







理解Scrapy框架各个组成的作用:五大组成,下载器,调度器,引擎,爬虫,管道。
引擎:它是整个Scrapy框架的核心,用来处理整个系统的数据流,触发各种事件。用于控制调度器,下载器,爬虫,管道。
爬虫:用户可以通过正则,xpath等语法从特定的网页中提取需要的信息,即实体(Item).。也可以提取出链接,让Scrapy继续抓取下一个页面。
实体管道:用于接收爬取到的数据,以便于进一步处理,比如可以存入数据库,本地文件等进行持久化存储。
下载器:用于高速地下载网络上的资源。它是建立在twisted这个高效的异步模型上。
调度器:其就是一个url的优先队列,由它来决定下一个要抓取的网址是什么,同时去掉重复的网址。可以根据需求定制调度器。
Scrapy爬取链家网一个页面数据并且保存到本地文件:
需要爬取的链接:北京二手房房源_北京二手房出售|买卖|交易信息(北京链家) (lianjia.com)
一,明确需要爬取的数据
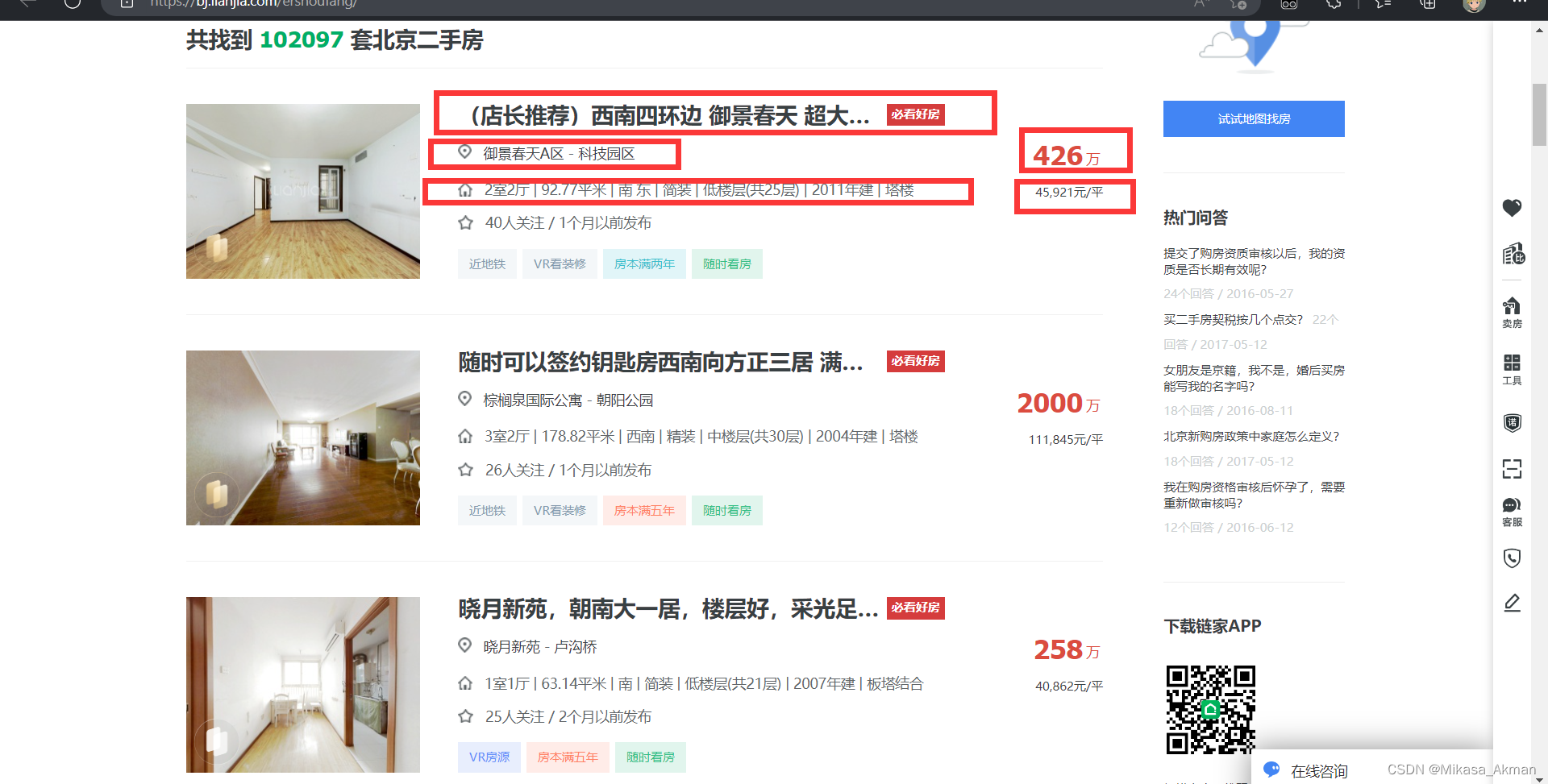
创建一个Item(实体)类,这里我们要爬取的数据有
标题,位置,房屋信息,总价和均价,对此我们可以在items.py文件中定义一个
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3581
3581

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









