







1、文件操作
1.1读取文件
1.1.1使用 read()
read() 方法用于读取文件的所有内容并将其作为一个字符串返回。
# 使用 'read' 方法读取文件的所有内容
with open('example.txt', 'r') as file:
content = file.read()
print(content)
1.1.2使用 readline()
readline() 方法用于一次读取文件的一行。
# 使用 'readline' 方法逐行读取文件
with open('example.txt', 'r') as file:
line = file.readline()
while line:
print(line, end='')
line = file.readline()1.1.3使用 readlines()
readlines() 方法用于读取文件的所有行,并将它们作为一个字符串列表返回。
# 使用 'readlines' 方法读取文件的所有行
with open('example.txt', 'r') as file:
lines = file.readlines()
for line in lines:
print(line, end='')注意:在使用 print 函数输出每一行时,我们使用了 end='' 参数来防止 print 函数在每一行的末尾再添加一个换行符,因为从文件中读取的每一行已经包含了换行符。
1.1.4读取 CSV 文件
CSV (Comma-Separated Values) 是一种常用的表格数据存储格式。Python 提供了内置的 csv 模块来方便地读写 CSV 文件。
基本读取方法
import csv
with open('data.csv', 'r', newline='', encoding='utf-8') as csvfile:
reader = csv.reader(csvfile)
for row in reader:
print(row) # 每行是一个列表使用 DictReader (推荐)
with open('data.csv', 'r', newline='', encoding='utf-8') as csvfile:
reader = csv.DictReader(csvfile)
for row in reader: # 每行是一个有序字典
print(row['列名1'], row['列名2'])处理不同分隔符
# 读取以分号分隔的文件
with open('data.csv', 'r', newline='') as csvfile:
reader = csv.reader(csvfile, delimiter=';')
for row in reader:
print(row)示例: 从CSV读取数据并处理
import csv
total_age = 0
count = 0
with open('people.csv', 'r', newline='') as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
total_age += int(row['Age'])
count += 1
print(f"平均年龄: {total_age/count:.1f}")1.2写入文件
避免Windows上的空行问题
在Python中,当你在Windows系统上写入文本文件时,可能会遇到额外的空行问题。这是因为不同操作系统使用不同的行结束符:
-
Windows使用
\r\n(回车+换行) -
Unix/Linux使用
\n(换行) -
老版Mac使用
\r(回车)
问题表现
当你在Windows上使用默认方式写入文件时:
with open('file.txt', 'w') as f:
f.write('line1\n')
f.write('line2\n')在Windows上查看时可能会显示为:
line1
line2
(每行后面多了一个空行)
解决方案
使用 newline='' 参数:
with open('file.txt', 'w', newline='') as f:
f.write('line1\n')
f.write('line2\n')为什么这样有效?
-
当不指定
newline参数时,Python的文本模式会将所有出现的\n转换为平台默认的行结束符(在Windows上是\r\n) -
指定
newline=''会禁用这种转换,直接按原样写入 -
这样在Windows上也能得到与Unix/Linux相同的输出效果
最佳实践
-
在写入文本文件时,特别是跨平台应用,总是使用
newline='' -
这在处理CSV文件时尤为重要,因为
csv.writer也会受到行结束符影响
import csv
with open('data.csv', 'w', newline='') as f:
writer = csv.writer(f)
writer.writerow(['Name', 'Age'])
writer.writerow(['Alice', 25])1.2.1使用 write()
# 使用 'write' 方法写入文件
with open('example.txt', 'w') as file:
file.write("Hello, World!")
1.2.2使用 writelines()
# 使用 'writelines' 方法写入文件
lines = ["Hello, World", "Welcome to Python programming"]
with open('example.txt', 'w') as file:
file.writelines(line + '\n' for line in lines)
1.2.3写入 CSV 文件
基本写入方法
import csv
data = [
['Name', 'Age', 'City'],
['Alice', 25, 'New York'],
['Bob', 30, 'London']
]
with open('output.csv', 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.writer(csvfile)
writer.writerows(data)使用 DictWriter (推荐)
fieldnames = ['Name', 'Age', 'City']
data = [
{'Name': 'Alice', 'Age': 25, 'City': 'New York'},
{'Name': 'Bob', 'Age': 30, 'City': 'London'}
]
with open('output.csv', 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader() # 写入表头
writer.writerows(data)处理特殊字符和引号
with open('output.csv', 'w', newline='') as csvfile:
writer = csv.writer(csvfile, quoting=csv.QUOTE_NONNUMERIC)
writer.writerow(['Text with, comma', 123, 'Another "quote"'])CSV 常用参数说明
| 参数 | 说明 |
|---|---|
delimiter |
字段分隔符,默认为 ',' |
quotechar |
引用字符,默认为 '"' |
quoting |
引用规则: QUOTE_ALL, QUOTE_MINIMAL, QUOTE_NONNUMERIC, QUOTE_NONE |
skipinitialspace |
忽略分隔符后的空格 |
lineterminator |
行结束符,默认为 '\r\n' |
示例1: 将数据写入CSV
import csv
students = [
{'ID': 1, 'Name': '张三', 'Score': 85},
{'ID': 2, 'Name': '李四', 'Score': 92},
{'ID': 3, 'Name': '王五', 'Score': 78}
]
with open('grades.csv', 'w', newline='', encoding='utf-8-sig') as csvfile:
fieldnames = ['ID', 'Name', 'Score']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(students)示例2: 处理大型CSV文件
import csv
def process_large_csv(input_file, output_file):
with open(input_file, 'r', newline='', encoding='utf-8') as infile, \
open(output_file, 'w', newline='', encoding='utf-8') as outfile:
reader = csv.DictReader(infile)
writer = csv.DictWriter(outfile, fieldnames=reader.fieldnames)
writer.writeheader()
for row in reader:
# 在此处添加数据处理逻辑
if int(row['Age']) >= 18:
writer.writerow(row)
process_large_csv('input.csv', 'adults.csv')注意事项
-
总是使用
newline=''参数避免Windows上的空行问题 -
指定正确的编码(通常使用
utf-8或utf-8-sig) -
处理大型文件时考虑内存使用,逐行处理
-
对于复杂的数据清洗任务,可以考虑使用
pandas库
1.3open模式

1.4综合案例
日志文件读写
写一段代码,模拟生成accuracy逐步上升、loss逐步下降的训练日志,并将日志信息记录到training_log.txt中
# 写一段代码,模拟生成accuracy逐步上升、loss逐步下降的训练日志,并将日志信息记录到training_log.txt中
import random
# 设置epoch数量和初始的accuracy和loss值
epoch = 100
accuracy = 0.5
loss = 0.9
# 打开一个txt文件以记录每个epoch的结果
with open("training_log.txt", 'w') as f:
f.write("Epoch\tAccuracy\tLoss\n")
# 循环遍历每个epoch
for epoch_i in range(1, epoch + 1):
# 模拟accuracy逐步上升和loss逐步下降
accuracy += random.uniform(0, 0.005) # 随机增加accuracy
loss -= random.uniform(0, 0.005) # 随机减少loss
# 限制accuracy和loss的范围
accuracy = min(1, accuracy)
loss = max(0, loss)
# 将结果写入txt文件
f.write(f"{epoch_i}\t{accuracy:.3f}\t{loss:.3f}\n")
# 打印每个epoch的结果
print(f"Epoch:{epoch_i}, Accuracy:{accuracy}, Loss:{loss}")2、Numpy
import numpy as np2.1创建和生成 Numpy 数组
2.11从 Python 列表或元组创建
使用 np.array() 函数,我么可以将 Python 的列表(list)转换成 Numpy 数组。这是最直接的创建方式。
list_array = np.array([1, 2, 3])
print("从列表创建的数组:\n", list_array)
# 从列表创建二维数组
list_2d_array = np.array([[1, 2, 3], [4, 5, 6]])
print("从列表创建的二维数组: \n", list_2d_array)
# 指定数据类型
typed_array = np.array([1, 2, 3], dtype=np.float16)
print("指定数据类型的数值: \n", typed_array)![]()
# 从元组创建
tuple_array = np.array((1.1, 2.2))
print("从元组创建的数组: \n", tuple_array)![]()
# 从元组创建二维数组
tuple_2d_array = np.array([(1.1, 2.2, 3.3), (4.4, 5.5, 6.6)])
print("从元组创建的二维数组: \n", tuple_2d_array)
注意事项:
- 当列表或元组中的元素类型不一致时,Numpy 会尝试将它们转换成一个公共的类型,通常是更宽泛的类型(如整数会被转换为浮点数)
- 您可以通过指定
dtype参数来设置数组元素的数据类型
2.12使用 arange 生成数组
Numpy 的 arange 函数类似于 Python 的 range 函数,但它返回的是一个数组而不是列表。这个函数在需要创建数值范围时非常有用。
# 创建一个 0 到 11 的数组
arange_array = np.arange(12)
print("使用 arange 创建的数组: \n", arange_array)![]()
# 创建一个步长为 2 的数组
stepped_array = np.arange(100, 124, 2)
print("步长为 2 的数组: \n", stepped_array)![]()
2.13使用 linspace 和 logspace 生成数组
linsapce 和 logspace 函数生成的是线性间隔和对数间隔的数组,常用于数值分析和图形绘制。
# 使用 linspace 创建等间隔数值数组
linear_space = np.linspace(0, 9, 10)
print("使用 linspace 创建的数组: \n", linear_space)![]()
# 使用 logspace 创建对数间隔数值数组
logarithmic_space = np.logspace(0, 9, 10, base=np.e)
print("使用 logspace 创建的数组: \n", logarithmic_space)
注意事项:
linspace的第三个参数是数组中的元素数量,而不是步长。logspace的base参数默认为 10,可以生成不同基数的对数间隔数组。
2.14使用 ones 和 zeros 创建特殊数组
ones 和 zeros 函数可以快速创建元素全为 1 或 0 的数组。这些函数在初始化参数或重置数据时特别有用。
# 创建全 1 的数组
ones_array = np.ones((2, 3))
print("全 1 的数组: \n", ones_array)
# 创建全 0 的三维数组
zeros_array = np.zeros((2, 3, 4))
print("全 0 的三维数组: \n", zeros_array)
# 创建与另一个数组形状相同的全 0 数组
zeros_like_array = np.zeros_like(np.ones((2, 3, 3)))
print("与给定数组形状相同的全 0 数组: \n", zeros_like_array)
注意事项:
- 默认情况下,
ones和zeros创建的数组类型为浮点数。您可以通过dtype参数指定其他类型。
2.15使用 random 生成随机数数组
Numpy 的 random 模块包含了多种生成随机数的函数,非常适合生成测试数据或进行随机化操作。
# 创建一个 2x3 的随机数组,元素介于 0 到 1 之间
np.random.rand(2, 3)![]()
# 创建一个随机整数数组,元素值介于 0 到 10 之间
np.random.randint(0, 10, (2, 3))![]()
# 创建一个符合标准正态分布的数组
np.random.randn(2, 4)![]()
# 从 1.17 版本后推荐使用 Generator 的方法来生成随机数
# rng 是个 Generator,可用于生成各种分布
rng = np.random.default_rng(42) # 42 随机种子
rng![]()
# 连续均匀分布用法
rng.random((2, 3))![]()
# 可以指定上下界
rng.uniform(0, 1, (2, 3))![]()
# 指定大小和上界
rng.integers(10, size=2)![]()
# 指定上下界
rng.integers(0, 10, (2, 3))![]()
# 标准正态分布用法
rng.standard_normal((2, 4))![]()
# 高斯分布用法
rng.normal(0, 1, (3, 5))
2.16从文件读取数组
Numpy 还提供了读写磁盘文件的功能。你可以将数组保存到文件中,然后需要时再加载它们。
# 将数组保存到文件
np.save('./my_array', np.array([[1, 2, 3], [4, 5, 6]]))# 从文件加载数组
loaded_array = np.load('my_array.npy')
print("从文件加载的数组: \n", loaded_array)
注意事项:
- 使用
np.save保存数组时,文件扩展名.npy会自动添加。使用np.load加载数组时需要包含此扩展名。
2.2Numpy的基本操作
在本节中,我们将从数组的基本统计属性入手,进一步了解 Numpy 数组的特性。主要内容包括以下几个方面:
- 尺寸相关
- 最大值、最小值、中位数和分位数
- 平均值、求和和标准差等
这些都是描述性统计相关的指标,对于整体了解一个数组非常有帮助。其中,我们经常使用的是尺寸相关的 "shape" 属性,以及最大值、最小值、平均值和求和等。
在本节中,我们将使用一个随机生成的数组作为操作对象,并指定种子 (seed),以确保每次运行时的结果都是一样的。在训练模型时,通常需要指定种子 (seed),以便在相同的条件下进行调参。
首先,让我们创建一个随机数生成器 (generator):
# 创建一个随机数生成器
rng = np.random.default_rng(seed=2)然后,我们使用均匀分布生成一个 3 行 4 列的数组:
# 生成一个均匀分布的数组
arr = rng.uniform(0, 1, (3, 4))
arr
2.21尺寸相关
在本小节中,我们将介绍数组的维度、形状和数据量等尺寸相关的属性。其中,形状 (shape) 属性是我们经常使用的。
首先,让我们看看数组的维度:
# 维度,数组是二维的(两个维度)
arr.ndim![]()
# 形状,返回一个元组
arr.shape![]()
# 数据量
arr.size![]()
2.22最值和分位数
在本小节中,我们将介绍数组的最大值、最小值、中位数和其他分位数等属性。其中,最大值和最小值是我们经常使用的。
首先,让我们查看数组的最大值:
arr.max()![]()
我们还可以按指定的维度查找最大值,比如按列查找:
arr.max(axis=0)![]()
类似地,我们也可以按行查找最大值:
arr.max(axis=1)![]()
在进行计算时,有时我们需要保持原有的维度。例如,如果我们按行查找最小值,并保持行的维度不变:
arr.min(axis=1, keepdims=True)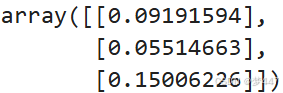
同样地,我们也可以按列查找最小值并保持维度不变:
arr.min(axis=0, keepdims=True)![]()
如果我们不保持维度不变,可以使用 keepdims=False:
arr.min(axis=0, keepdims=False)![]()
使用 numpy.percentile 求分位数
np.percentile(arr, 50)![]()
可以设置 axis 参数来计算不同维度的分位数
np.percentile(arr, 25, axis=0)![]()
np.percentile(arr, 50, axis=1, keepdims=True)
插值方法选择 method 参数决定分位数计算方式,常用选项:
linear:线性插值(默认)lower:取较小值higher:取较大值nearest:取最近值
2.23平均值、求和和标准差
在本小节中,我们将介绍数组的平均值、累计求和、方差和标准差等统计指标。其中,平均值是我们经常使用的。
首先,让我们查看数组的平均值:
np.average(arr) # np.mean(arr)![]()
我们还可以按指定的维度计算平均值,例如按列计算:
np.average(arr, axis=0)![]()
接下来,让我们计算数组的求和:
np.sum(arr, axis=1)![]()
如果我们想保持维度不变,可以使用 keepdims=True
np.sum(arr, axis=1, keepdims=True)
我们还可以按列进行累计求和:
np.cumsum(arr, axis=0)
同样地,我们也可以按行进行累计求和:
np.cumsum(arr, axis=1)
最后,让我们计算数组的标准差:
np.std(arr)![]()
2.3Numpy广播机制
Numpy 的广播机制允许不同形状的数组在算术运算中进行兼容。当进行算术运算如加、减、乘、除等操作时,Numpy 试图让这些数组的形状匹配,如果可能得话,会“广播”较小数组的形状以匹配较大数组的形状。这让我们可以在不同形状的数组之间进行数学运算,而无需手动调整它们的大小。
直观认识
想象一下你有一个形状为 (3,) 的一维数组,也就是有 3 个元素的向量,和一个单独的数字(可以认为是形状为 (1,) 的数组)。如果你想要把这个单独的数字加到向量的每一个元素上,按照数学上的直觉,你可能需要写一个循环,逐个元素地进行加法。但是在 Numpy 中,你不需要写循环,你只需要简单地执行加法运算,Numpy 会自动把那个单独的数字“扩展”或者说“广播”到向量的每一个元素上,然后逐个相加。
广播的规则
Numpy 在进行广播时遵循以下规则:
- 如果所有输入数组的维数不同,将形状较小的数组的形状在前面补 1,直到所有的数组维数都相同。
- 在任何一个维数上,如果一个数组的大小是 1,而另一个数组的大小大于 1,则第一个数组的形状会沿着这个维度扩展以匹配另一个数组的形状。
- 如果在任何维度上,两个数组的大小不一致且其中一个数组的大小不是 1,则无法进行广播,Numpy 将会抛出错误。
接下来,让我们通过代码示例来具体看看广播是如何工作的。
首先,我们创建一个形状为 (3, 4) 的随机整数数组 a。
# 创建一个随机数生成器
rng = np.random.default_rng(seed=2)# 创建一个 3x4 的随机整数数组
a = rng.integers(1, 100, (3, 4))
a
这将输出一个形状为 (3, 4) 的数组,即有 3 行 4 列。
现在,我们尝试将数组 a 与一个形状为 (4,) 的一维数组进行相加。这里,一维数组的形状将会在前面补 1,变成 (1, 4)。然后,这个一维数组沿着第一个维度(行)广播,以匹配 a 的形状 (3, 4)。
# 将 a 数组与一个一维数组 [1, 2, 3, 4] 相加
# 一维数组的形状会被广播以匹配 a 的形状
b = np.array([1, 2, 3, 4])
a + b
结果是,一维数组 [1, 2, 3, 4] 被广播到每一行,与 a 的每一行相加。
在另一个例子中,我们将 a 与一个形状为 (3, 1) 的二维数组进行相加。这里,二维数组沿着第二个维度(列)广播,以匹配 a 的形状。
# 将 a 数组与一个形状为 (3, 1) 的二维数组相加
# 二维数组的形状会被广播以匹配 a 的形状
a + [[1], [2], [3]]
结果是,二维数组 [[1], [2], [3]] 被广播到每一列,与 a 的每一列相加。
通过这些示例,我们可以看到 Numpy 如何灵活地处理不同形状的数组,并在算术运算中自动应用广播机制。这大大简化了数组操作,使得代码更加简洁易读。
2.4索引与切片
在这一节中,我们将深入了解 numpy 数组的切片和索引功能。这是正个教程中最关键的部分,因为他揭示了 Numpy(以及 Python 语言)的强大功能。这种优雅的操作方式可能不是独一无二的,但在历史上绝对是开创性的。
本节内容将涵盖以下几个主题:
- 切片
- 索引
- 拼接、重复、分拆
切片和索引是这些主题中的核心,因为它们是基础且频繁使用的。强烈建议您熟练掌握这些技能。其他主题相对简单,只需记住一个 API 即可。
2.41切片和索引
重点提示: 切片和索引是在现有数组上操作以获取所需【部分】元素的方法。其核心是根据 start:stop:step 模式按维度操作数组。 理解这部分的关键在于将处理过程按维度分解,并且对于不需要处理的维度统一使用 : 或 ... 表示。分析操作时,首先需要注意逗号【,】的位置。处理的维度与 arange、linspace 等函数的使用方法相同。
注意:索引支持负数,即可以从数组的末尾开始计数。
以下是一些基本的索引和切片操作示例:
rng = np.random.default_rng(seed=42) # 创建一个随机数生成器实例
arr = rng.integers(0, 20, (5, 4)) # 创建一个 5x4 的数组,元素是 0 到 20 的整数
arr
接下来,让我们看看如何使用切片和索引来访问和操作数组中的数据
# 获取第 0 行的所有元素
arr[0]![]()
arr[0,:]![]()
arr[0,...]![]()
# 获取第 1 到第 2 行的所有元素(不包括第 3 行)
arr[1: 3]![]()
# 获取第 0 行第 1 列元素
arr[0, 1]![]()
# 获取第 1 行和第 3 行所有元素(离散索引)
arr[(1, 3), :]![]()
# 获取第 1 到第 2 行的第 1 列元素
arr[1:3, 1]![]()
# 获取第 1 行和第 3 行的第 0 列元素(离散索引)
arr[(1, 3), 0]![]()
# 获取第 3 行到最后一行的所有元素
arr[3:]![]()
# 获取从开始到第 3 行的第 1 到第 2 列的元素(不包含第 3 行)
arr[:3, 1:3]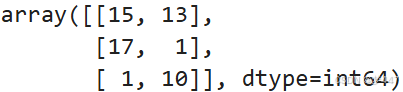
# 使用步长来获取元素,这里我么从第 1 行到第 4 行,每隔 2 行取一次,即第 1 行和第 3 行
arr[1:4:2]![]()
# 我们也可以在列上使用步长,这里我们取第 1 行和第 3 行的第 0 列和第 2 列
arr[1:4:2, :3:2]![]()
# 使用 ... 来代表多个冒号,这里我们获取第一列的所有元素
arr[..., 1]![]()
# 直接使用冒号来获取第一列的所有元素,这是常见的用法
arr[:, 1]![]()
2.42拼接
在数据处理中,我们经常需要将多个数组合并成一个更大的数组。这可以通过拼接或堆叠完成。Numpy 提供了多种方法来实现这一点,我们将重点介绍 np.concatenate 和 np.stack,这两个函数提供了合并数组的基本功能。
np.concatenate 是 Numpy 中最常见的数组拼接函数之一。它可以沿着指定的轴连接数组序列。
# 创建两个形状相同的数组
arr1 = rng.random((2, 3))
arr2 = rng.random((2, 3))
# 默认情况下,np.concatenate 沿着第一个轴(axis=0,即行)进行拼接
concatenated_arr = np.concatenate((arr1, arr2))
concatenated_arr.shape![]()
# 可以指定 axis 参数来沿着不同的轴拼接数组,这里是沿着列(axis=1)
concatenated_arr_axis1 = np.concatenate((arr1, arr2), axis=1)
concatenated_arr_axis1.shape![]()
这将输出一个新数组,其中第二个数字的列被添加到第一个数组的右侧。
np.stack np.stack是另一个用于堆叠数组的函数,不同于 np.concatenate,np.stack 会创建一个新的轴。
# 使用 np.stack 来堆叠两个数组,它会在结果中添加一个新的轴
stacked_arr = np.stack((arr1, arr2))
print(stacked_arr)
print("Shape of stacked array:", stacked_arr.shape)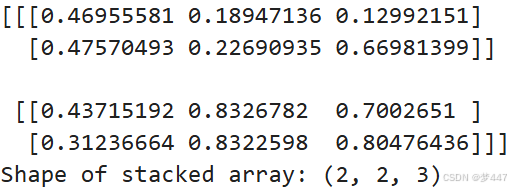
# 可以指定 axis 参数来沿着不同的轴堆叠数组,这里我们沿着最内侧的轴(axis=2)进行堆叠
stacked_arr_axis2 = np.stack((arr1, arr2), axis=2)
print(stacked_arr_axis2)
print("Shape of stacked array along axis 2:", stacked_arr_axis2.shape)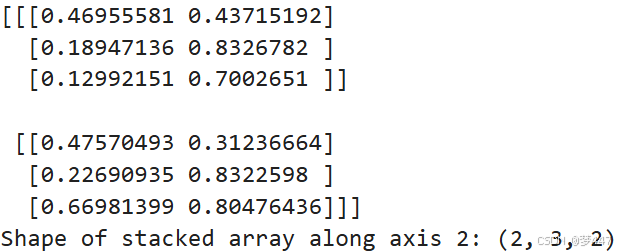
2.43重复
有时我们需要将数组中的元素沿着指定的轴重复某些次数,np.repeat 函数正是为此设计的。
# 创建一个 3x4 的随机整数数组
arr = rng.integers(0, 10, (3, 4))
arr
# 沿着 axis=0 重复每一行两次
repeated_arr_axis0 = np.repeat(arr, 2, axis=0)
repeated_arr_axis0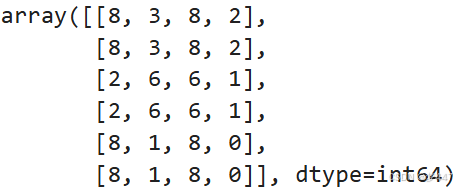
# 沿着 axis=1 重复每一列三次
repeated_arr_axis1 = np.repeat(arr, 3, axis=1)
repeated_arr_axis1
2.44分拆
与拼接相反,分拆是将一个大数组分割成多个小数组的过程。np.split 提供了一个通用的分割方法。
# 创建一个 6x4 的随机整数数组
arr = rng.integers(1, 100, (6, 4))
arr
# 默认情况下,np.split 沿着第一个轴(axis=0)分割数组,这里我们将其分割成 3 个相同大小的小数组
split_arr = np.split(arr, 3)
split_arr
# 我们也可以沿着列(axis=1)分割数组,这里我们将其分割成 2 个相同大小的小数组
split_arr_axis1 = np.split(arr, 2, axis=1)
split_arr_axis1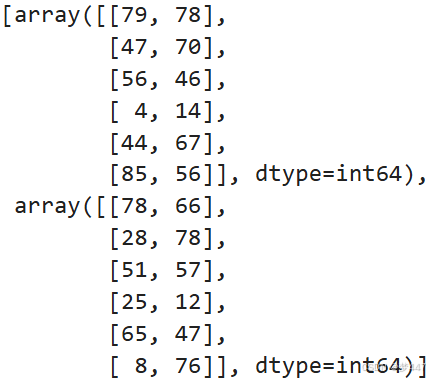
2.45条件筛选
在处理数组时,我们经常根据条件选择或修改元素。np.where 是一个非常有用的函数,它返回满足条件的元素的索引。
# 创建一个 6x4 的随机整数数组
arr = rng.integers(1, 100, (6, 4))
arr
# 使用条件筛选来创建一个布尔数组
condition = arr > 50
condition
# 使用 np.where 来找到满足条件的元素的索引
indices = np.where(arr > 50)
indices # 返回 行索引,列索引![]()
# 使用 np.where 进行条件筛选,将所有小于等于 50 的元素替换为 -1
new_arr = np.where(arr > 50, arr, -1)
new_arr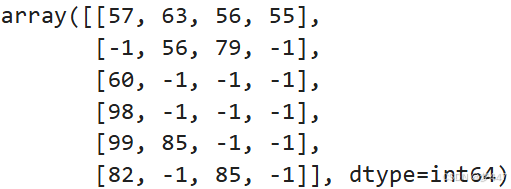
2.46提取
有时我们需要从数组中提取满足特定条件的元素
# 使用 np.extract 来提取大于 50 的元素
extracted_elements = np.extract(arr > 50, arr)
extracted_elements![]()
# 使用 np.extract 来获取数组中所有唯一的元素
unique_elements = np.unique(arr)
unique_elements![]()
2.47最值Index
在数据分析中,我们经常需要找到最大或最小元素的位置。np.argmax 和 np.argmin 可以帮助我们找到这些元素的索引。
arr
# 找到正个数组中最大元素的索引
index_of_max = np.argmax(arr)
index_of_max![]()
# 沿着列找到每列最大元素的索引
indices_of_max_in_columns = np.argmax(arr, axis=0)
indices_of_max_in_columns![]()
# 沿着行找到每行最小元素的索引
indices_of_min_in_rows = np.argmin(arr, axis=1)
print(indices_of_min_in_rows)![]()
2.5形状和转换
在 numpy 中,数组 (array) 通常是多维的。我们通常将一位数组称为向量,二维数组称为矩阵,而超过二维的数组称为张量。由于数组可能具有多个维度,因此改变其形状和转换是非常基础且常见的操作。
在本节中,我们将探讨以下三个方面:
- 改变形状(Reshaping)
- 反序(Reversing)
- 转置(Transposing)
其中,改变形状和转置是非常常见的操作,值得深入学习和掌握。
2.51改变形状
在本小节中,我们将介绍一些非常高频的 API,特别是用于扩展一维度的 expand_dims 和去除一维度的 squeeze 函数。这些函数在神经网络的加购中尤其常见。
需要特别注意的是,无论是扩展还是压缩维度,改变的维度大小必须是 1。例如,在使用 squeeze 函数时,如果指定了具体的维度,那么该维度的大小必须是 1。
# 创建一个随机整数数组
rng = np.random.default_rng(seed=42) # 创建一个随机数生成器,种子为 42
arr = rng.integers(1, 100, (3, 4)) # 生成一个 3x4 的整数数组,数组范围是 1 到 100
arr
np.expand_dims 函数可以在指定位置增加一个维度
# 在第二个维度位置增加一个维度
arr_expanded = np.expand_dims(arr, axis=1)
arr_expanded.shape![]()
arr_expanded
输出的形状是 (3, 1, 4),在原来的基础上增加了一个维度
# 在多个位置增加维度
expanded = np.expand_dims(arr, axis=(1, 3, 4))
expanded.shape![]()
注意:
- 扩充维度时不能跳过已有的维度
- 下面的代码会出错,因为没有维度 8 可以扩展
expanded = np.expand_dims(arr, axis=(1, 3, 8))np.squeeze 函数用于移除数组形状中大小为 1 的维度。
# 移除第二个维度,因为它的大小为 1
arr_squeezed = np.squeeze(expanded, axis=1)
arr_squeezed.shape![]()
输出的形状是 (3, 4, 1, 1),移除了一个大小为 1 的维度。
# 移除所有大小为 1 的维度
squeezed = np.squeeze(expanded)
squeezed.shape![]()
输出的形状是 (3, 4),移除了所有大小为 1 的维度。
np.reshape/arr.reshape 函数可以改变数组的形状而不改变其数据。
# 将数组重塑为另一个形状
arr_reshaped = arr.reshape(2, 2, 3)
arr_reshaped
输出的数组形状是 (2, 2, 3),即重塑为一个三维数组。
# 使用 -1 可以自动计算维度的大小
arr_reshaped = arr.reshape((4, -1))
arr_reshaped
输出的数组形状是 (4, 3),-1 表示自动计算该维度的大小。
注意:
- 如果尝试将数组重塑为元素数量不匹配的形状,将会出错
- 下面的代码将会引发错误,因为原数组有 12 个元素,而新形状只能容纳 9 个元素
arr_reshaped = arr.reshape(3, 3)# 使用 resize 可以改变数组本身的形状
# 注意:resize 会直接修改原数组,而不是返回一个新数组
# 与 reshape 不同,resize 允许新形状的总元素数量与原数组不同
arr.resize((4, 3), refcheck=False)
arr
输出的数组形状是 (4, 3), resize 还可以填充或截断原数组以匹配新的形状。
# 使用 np.resize 可以创建一个新数组,它的行为略有不同
arr_resized = np.resize(arr, (5, 3))
arr_resized
输出的数组形状是 (5, 3)。如果新形状的总元素数量多于原数组,则 np.resize 会复制原数组中的元素以填充新数组。
# 如果新形状的总元素数量少于原数组,则 np.resize 会截断原数组中的元素
arr_resized = np.resize(arr, (2, 2))
arr_resized![]()
输出的数组形状是 (2, 2),多余的元素被截断。
2.52反序
反序是将数组中的元素顺序颠倒。在 numpy 中,我们可以使用切片的方式来实现反序。
如果给您一个字符串或数组让您反序,您可能会想到使用 reversed 函数,或者编写一个自定义函数,或者利用 Python 列表的切片功能。在 numpy 中,我们可以使用类似的切片方法来反序数组。
# 反序字符串
s = "uevol"
s_reversed = s[::-1]
s_reversed![]()
# 反序列表
lst = [1, &# 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4032
4032

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









