键是不可变的,因此,在容器中不能修改unordered_set中的元素,但是可以插入和删除它们。
- 在内部,unordered_set中的元素没有按照任何特定的顺序排序,而是根据它们的散列值组织到bucket中,以便通过它们的值直接快速访问单个元素(平均时间复杂度为常数)。
- Unordered_set容器在按键访问单个元素时比set容器快,尽管它们在通过其元素子集进行范围迭代时通常效率较低。
- 容器中的迭代器至少是前向迭代器。
构造函数
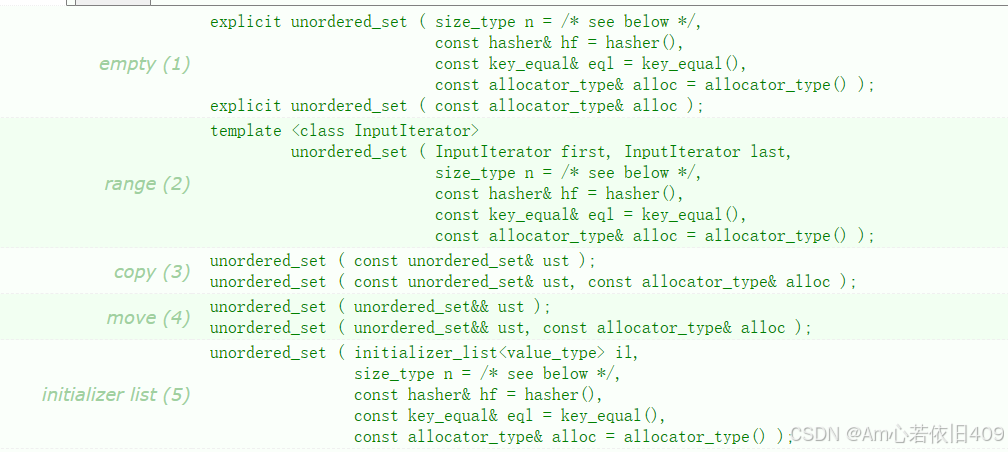
(1)构造一个某个类型的容器
unordered_set<int> s1; // 构造int类型的空容器
(2)拷贝构造某个类型的容器
unordered_set<int> us2(us1); // 拷贝构造同类型容器us1的复制品
(3)使用迭代器区间进行初始化构造
string str("helloworld");
unordered_set<char> us3(str.begin(), str.end()); // 构造string对象某段区间的复制品
容量函数

这几个接口从开始学就在介绍了,这里就不过多的讲解了。
迭代器函数

begin就是指向哈希表中的第一个元素,end就是指向最后一个元素。挂接在桶下面的元素不管,只关心在顺序表中最前面位置的元素。
插入、删除函数
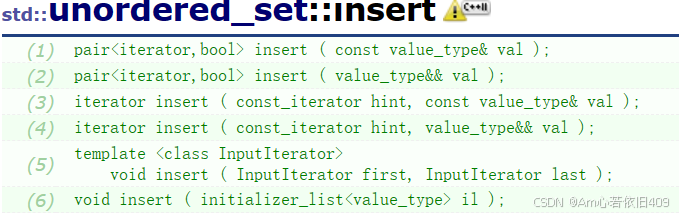
insert函数
每个元素只有在它不等同于容器中已经存在的任何其他元素时才会被插入,也就是说unordered_ set 中的每个元素是唯一的。
代码示例:
void test_unordered()
{
unordered_set<int> us1;
// 插入元素
us1.insert(4);
us1.insert(5);
us1.insert(2);
us1.insert(2);
us1.insert(1);
us1.insert(3);
us1.insert(3);
// 遍历
for (auto e : us1)
{
cout << e << " ";// 4 5 2 1 3
}
}erase函数

移除容器中某个元素,在使用erase的时候需要搭配find函数来使用
find函数

返回找到了该元素所在位置的迭代器
删除和查找示例:
void test_unordered()
{
unordered_set<int> us;
// 插入元素
us.insert(4);
us.insert(5);
us.insert(2);
us.insert(2);
us.insert(1);
us.insert(3);
us.insert(3);
//有可能pos是空,即这个元素不在容器里面
unordered_set<int>::iterator pos = us.find(3);
if (pos != us.end())
{
us.erase(pos); // 删除元素3
cout << "删除成功" << endl;
}
else
{
cout << "删除失败" << endl;
}
us.erase(5);
// 遍历
for (auto e : us)
{
cout << e << " ";
}
}一些重要的相关函数接口就介绍到这里,有更多兴趣的可以阅读下面连接:
unordered_set::bucket_count - C++ Reference (cplusplus.com)
2.4 unordered_set和set的区别
set和unordered_set是 C++ 标准模板库(STL)中的两种关联容器,它们都有存储唯一元素的特性,但它们在底层实现、元素存储顺序、查找和插入的性能上存在显著的区别。
set:使用自平衡二叉搜索树实现,元素是有序的,适合需要有序存储的场景,操作的时间复杂度是 O(logn)。unordered_set:使用哈希表实现,元素是无序的,适合只关心元素存在性而不关心顺序的场景,操作的时间复杂度在理想情况下是 O(1)。
set只要一经放入,那么出来的元素必定是被排成了有序元素,而对于unordered_set来说,她出来的元素是无序的,然后对于查找某个元素是否在容器里,他就比set更胜一筹了。
3.unorederde_map函数
3.1 unordered_map介绍
unordered_map 是存储 <key, value> 键值对 的关联式容器,其允许通过keys快速的索引到与其对应的value。
- 在 unordered_map 中,键值通常用于惟一地标识元素,而映射值是一个对象,其内容与此键关联。键和映射值的类型可能不同。
- 在内部 unordered_map 没有对 <kye, value> 按照任何特定的顺序排序, 为了能在常数范围内找到key所对应的value,unordered_map将相同哈希值的键值对放在相同的桶中。
- unordered_map容器通过key访问单个元素要比map快,但它通常在遍历元素子集的范围迭代方面效率较低。
- unordered_map实现了直接访问操作符(operator[ ])(unordered_set里面没有),它允许使用key作为参数直接访问value。
- 它的迭代器是单向迭代器。
3.2 相关函数接口介绍
构造函数
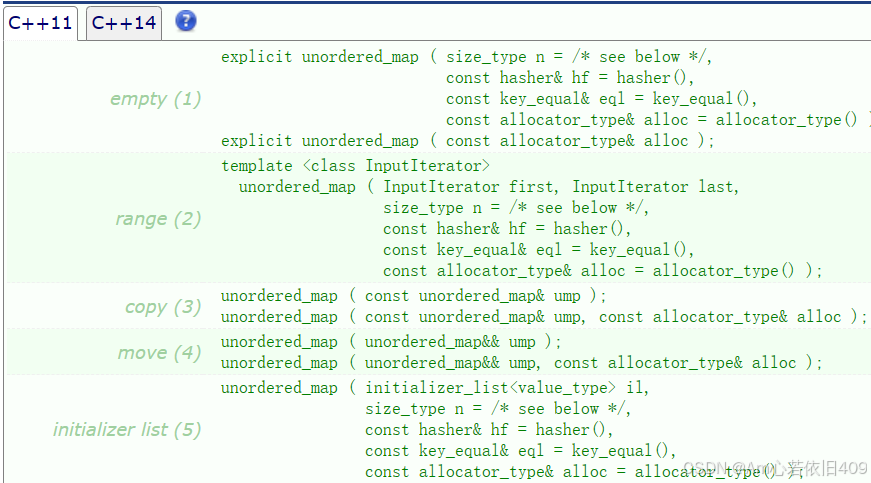
空构造
unordered_map<int,int> res;//key值的类型是int,value的类型也是int拷贝构造:
unordered_map<int,int> ret(res);迭代器区间构造
unordered_map<string, int> s({ {"apple", 1}, {"lemon", 2}});
unordered_map<int,int> res(s.begin(),s.end());容量相关函数 max_size就是容器能够容纳的最多的元素的个数
max_size就是容器能够容纳的最多的元素的个数
访问相关函数

operator[]解释

解释:
1.如果k与容器中某个元素的键匹配,则该函数返回对其映射值的引用。
2.如果k与容器中任何元素的键不匹配,则该函数用该键插入一个新元素,并返回对其映射值的引用。注意,这总是将容器的大小增加1,即使没有将映射值赋给元素(元素是使用其默认构造函数构造的。
3.类似的成员函数unordered_map::at在具有键的元素存在时具有相同的行为,但在不存在时抛出异常。
代码示例如下:
#include <iostream>
#include <string>
#include <unordered_map>
int main ()
{
std::unordered_map<std::string,std::string> mymap;
mymap["Bakery"]="Barbara"; // new element inserted
mymap["Seafood"]="Lisa"; // new element inserted
mymap["Produce"]="John"; // new element inserted
std::string name = mymap["Bakery"]; // existing element accessed (read)
mymap["Seafood"] = name; // existing element accessed (written)
mymap["Bakery"] = mymap["Produce"]; // existing elements accessed (read/written)
name = mymap["Deli"]; // non-existing element: new element "Deli" inserted!
mymap["Produce"] = mymap["Gifts"]; // new element "Gifts" inserted, "Produce" written
for (auto& x: mymap) {
std::cout << x.first << ": " << x.second << std::endl;
}
return 0;
}at函数

解释:在容器中那么就返回其引用值,不在容器中那么就抛异常
示例:
#include <iostream>
#include <string>
#include <unordered_map>
int main ()
{
std::unordered_map<std::string,int> mymap = {
{ "Mars", 3000},
{ "Saturn", 60000},
{ "Jupiter", 70000 } };
mymap.at("Mars") = 3396;
mymap.at("Saturn") += 272;
mymap.at("Jupiter") = mymap.at("Saturn") + 9638;
for (auto& x: mymap) {
std::cout << x.first << ": " << x.second << std::endl;
}
return 0;
}结果:Saturn: 60272 Mars: 3396 Jupiter: 69910
3.3 插入删除相关函数
Insert函数
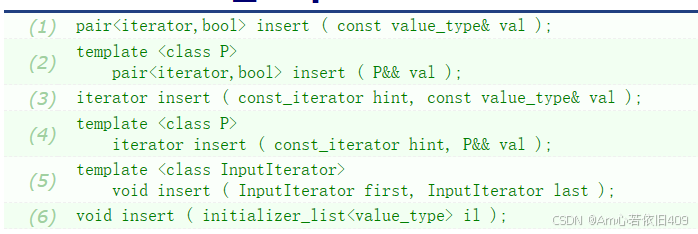
解释:
在unordered_map中插入新元素。
只有当每个元素的键与容器中已有的任何其他元素的键不相等时(unordered_map中的键是唯一的),才会插入该元素。(这里一般都用key来进行比较)
这有效地通过插入的元素数量增加了容器的大小。
形参决定插入多少个元素以及将元素初始化为哪些值:
Erase函数

可以删除某个迭代器位置,也可以直接删除key值,还可以删除一个迭代器区间内的值
代码示例:
#include <iostream>
#include <string>
#include <unordered_map>
int main ()
{
std::unordered_map<std::string,std::string> mymap;
// populating container:
mymap["U.S."] = "Washington";
mymap["U.K."] = "London";
mymap["France"] = "Paris";
mymap["Russia"] = "Moscow";
mymap["China"] = "Beijing";
mymap["Germany"] = "Berlin";
mymap["Japan"] = "Tokyo";
// erase examples:
mymap.erase ( mymap.begin() ); // erasing by iterator
mymap.erase ("France"); // erasing by key
mymap.erase ( mymap.find("China"), mymap.end() ); // erasing by range
// show content:
for ( auto& x: mymap )
std::cout << x.first << ": " << x.second << std::endl;
return 0;
}输出结果:Russia: Moscow Japan: Tokyo U.K.: London
一些重要接口就全部介绍完了,如还想了解其他的函数接口,可以阅读下面文章
unordered_map - C++ Reference (cplusplus.com)
4. 哈希思想的应用
哈希最常用的就是unordered序列的容器,然后判断一个元素在不在容器里面,那么如果当数据有100亿呢?那么你再使用这种容器来存储,那么就不太合理了。但是可以用这种思想来解决一些数据量过大的问题。
主要提出两个应用:位图和布隆过滤器。
4.1 位图概念
在介绍位图前,我们先看一道简单的题目。
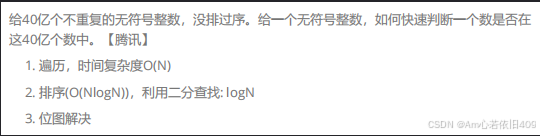
如果要使用unordered_set来解决40亿个整数,一个整数占4四节,总共大约占16个G的内存空间并且set容器中不止有整型数据,还有其他的数据,所以不能用set!
而一个数在或不在可以用1/0来表示也就是说其实只需要一个比特位就可以知道一个数在不在其中.
此时,位图就出现了。
位图概念
所谓位图,
就是用每一位来存放某种状态,适用于海量数据,数据无重复的场景。通常是用来判断某个数据存不存在的
举例说明:
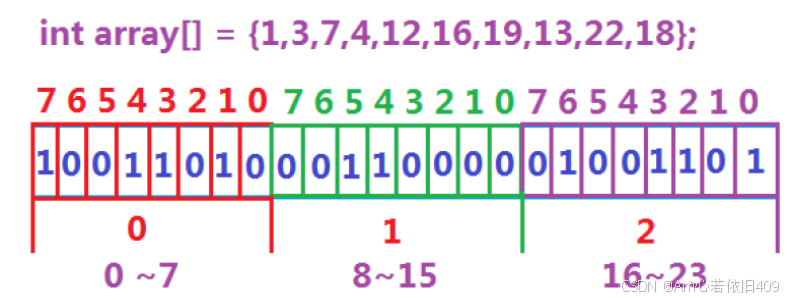
判断1~22中哪些数据是存在的只需要用三个整型也就是24个比特位的空间,同理,40亿个数据也用不着16G的内存,使用0.5G内存的位图即可判断一个数在不在!
先遍历这40亿个数据,把40亿个数据加到对应的位图里面,然后对于一个数在不在,直接通过找到找哪一个字节里面,然后再找在哪一个字节里面的哪一个比特位。
方法: tmp1=x/8; tmp2=x%8; 其中tmp1先找到在哪个字节里面,然后tmp2找到在字节里面的那一个比特位。并且把这一位置为1
4.2 布隆过滤器概念
位图有一个缺陷,那就是只能判断整型是否存在遇见字符串等类型的数据就很难处理了
而在我们现实生活中,很少能见到只有整型的场景,大部分都是要使用字符串的场景,所以在这种情况下位图就不能满足要求了。因此提出了布隆过滤器来解决这个问题。
概念
布隆过滤器是由布隆在1970年提出的 一种紧凑型的、比较巧妙的概率型数据结构,特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”,它是用多个哈希函数,将一个数据映射到位图结构中。此种方式不仅可以提升查询效率,也可以节省大量的内存空间
举例说明:
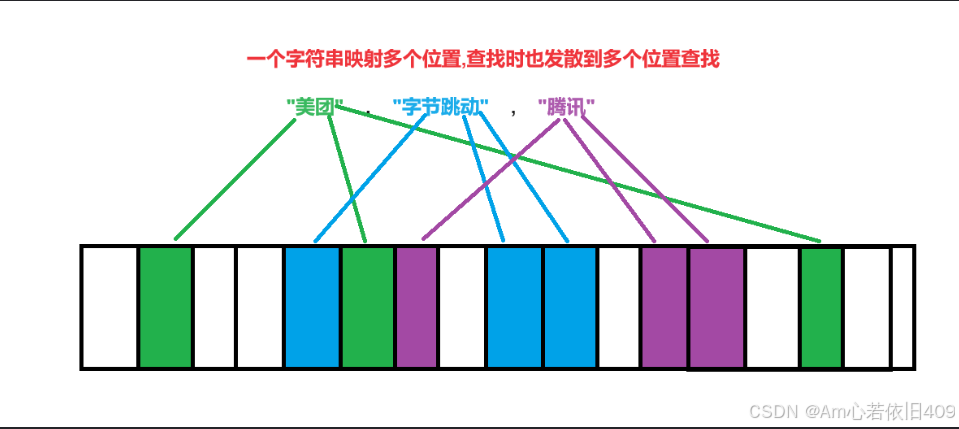
在查找腾讯时,要判断映射的这些位置是否均为1。
布隆过滤器的底层原理:
其实简单来说布隆过滤器就是在位图的基础上,增加了多个映射函数,通过映射函数把他映射到不同的位置。然后在不在就根据映射的值是否为1。
先解决怎么把字符串映射成整数的问题?--用不同的映射函数
//三个不同的字符串映射成整数的函数
struct HashBKDR
{
size_t operator()(const string& key)
{
size_t val = 0;
for (auto ch : key)
{
val *= 131;
val += ch;
}
return val;
}
};
struct HashAP
{
size_t operator()(const string& key)
{
size_t hash = 0;
for (size_t i = 0; i < key.size(); i++)
{
if ((i & 1) == 0)
hash ^= ((hash << 7) ^ key[i] ^ (hash >> 3));
else
hash ^= (~((hash << 11) ^ key[i] ^ (hash >> 5)));
}
return hash;
}
};
struct HashDJB
{
size_t operator()(const string& key)
{
size_t hash = 5381;
for (auto ch : key)
hash += (hash << 5) + ch;
return hash;
}
};
通过上述函数可以把不同的字符串映射转换成整数。
那么当转换成整数之后又该怎么办呢? 是映射到布隆过滤器的哪一个位置呢?
和位图一样,先找到在哪一个字节,然后找到在哪一个字节的哪一个比特位上,把那个比特位置为1即可。
4.3 布隆过滤器的优缺点
布隆过滤器查找一个元素的过程是很迷幻的。通过上述概念分析可以发现,由于有多个映射函数,且在不在要判断映射的值是否都为1。那么当数据很多,空间很小时,那么哪怕没有映射即不在容器的,也有可能会被误判为在容器里面。
所以综上可知:判断是否在一个容器里面,通过布隆过滤器可知,不在一定是准确的,
而对于在则时不准确的,可能存在误判。
例如:
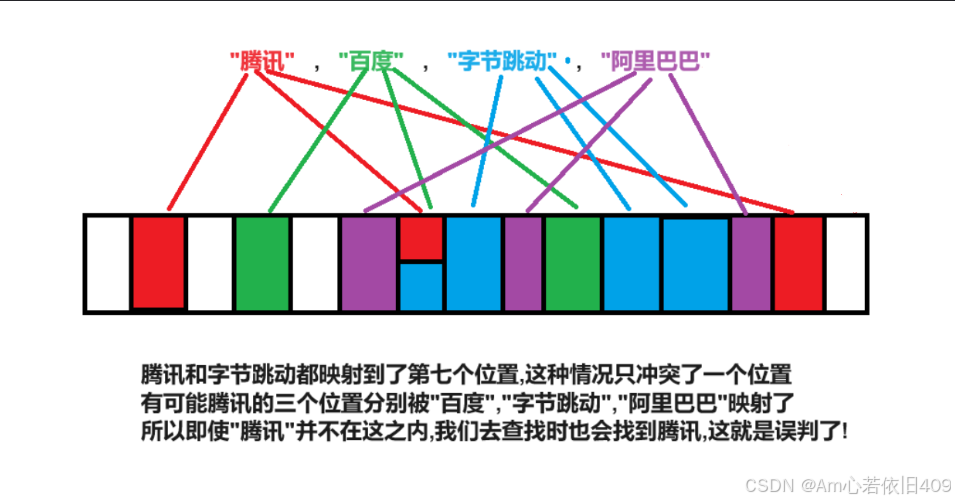
且由于它是通过多个函数映射的,有可能多个不同的值,可能映射到某一个相同的位置,如果布隆过滤器支持删除的话,那么就会导致结果出现问题。所以说布隆过滤器是不能支持删除函数的。

5.总结与拓展
虽说无脑用哈希,但是哈希还是要好好认真学的,一旦对概念理解不准确,就有可能导致认知错误。
拓展:
哈希在应对海量数据的时候是一个很好的手段,有兴趣的可以阅读以下文章:

















 9220
9220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









