




文章目录
一、网站分析
- 链接分析
- 城市链接
北京:https://bj.lianjia.com/ershoufang/
成都:https://cd.lianjia.com/ershoufang/
四川:https://sc.lianjia.com/ershoufang/
…
可见,不同城市,将标红处改为城市的首字母小写即可。 - 页面链接
第一页:https://cd.lianjia.com/ershoufang/pg1
第二页:https://cd.lianjia.com/ershoufang/pg2
第三页:https://cd.lianjia.com/ershoufang/pg3
…
可见,将标红处依次递增即可。
- 城市链接
- 数据加载方式
链家的比较简单,网页源码里都有

- 目标信息
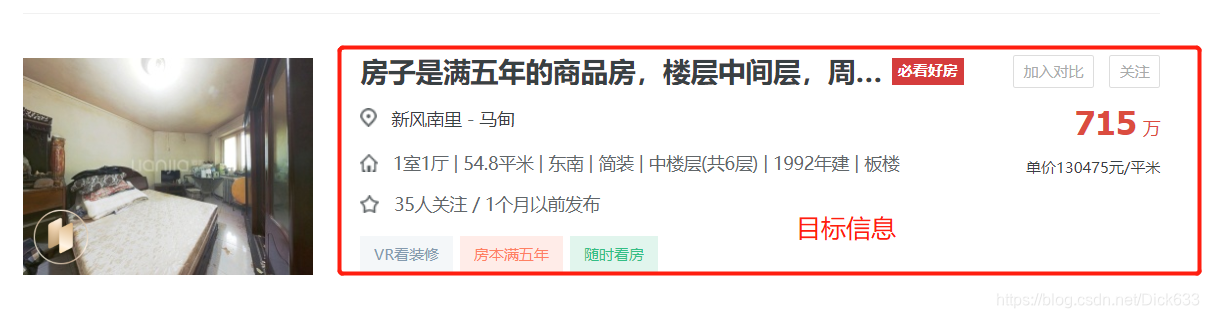
本次抓取目标为上图红框中的关键文字信息。
二、抓取思路
因为信息都在网页源码中,页面链接的生成规律也很简单,所以解决如何生成指定城市的链接即可。
由上述分析可知,城市链接只要将城市名称,如 重庆转为首字母小写 cq,再填入对应位置即可。
其他:
- 设置请求头、免费代理ip实时切换,处理请求异常
- 抓取到的信息存入
mongodb
三、关键代码
- item
import scrapy
class ErshoufangItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field() #房屋title
address = scrapy.Field() #地址
city = scrapy.Field()#所在城市
info = scrapy.Field()#具体信息
totalPrice = scrapy.Field()#总价
unitPrice = scrapy.Field()#单价
- spider
import scrapy
from xpinyin import Pinyin #汉字转拼音的库
from ershoufang.items import ErshoufangItem
pinyin = Pinyin()
CRAWL_PAGE = 10 #爬取页数
class LianjiaSpider(scrapy.Spider):
name = 'lianjia'
def __init__(self 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6144
6144

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









