






1.什么是Faiss?
简介
Faiss 是由 Facebook AI Research(FAIR)开发的一个用于高效相似性搜索和密集向量聚类的库。它特别适合于那些需要处理大量数据集和高维向量的情景。Faiss 提供了一种快速搜索空间中最近邻(Nearest Neighbor)的方法,对于机器学习和数据科学领域的应用来说非常有用。
主要特点
- 高效性能:对大规模数据集进行快速搜索。
- 支持大规模数据:能够处理数十亿级别的向量。
- 灵活性:支持多种索引类型和搜索策略。
- 可扩展性:可用于多种硬件平台,包括GPU。
安装
你可以通过 conda 安装 Faiss(Faiss 是基于 C++ 开发的引擎,在 win 下可能会有各种 C++ 上的编译问题,这里建议用 conda 安装,成功率会比 pip 大很多):
conda install conda-forge::faiss-cpu基本用法
数据准备
在开始之前,我们首先需要一组数据向量。在这个例子中,我们将使用随机生成的数据。
import numpy as np
# 生成随机数据
d = 64 # 向量维数
nb = 10000 # 数据库大小
np.random.seed(1234) # 保证结果可复现
db_vectors = np.random.random((nb, d)).astype('float32')
db_vectors.shape 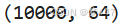
创建索引
Faiss 使用“索引”来存储和搜索数据。让我们创建一个简单的索引。
import faiss
# 构建索引
index = faiss.IndexFlatL2(d) # 使用 L2 距离
print(f"索引是否需要训练:{index.is_trained}")
# 添加数据到索引中
index.add(db_vectors)
print(f"索引中的向量数: {index.ntotal}")![]()
进行搜索
现在我们有了索引和数据,可以执行最近邻搜索。
nq = 5 # 查询数量
np.random.seed(1234) # 保证结果可复现
query_vectors = np.random.random((nq, d)).astype('float32')
# 搜索最近的 k 个向量
k = 4
distances, indices = index.search(query_vectors, k)
print(f"距离:\n{distances}")
print(f"索引:\n{indices}")
2.输入解析 Faiss 运行原理
简介
在本节中,我们将深入探讨 Faiss 的核心组成部分————索引类型,并理解它们是如何高效处理大规模数据集的。Faiss 通过提供多种索引结构,能够针对不同的数据集和需求提供最优的搜索策略。
Faiss 索引类型详解
Faiss 提供了多种索引类型,每种类型都适合于特定的应用场景和数据规模。以下是一些常见的索引类型:
1. Flat 索引(IndexFlat)
- 概述:Flat 索引是最基本的 Faiss 索引类型,提供精确的最近邻搜索。
- 特点:简单易用,但在大规模数据集上效率较低。
- 使用场景:小型数据集或对精度要求极高的场景。
2. 倒排索引(IndexIVF)
- 概述:倒排文件索引(IVF)将数据空间划分成多个量化的聚类(clusters),然后在这些聚类内进行搜索。
- 特点:比 Flat 索引更高效,尤其适用于中等规模的数据集。
- 使用场景:需要在保持较高搜索效率的同时处理较大数据集。
3. 乘积量化索引(IndexPQ)
- 概述:乘积量化(Product Quantization,PQ)进一步压缩数据,使其适合非常大的数据集。
- 特点:极大地减少了内存占用,但搜索是近似的。
- 适用场景:大规模数据集,当内存占用是一个关键考虑因素时。
| 索引类型 | 时间效率 | 空间效率 | 准确度 | 使用场景 |
|---|---|---|---|---|
| IndexFlat | 低(线性搜索时间) | 低(存储原始向量) | 高(精确搜索) | 小型数据集或对精度要求极高的场景 |
| IndexIVF | 中(快于Flat) | 中(需要额外存储聚类信息) | 中(准确度较高) | 需要在保持较高搜索效率的同时处理较大数据集 |
| IndexPQ | 高(快速搜索) | 高(高度压缩数据) | 低(近似搜索) | 大规模数据集,当内存占用是一个关键考虑因素时 |
示例代码:使用不同类型的索引
创建 Flat 索引
import faiss
import numpy as np
d =64 # 向量维度
nb = 10000 # 数据库大小
data = np.random.random((nb, d)).astype('float32')
# 创建 Flat 索引
index_flat = faiss.IndexFlatL2(d)
index_flat.add(data)创建 IVF 索引
nlist = 100 # 聚类中心的数量
quantizer = faiss.IndexFlatL2(d) # 使用 Flat 索引作为量化器
index_ivf = faiss.IndexIVFFlat(quantizer, d, nlist, faiss.METRIC_L2)
# 训练索引
index_ivf.train(data)
index_ivf.add(data)创建 PQ 索引
m = 8 # 子向量的数量
index_pq = faiss.IndexPQ(d, m, 8) # nbits = 8每个子向量比特数
index_pq.train(data)
index_pq.add(data)进行搜索
nq = 5 # 查询数量
np.random.seed(1234) # 确保结果可复现
query_vectors = np.random.random((nq, d)).astype('float32')
# 搜索最近的 k 个向量
k = 4
distances_flat, indices_flat = index_flat.search(query_vectors, k)
distances_ivf, indices_ivf = index_ivf.search(query_vectors, k)
distances_pq, indices_pq = index_pq.search(query_vectors, k)
print(f'index_flat 距离:\n{distances_flat}')
print(f'index_flat 索引:\n{indices_flat}')
print()
print(f'index_ivf 距离:\n{distances_ivf}')
print(f'index_ivf 索引:\n{indices_ivf}')
print()
print(f'index_pq 距离:\n{distances_pq}')
print(f'index_pq 索引:\n{indices_pq}')
print()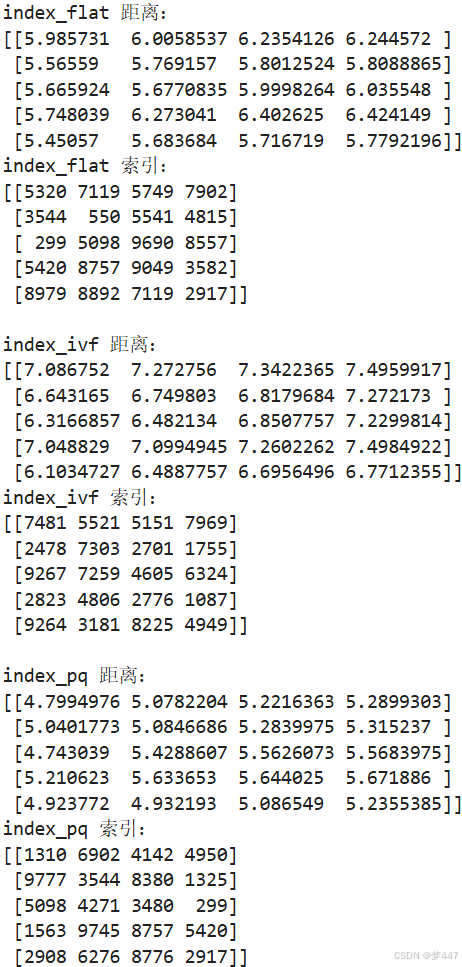
3.Faiss 索引的读写
简介
在使用 Faiss 进行大规模向量搜索时,经常需要保存和加载索引。这一过程对于长期、重复使用同一索引,或者在不同环境之间共享索引非常重要。本节将指导你如何在 Faiss 中保存(写)和加载(读)索引。
索引的保存
保存索引是指将 Faiss 索引存储到磁盘上。这样做可以在以后重新加载同一索引,无需重新构建。
示例代码
import faiss
import numpy as np
# 假设我们有一个已经创建和训练好的索引
d = 64 # 向量维度
index = faiss.IndexFlatL2(d)
# 填充一些随机数据
nb = 10000
np.random.seed(1234)
db_vectors = np.random.random((nb, d)).astype('float32')
index.add(db_vectors)
# 保存索引到磁盘
faiss.write_index(index, "my_index.faiss")这里,我们使用 faiss.write_index 函数将索引保存到文件 my_index.faiss。
索引的加载
加载索引是指从磁盘读取先前保存的 Faiss 索引。这样可以避免重复构建过程,特别是在索引构建成本较高时非常有用。
示例代码
# 加载之前保存的索引
loaded_index = faiss.read_index("my_index.faiss")使用 faiss.read_index 函数可以从文件中加载索引。
4.Wiki 搜索引擎构建教程
我们将使用 wiki2019zh 数据集,构建一个搜索索引,并通过一个基于 Streamlit 的 Web 应用进行搜索。
项目结构
项目分为几个部分:
- 数据预处理(process_data):处理 wiki 数据。
- 索引器(indexer):用于构建搜索索引。
- 搜索器(searcher):用于执行搜索操作。
- Web 应用(app):用户界面,用于接受查询和展示搜索结果。
1. 数据预处理(process_data.py)
处理 wiki 数据,将其转换为 csv 格式
关键点
- wiki 数据集理解:理解 wiki 数据集的组织形式。
- 单个数据转换脚本:将单个 wiki 数据转换为 csv 文件。
- 批量转换脚本:批量将所有数据转换为 csv 文件。
代码逻辑
- 批量遍历 wiki 数据集下所有文件
- 将每个文件转换为 csv 格式,并实时追加到 csv 文件中
2. 索引器(indexer.py)
索引器的目标是将文本数据转换为向量,并用这些向量建立一个 Faiss 索引。
关键点
- 文本向量化:使用 BERT 模型将文本转换为向量。
- Faiss 索引:使用 Faiss 库快速检索相似项。
- 批处理:为提高效率,文本数据以批次方式进行向量化。
代码逻辑
- 从 CSV 文件读取文本数据。
- 将文本数据转换为向量。
- 使用向量建立 Faiss 索引。
- 保存索引和 URL 映射到文件。
3. 搜索器(searcher.py)
搜索器加载之前创建的 Faiss 索引和 URL 映射,以便对用户查询进行搜索。
关键点
- 加载索引:从文件中加载 Faiss 索引。
- 查询处理:将用户查询转换为向量。
- 检索匹配:使用索引查找到最相似的文本项。
代码逻辑
- 加载 Faiss 索引和 URL 映射。
- 将用户查询转换为向量。
- 在索引中搜索最相似的项。
- 返回相应的 URLs。
4. Web 应用(app.py)
Web 应用提供用户界面,允许用户输入搜索查询并显示结果。
关键点
- Streamlit:用于快速构建 Web 应用。
- 交互:接收用户输入并展示结果。
代码逻辑
- 初始化 Streamlit 应用。
- 创建文本输入框用于接收查询。
- 调用搜索器获取结果。
- 展示搜索结果。
运行项目
- 设置环境:确保安装了所有必要的依赖,包括
faiss-cpu、transformers、pandas和streamlit。 - 数据预处理:预处理 wiki 数据。
- 构建索引:首先运行
indexer.py来构建搜索索引。 - 启动 Web 应用:运行
app.py来启动 Streamlit 应用。
streamlit run app.py
- 搜索查询:在 Web 应用中输入查询,查看搜索结果。
模型下载
在PowerShell中运行下面的代码
安装 huggingface_hub
pip install huggingface-hub # 安装最新版
huggingface-cli --version # 验证安装换源(国内镜像源)
$env:HF_ENDPOINT = 'https://hf-mirror.com'基础下载命令
(1) 下载完整模型
huggingface-cli download 模型ID --local-dir 本地路径示例:
huggingface-cli download uer/roberta-base-finetuned-chinanews-chinese --local-dir ./model参数说明:
-
模型ID:格式为组织名/模型名(如bert-base-uncased) -
--local-dir:指定本地保存路径(默认会创建缓存文件夹)
高级下载选项
(1) 选择性下载文件
huggingface-cli download 模型ID --filename pytorch_model.bin --filename config.json适用场景:只需下载模型权重和配置文件,跳过其他文件
(2) 指定分支/版本
huggingface-cli download 模型ID --revision 分支名示例:
huggingface-cli download uer/roberta-base-finetuned-chinanews-chinese --revision main(3) 断点续传
huggingface-cli download 模型ID --resume-download作用:下载中断后,重新执行会从中断处继续
(4) 强制重新下载
huggingface-cli download 模型ID --force-download适用场景:本地缓存损坏时使用
4. 私有模型下载
(1) 登录账号
huggingface-cli login按提示输入账号的Access Token(在设置页生成)
(2) 下载私有模型
huggingface-cli download 组织名/私有模型名5. 国内用户加速下载
export HF_ENDPOINT=https://hf-mirror.com # 使用镜像站
huggingface-cli download 模型ID6. 完整参数列表
| 参数 | 说明 |
|---|---|
--cache-dir | 指定缓存目录(默认~/.cache/huggingface) |
--token | 直接提供Access Token(避免交互式登录) |
--quiet | 静默模式(不显示进度条) |
--num-workers | 并行下载线程数(默认8) |
--exclude | 排除特定文件(如*.safetensors) |
7. 代码集成示例
(1) Python中调用CLI
import os
model_id = "uer/roberta-base-finetuned-chinanews-chinese"
os.system(f"huggingface-cli download {model_id} --local-dir ./model_data")(2) 结合transformers加载
from transformers import AutoModel
model = AutoModel.from_pretrained("./model_data") # 从本地加载8. 常见问题解决
问题1:huggingface-cli: command not found
-
解决方案:
-
python -m pip install --upgrade huggingface_hub
问题2:证书验证失败
export CURL_CA_BUNDLE="" # 临时禁用证书验证(不安全)问题3:下载速度慢
huggingface-cli download 模型ID --num-workers 16 # 增加线程数9. 下载目录结构
成功下载后,本地目录会包含:
model/
├── config.json
├── pytorch_model.bin
├── tokenizer_config.json
└── vocab.txt通过以上方法,你可以高效地下载和管理Hugging Face模型。如需下载大型数据集,建议使用datasets库:
pip install datasets
from datasets import load_dataset
dataset = load_dataset("数据集名")代码展示
process_data.py
import json
import csv
import os
def process_line_to_csv(json_line, csv_writer):
"""
处理单行 JSON 数据,提取内容并写入 CSV 文件
Args:
json_line (str): 单行 JSON 格式的文本数据
csv_writer (csv.writer): CSV 文件写入器对象
return: None
"""
try:
# 解析 JSON 行数据
article = json.loads(json_line)
# 提取文本内容,若不存在 'text' 字段则返回空字符串
content = article.get('text', '')
# 提取 URL,若不存在 'url' 字段则返回空字符串
url = article.get('url', '')
# 将 content + URL 写入 CSV 行
csv_writer.writerow([content, url])
except json.JSONDecodeError:
# 处理 JSON 解析错误(如格式不合法)
print("警告:无法解析的行")
def process_file(json_file_path, csv_writer):
"""
处理单个 JSON 文件,逐行读取并处理
Args:
json_file_path (str): JSON 文件路径
csv_writer (csv.writer): CSV 文件写入器对象
return: None
"""
with open(json_file_path, 'r', encoding='utf-8', newline='') as file:
# 逐行读取大文件,避免内存溢出
for line in file:
process_line_to_csv(line, csv_writer)
def process_directory(directory_path, output_file, num_file=100):
"""
遍历目录处理多个 JSON 文件,生成 CSV 数据集
Args:
directory_path (str): 包含 JSON 文件的根目录路径
output_file (str): 输出的 CSV 文件路径
num_file (int): 最大处理的文件数量(默认100)
return: None
"""
# 创建 CSV 文件并设置 UTF-8 编码(newline='' 避免Windows 空行问题)
with open(output_file, 'w', encoding="utf-8", newline='') as csvfile:
writer = csv.writer(csvfile)
# 写入 CSV 标题行
writer.writerow(['content', 'url'])
file_count = 0 # 已处理的文件计数器
# 遍历目录树 os.walk 生成(root, dirs, files) 元组
for root, dirs, files in os.walk(directory_path):
for file in files:
file_count += 1
# 拼接完整文件路径
json_file_path = os.path.join(root, file)
# 处理当前 JSON 文件
process_file(json_file_path, writer)
# 输出处理进度(f-string格式化)
print(f'Iter:{file_count}/{num_file} Process File: {json_file_path}')
# 到达处理上限后提前终止
if file_count > num_file:
return
if __name__ == "__main__":
# 输入参数配置
wiki_directory = "./data/wiki_zh" # 原始数据集目录(wiki2019zh)
output_csv = "./data/wiki_zh.csv" # 输出 CSV 路径(存储处理结果)
num_file = 1000 # 限制处理的文件数量(避免处理过多文件)
# 执行处理流程
process_directory(wiki_directory, output_csv, num_file)indexer.py
import faiss # Facebook 开源的相似性搜索库
import numpy as np
import pandas as pd
from tqdm import tqdm # 进度条工具
import torch
from transformers import BertTokenizer, BertModel # HuggingFace 的 BERT 模型工具
import os
class Indexer:
def __init__(self, model_name='./uer/roberta-base-finetuned-chinanews-chinese', batch_size=8):
"""
初始化索引构建器
Args:
model_name (str): 预训练语言模型名称(默认中文新闻领域微调的 RoBERTa)
batch_size (int): 批量处理文件时的批次大小(根据 GPU 内存调整)
"""
# 检查 CUDA 可用性,优先使用 GPU 加速
self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(f"使用设备:{self.device.upper()}")
# 加载分词器和 BERT 模型(自动从 HuggingFace 仓库下载)
self.tokenizer = BertTokenizer.from_pretrained(model_name)
self.model = BertModel.from_pretrained(model_name).to(self.device)
# 初始化 Faiss 索引(L2欧式距离的扁平索引,适合小规模数据)
self.index = faiss.IndexFlatL2(768) # BERT 的隐藏层维度为 768
# 配置参数
self.batch_size = batch_size
self.url_mapping = [] # 存储向量与 URL 的映射关系
def texts_to_vectors(self, texts):
"""
将文本批量转换为 BERT 向量
Args:
texts (pd.Series/List): 文本数据集合
Return:
np.ndarray: 文本向量矩阵(shape: [n_samples, 768])
"""
vectors = []
# 使用带进度条的批量处理
for i in tqdm(range(0, len(texts), self.batch_size), desc="文本向量化"):
# 分批提取文本并转换为列表格式
batch_texts = texts[i: i + self.batch_size].tolist()
# 文本编码(自动填充/截断到最大512token)
inputs = self.tokenizer(
batch_texts, # 待处理的文本列表(如 ["文本1", "文本2", ...])
return_tensors='pt', # 返回 PyTorch 张量格式(其他选项:'tf' 返回 TensorFlow 张量,'np' 返回 Numpy 数组)
padding=True, # 自动填充到批次内最长文本长度(可选参数:'longest' 或指定固定长度)
truncation=True, # 自动截断超过 max_length 的文本(从尾部截断,保留头部重要信息)
max_length=512 # BERT 的最大输入长度
)
# 将数据移动到指定设备(GPU/CPU)
inputs = {k: v.to(self.device) for k, v in inputs.items()}
outputs = self.model(**inputs)
# 使用 pooler_output 作为文本表示(CLS 标签的特殊池化结果)
batch_vectors = outputs.pooler_output.detach().cpu().numpy()
vectors.extend(batch_vectors)
return np.array(vectors)
def add_to_index(self, texts, urls):
"""
将文本数据添加到索引系统
Args:
texts (pd.Series): 文本内容列
urls (pd.Series): 对应的 URL 列
"""
vectors = self.texts_to_vectors(texts)
# 将向量添加到 Faiss 索引
self.index.add(vectors) # 索引会自动管理数据存储
# 维护 URL 映射关系(索引位置对应 url_mapping的索引)
self.url_mapping.extend(urls.tolist())
def save_index_and_mapping(self, index_path, mapping_path):
"""
保存索引和映射文件
Args:
index_path (str): Faiss 索引保存路径(通常用 .index 后缀)
mapping_path (str): URL 映射文件路径(建议用 .txt 或 .csv)
"""
# 保存 Faiss 索引到磁盘
faiss.write_index(self.index, index_path)
# 保存 URL 映射关系(每一行一个 URL)
with open(mapping_path, 'w', encoding='utf-8', newline='') as f:
for url in self.url_mapping:
f.write(url + '\n')
def build_index_from_csv(self, csv_file_path):
"""
从 CSV 文件构建索引
Args:
csv_file_path (str): CSV 文件路径,需包含 content 和 url 列
"""
# 读取数据
df = pd.read_csv(csv_file_path)
# 添加数据到索引系统
self.add_to_index(df['content'], df['url'])
if __name__ == "__main__":
# 初始化索引器(自动下载模型约420MB)
indexer = Indexer()
# 构建索引(假设 CSV 文件以存在)
indexer.build_index_from_csv('./data/wiki_zh.csv') # CSV 需包含 content 和 url 列
# 保存索引和映射文件
indexer.save_index_and_mapping(
'./data/wiki_zh.index', # Faiss 索引文件
'./data/wiki_map.txt'
)searcher.py
import faiss # Facebook 开源的相似性搜索库
import numpy as np
from transformers import BertModel, BertTokenizer # HuggingFace 的 BERT 模型工具
import torch
class Searcher:
def __init__(self, index_path, mapping_path, model_name="./uer/roberta-base-finetuned-chinanews-chinese"):
"""
初始化搜索引擎
Args:
index_path (str): Faiss 索引文件的路径
mapping_path (str): URL 映射文件的路径
model_name (str): 预训练语言模型名称(需与构建索引时使用的模型一致)
"""
# 加载 BERT 分词器和模型(确保与索引构建时的模型一致)
self.tokenizer = BertTokenizer.from_pretrained(model_name)
self.model = BertModel.from_pretrained(model_name)
# 加载预构建的 Faiss 索引
self.index = faiss.read_index(index_path)
# 加载 URL 映射关系(索引位置与 URL 一一对应)
self.urls = self.load_url_mapping(mapping_path)
def load_url_mapping(self, mapping_path):
"""
加载 URL 映射文件
Args:
mapping_path (str): 存储 URL 的文本文件路径(每行一个 URL)
Return:
list: 按索引顺序排列的 URL 列表
"""
with open(mapping_path, 'r', encoding='utf-8', newline='') as file:
# 去除换行符并保留原始顺序
urls = [line.strip() for line in file]
return urls
def query_to_vector(self, query):
"""
将查询文本转换为 BERT 向量
Args:
query (str): 搜索关键词/语句(中文)
Return:
np.ndarray: 768 维的文本向量(shape: [1, 768])
"""
# 文本编码(自动填充/截断到最大512token)
inputs = self.tokenizer(
query,
return_tensors='pt', # 返回 PyTorch 张量
padding=True, # 自动填充到相同长度
truncation=True, # 自动截断超长文本
max_length=512 # 与索引构建时保持一致
)
outputs = self.model(**inputs)
# 使用 pooler_output 作为文本表示(CLS标签的特殊池化结果)
vector = outputs.pooler_output.detach().numpy()
return vector
def search(self, query, k=10):
"""
执行相似性搜索
Args:
query (str): 搜索关键词/语句
k (int): 返回结果的数量
Return:
list: 相关度最高的 k 个 URL
"""
query_vector = self.query_to_vector(query)
# Faiss 搜索(返回距离和索引)
# _ : 包含距离的数组(未使用)
# I : 包含索引位置的数组
_, I = self.index.search(query_vector, k)
# 将索引转换为实际 URL (I 的形状为 [1, k])
result = [self.urls[i] for i in I[0]]
return result
if __name__ == "__main__":
# 初始化搜索引擎(需要提前构建索引)
searcher =Searcher(
'./data/wiki_zh.index',
'./data/wiki_map.txt'
)
# 执行搜索(查询“孙悟空”,返回前 5 个结果)
search_results = searcher.search("孙悟空", k=10)
# 打印搜索结果
for url in search_results:
print(url)app.py
# 导入必要库
import streamlit as st # 网页应用框架
from searcher import Searcher # 自定义的搜索引擎类
# 初始化搜索引擎(注意:正式部署时需要优化加载速度)
# 注意:请确保文件路径正确,建议使用绝对路径
searcher = Searcher(
'./data/wiki_zh.index', # Faiss 索引文件路径
'./data/wiki_map.txt'
)
st.title('Wiki 搜索引擎')
# 创建搜索输入框(placeholder 为输入提示)
query = st.text_input(
label='请输入您要搜索的关键词',
placeholder="例如:人工智能、中国历史...",
key='search_box'
)
# 当有查询输入时执行搜索
if query:
# 显示加载状态(提升用户体验)
with st.spinner('正在从百万文档中搜索...'):
# 执行搜索(k 控制返回结果数量)
results = searcher.search(query, k=5) # 可调整为 3-10 之间的数值
# 处理搜索结果
if results:
# 展示结果区域标题
st.subheader(f'为您找到 {len(results)} 条相关结果')
# 创建结果展示容器(便于后续样式调整)
results_container = st.container()
# 显示每个结果(添加序号和分割线)
for i, url in enumerate(results, 1):
with results_container:
st.markdown(f'‌**结果 {i}**‌') # 加粗显示序号
st.write(url) # 显示具体URL
st.divider() # 添加分割线
else:
# 无结果时的提示(使用警告样式)
st.warning("没有找到相关结果,请尝试其他关键词")
# 侧边栏附加信息(可选功能)
with st.sidebar:
st.header("使用提示")
st.markdown("""
- 支持自然语言查询(如:'孙悟空大闹天宫')
- 输入完整问题获取更准确结果
- 点解 URL 直接访问源文档
""")
# 添加系统状态显示
st.divider()
st.caption(f'索引规模:{len(searcher.urls)} 篇文档')
# 页面底部元信息(可选)
st.divider()
st.caption('基于语义相似度的搜索引擎 | 由 Faiss 和 RoBERTa 驱动')
















 3719
3719

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









