







 该博客详细记录了一项数据处理任务,包括删除异常行、统计动作数量、筛选特定列及组合数据等步骤。通过Python对CSV文件进行读写操作,实现了数据清洗、动作计数、列筛选和数据重组,最终生成了符合要求的输出文件。
该博客详细记录了一项数据处理任务,包括删除异常行、统计动作数量、筛选特定列及组合数据等步骤。通过Python对CSV文件进行读写操作,实现了数据清洗、动作计数、列筛选和数据重组,最终生成了符合要求的输出文件。
任务介绍
前情提要:
为了解决大家日益增长的知识需求和止步不前的学习成果之间的矛盾,同时也是为了丰富大家充(wu)实(liao)的业余生活,现特别推出新年大礼包,给大家布置一个简单的数据处理任务。任务主要内容:
本次任务要处理的数据共101227行,样例如下:
18 Jogging 102271561469000 -13.53 16.89 -6.4
18 Jogging 102271641608000 -5.75 16.89 -0.46
18 Jogging 102271681617000 -2.18 16.32 11.07
18 Jogging 3.36
18 Downstairs 103260201636000 -4.44 7.06 1.95
18 Downstairs 103260241614000 -3.87 7.55 3.3
18 Downstairs 103260321693000 -4.06 8.08 4.79
18 Downstairs 103260365577000 -6.32 8.66 4.94
18 Downstairs 103260403083000 -5.37 11.22 3.06
18 Downstairs 103260443305000 -5.79 9.92 2.53
6 Walking 0 0 0 3.214402
1.step1:
将数据集中所有信息异常的行删除。
比如上面的样例中第4行数据只有3个元素,而其他行都有6个元素,所以第4行是信息异常的行,将其删除。再如第12行数据的第3个元素明显也是有问题的,所以它也是信息异常的行,将其删除。
数据集中可能还会存在一些其他异常。
将全部信息处理之后,每行的元素以逗号为分隔符,写入文件test1。
文件test1共100471行,样例如下:
6,Walking,23445542281000,-0.72,9.62,0.14982383
6,Walking,23445592299000,-4.02,11.03,3.445948
6,Walking,23470662276000,0.95,14.71,3.636633
...
2.step2:
统计文件test1的数据中所有动作的数目并打印到屏幕,然后将动作数目对100取整后写入test2文件,多余的信息行抛弃。比如统计出Jogging的数量为3021次,则在屏幕上打印Movement: Jogging Amount: 3021,然后将前3000行信息写入test2文件。
文件test2共100200行。
3.step3:
读取文件test2的数据,取每行的后3列元素,以空格为分隔符写入文件test3。
文件test3共100200行,样例如下:
-0.72 9.62 0.14982383
-4.02 11.03 3.445948
0.95 14.71 3.636633
...
4.step4:
读取文件test3的数据,每行数据为一组,每组组内的元素以空格为分隔符,组与组之间的数据以逗号为分隔符,每20组元素为一行,写入文件finally。
文件finally共5010行,样例如下:
-0.72 9.62 0.14982383,-4.02 11.03 3.445948,0.95 14.71 3.636633,-3.57 5.75 -5.407278,-5.28 8.85 -9.615966,-1.14 15.02 -3.8681788,7.86 11.22 -1.879608,6.28 4.9 -2.3018389,0.95 7.06 -3.445948,-1.61 9.7 0.23154591,6.44 12.18 -0.7627395,5.83 12.07 -0.53119355,7.21 12.41 0.3405087,6.17 12.53 -6.701211,-1.08 17.54 -6.701211,-1.69 16.78 3.214402,-2.3 8.12 -3.486809,-2.91 0 -4.7535014,-2.91 0 -4.7535014,-4.44 1.84 -2.8330324
验收内容为:
4个*.py文件
test1.pytest2.pytest3.pyfinally.py
4个运行Python脚本后生成的文件
test1test2test3finally
我的处理:
step1:
思路:这个异常处理是类似于书中的筛选特定的行,通过观察发现一行是六个数据少于或多出都为异常,同时可以看出每行第三个数据不为0,所以为等于0的行也属于异常数据。所以需要筛选出少于六个数据以及第三个数据为0的异常行。
import csv
#创建输入输出文件对象
with open('OriginalData.csv','r',newline='')as csv_in_file:
with open('temp1_1.csv','w',newline='')as csv_out_file:
filereader = csv.reader(csv_in_file)
filewriter = csv.writer(csv_out_file)
#运用for循环遍历满足条件的数据,并将它们写入输出文件
for row in filereader:
if len(row) == 6 and int(row[2]) !=0 :
filewriter.writerow(row)
temp1处理结果:
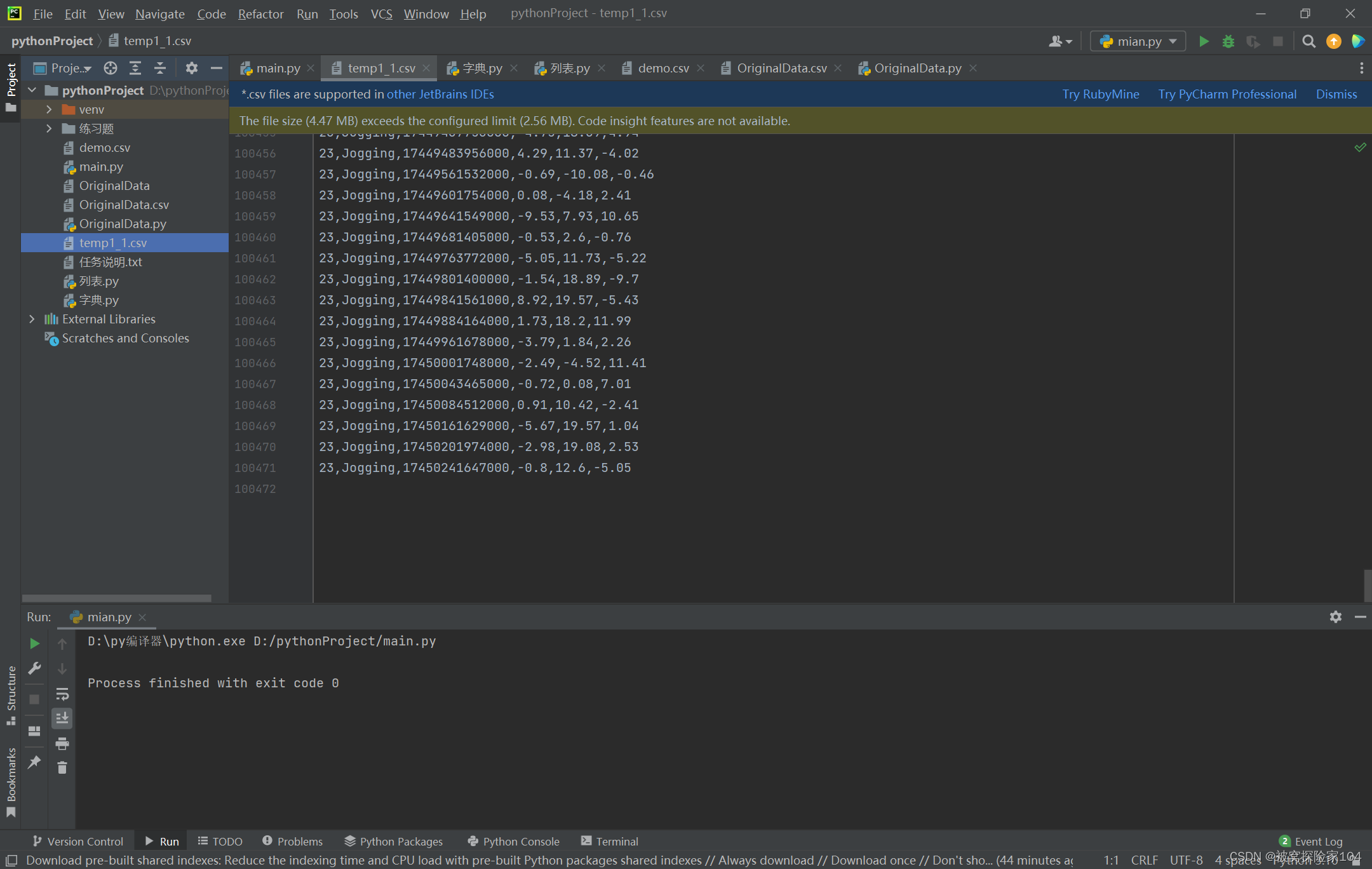
step2:
思路:这个数据处理我理解是可以用字典来解决,在统计每种动作数量时,可以构成键值对一一对应。统计后将动作数目对100取整计入。
import csv
move_Dict = {}
list = []
with open('temp1_1.csv','r',newline='')as csv_in_file:
filereader = csv.reader(csv_in_file)
for row in filereader:
move_Dict[row[1]] = move_Dict.get(row[1],0)+1
#这一步是为每种动作数量进行统计,row[1]代表每一行第二个元素即动作名称
for move, move_Dict[move] in move_Dict.items():
print('Movement: %5s\t' % move, end='')
print('Amount: %d' % move_Dict[move])
move_Dict[move] = move_Dict[move] // 100 * 100
list.append(move_Dict[move])
#运用seek函数,用来移动文件读取指针到指定位置。
csv_in_file.seek(0, 0)
#在输出文件的时候,使动作分别计数,每写入一次让计数器+1
with open('temp2_2.csv', 'w', newline='') as csv_out_file:
filewriter = csv.writer(csv_out_file)
Walking = 0
Jogging = 0
Downstairs = 0
Upstairs = 0
Sitting = 0
Standing = 0
for row_list in filereader:
if row_list[1] == 'Jogging' and Jogging < list[1]:
Jogging += 1
filewriter.writerow(row_list)
if row_list[1] == 'Upstairs' and Upstairs < list[2]:
Upstairs += 1
filewriter.writerow(row_list)
if row_list[1] == 'Downstairs' and Downstairs < list[3]:
Downstairs += 1
filewriter.writerow(row_list)
if row_list[1] == 'Standing' and Standing < list[4]:
Standing += 1
filewriter.writerow(row_list)
if row_list[1] == 'Sitting' and Sitting < list[4]:
Sitting += 1
filewriter.writerow(row_list)
if row_list[1] == 'Walking' and Walking < list[0]:
Walking += 1
filewriter.writerow(row_list)
temp2处理结果:
统计次数如下:
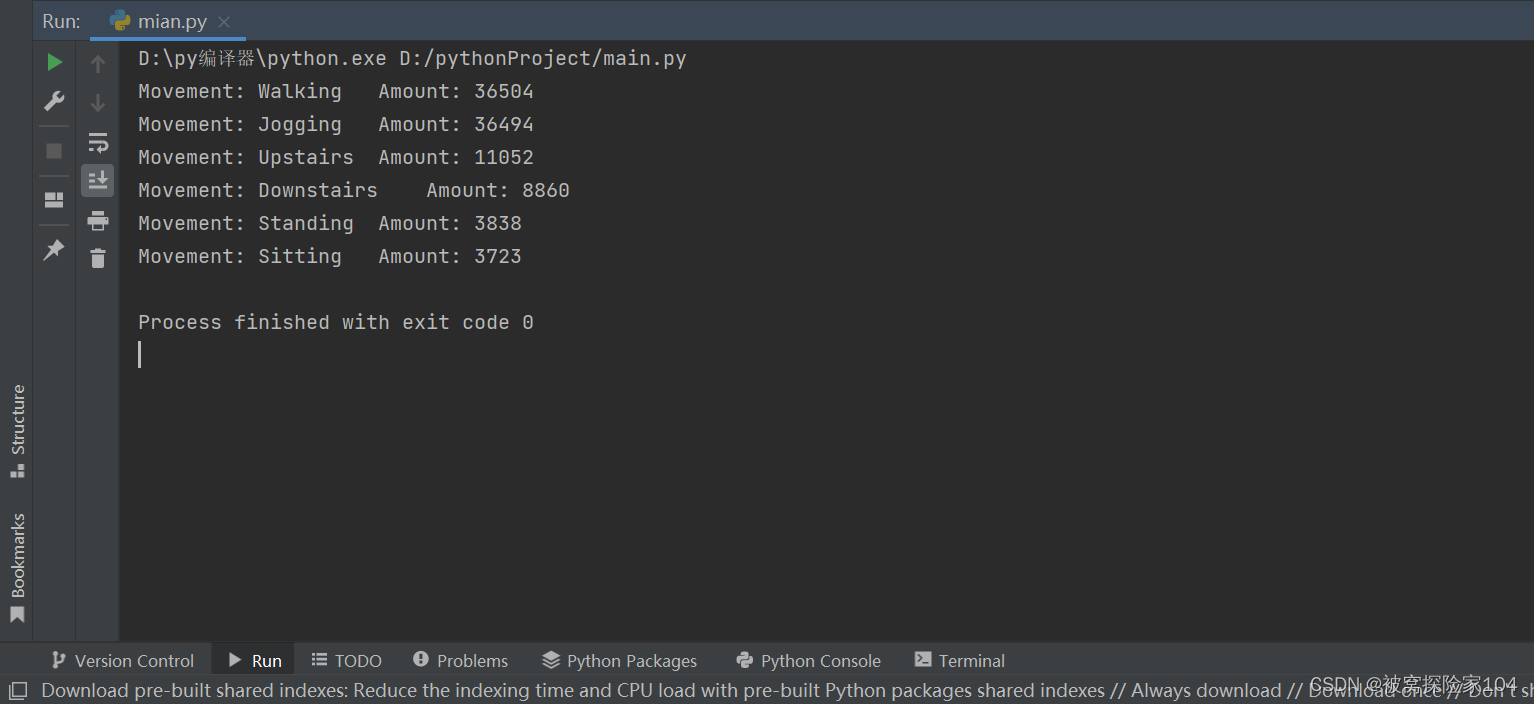
处理后共计:100200
step3:
思路:这个数据处理类似于书中筛选特定的列
import csv
my_num = [3,4,5]
with open('temp2_2.csv', 'r', newline = '') as csv_in_file:
with open('temp3_1.csv', 'w', newline = '') as csv_out_file:
filereader = csv.reader(csv_in_file)
filewriter = csv.writer(csv_out_file,delimiter = ' ')
#用列表筛选需要保存的列,用append函数将需要保存的列加入另一个空列表中。最后将列表l以文件形式写入
for row_list in filereader:
l = []
for index_value in my_num:
l.append(row_list[index_value])
filewriter.writerow(l)
temp3处理结果:
共计:100200行
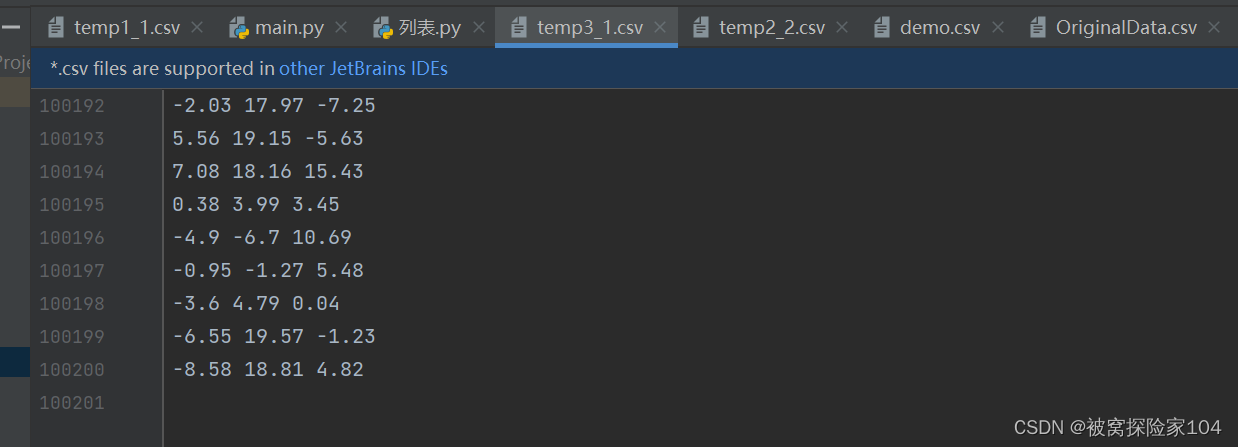
step4:
思路:相当于在大列表里在嵌套一个小列表
import csv
list1=[]
list2=[]
Temp = 0
with open('temp3_1.csv', 'r', newline = '') as csv_in_file:
with open('temp4_1.csv', 'w', newline = '') as csv_out_file:
filereader = csv.reader(csv_in_file)
filewriter = csv.writer(csv_out_file)
for row in filereader:
list1.append(' '.join(row))
for line in list1:
if Temp < 20:
list2.append(line)
Temp += 1
#每循环20次后,将list2列表置空,直到遍历所有的行
if Temp == 20:
filewriter.writerow(list2)
list2 = []
Temp= 0
temp4处理结果:
共计:5010行
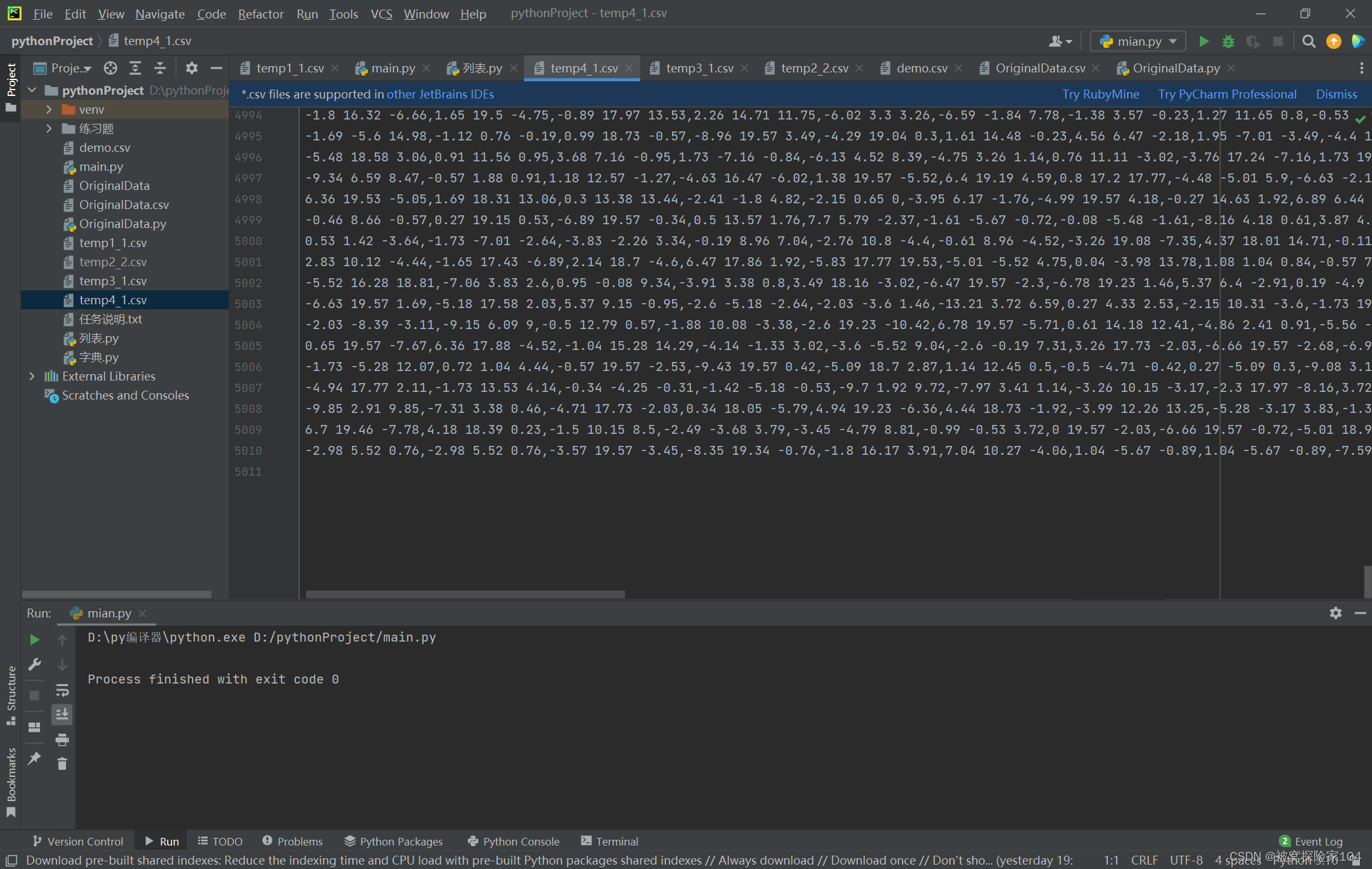
总结:
通过本次任务进一步了解了csv文件的处理操作,同时复习了很多有关函数的知识点,发现前面学习过的知识还是有所欠缺,很多东西在第一遍只是一个片面的了解,而只用运用的时候才会发现哪些地方是学懂了,哪些是还存在问题。本次任务到这里就结束啦!


















 3535
3535

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











