






1.labelme标注的json格式的文件先转为yolo格式
import json
import numpy as np
import os
import cv2
def json2yolo(path, cls_dict, types="bbox"):
with open(path, 'r', encoding='utf-8') as fp:
data = json.load(fp)
h = data["imageHeight"]
w = data["imageWidth"]
shapes = data["shapes"]
all_lines = ""
for shape in shapes:
if True:
points = np.array(shape["points"])
if types == "bbox":
x, y, wi, hi = cv2.boundingRect(points.reshape((-1, 1, 2)).astype(np.float32))
cx, cy = x + wi / 2, y + hi / 2
cx, cy, wi, hi = cx / w, cy / h, wi / w, hi / h
msg = "%.4f %.4f %.4f %.4f" % (cx, cy, wi, hi)
else:
points[:, 0] = points[:, 0] / w
points[:, 1] = points[:, 1] / h
# 把np数组转换为yolo格式的str
points = points.reshape(-1)
points = list(points)
points = ['%.4f' % x for x in points]
msg = " ".join(points)
l = shape['label'].lower()
line = str(cls_dict[l]) + " " + msg + "\n"
all_lines += line
print(all_lines)
filename = path.replace('json', 'txt')
fh = open(filename, 'w', encoding='utf-8')
fh.write(all_lines)
fh.close()
path = "G:\Desttop\dataset\labelme/" #路径修改为自己的路径
path_list = os.listdir(path)
cls_dict = {'hand': 0, 'pen': 1} #需要更改为自己的标签
path_list2 = [x for x in path_list if ".json" in x]
for p in path_list2:
json2yolo(path + "/" + p, cls_dict)2.划分数据集(方便理解,没有更换路径,最终需要路径更换为自己的)
import os, shutil, random
random.seed(0)
import numpy as np
from sklearn.model_selection import train_test_split
val_size = 0.2
test_size = 0.0
postfix = 'jpg'
imgpath = 'G:\Desttop\dataset\images'
txtpath = 'G:\Desttop\dataset/txt'
os.makedirs('G:\Desttop\dataset\spilt/images/train', exist_ok=True)
os.makedirs('G:\Desttop\dataset\spilt/images/val', exist_ok=True)
os.makedirs('G:\Desttop\dataset\spilt/images/test', exist_ok=True)
os.makedirs('G:\Desttop\dataset\spilt/labels/train', exist_ok=True)
os.makedirs('G:\Desttop\dataset\spilt/labels/val', exist_ok=True)
os.makedirs('G:\Desttop\dataset\spilt/labels/test', exist_ok=True)
listdir = np.array([i for i in os.listdir(txtpath) if 'txt' in i])
random.shuffle(listdir)
train, val, test = listdir[:int(len(listdir) * (1 - val_size - test_size))], listdir[int(len(listdir) * (1 - val_size - test_size)):int(len(listdir) * (1 - test_size))], listdir[int(len(listdir) * (1 - test_size)):]
print(f'train set size:{len(train)} val set size:{len(val)} test set size:{len(test)}')
for i in train:
shutil.copy('{}/{}.{}'.format(imgpath, i[:-4], postfix), 'G:\Desttop\dataset\spilt/images/train/{}.{}'.format(i[:-4], postfix))
shutil.copy('{}/{}'.format(txtpath, i), 'G:\Desttop\dataset\spilt/labels/train/{}'.format(i))
for i in val:
shutil.copy('{}/{}.{}'.format(imgpath, i[:-4], postfix), 'G:\Desttop\dataset\spilt/images/val/{}.{}'.format(i[:-4], postfix))
shutil.copy('{}/{}'.format(txtpath, i), 'G:\Desttop\dataset\spilt/labels/val/{}'.format(i))
for i in test:
shutil.copy('{}/{}.{}'.format(imgpath, i[:-4], postfix), 'G:\Desttop\dataset\spilt/images/test/{}.{}'.format(i[:-4], postfix))
shutil.copy('{}/{}'.format(txtpath, i), 'G:\Desttop\dataset\spilt/labels/test/{}'.format(i))3.转为coco格式
我的目录是这样的:
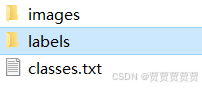
images和labels下一级目录是这样的:
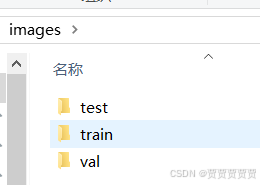
classes.txt是这样的:建议将最后一行空行删除,光标到最后一个位置。

import json
import shutil
from pathlib import Path
import cv2
from tqdm import tqdm
def get_datasets_path(root_dir):
dir_list = []
for t in type_list:
sublayer = root_dir.joinpath(
"images", t), root_dir.joinpath("labels", t)
if sublayer[0].exists():
dir_list.append(sublayer)
assert sublayer[1].exists(), f"the path '{sublayer[1]}' is not exists"
if len(dir_list) == 0:
raise FileNotFoundError("the path is empty,please check you path")
with root_dir.joinpath("classes.txt").open() as f:
classes = f.read().strip().split()
return dir_list, classes
def move_images(origin_images_dir, filename, path):
dst = root_dir.joinpath("yolo2coco", f"{path[0].name}2017")
if not dst.exists():
dst.mkdir(parents=True)
destination = dst.joinpath(filename) # 获取目标文件的完整路径
shutil.move(origin_images_dir, destination) # 移动文件到目标位置
# 参考 https://github.com/Weifeng-Chen/dl_scripts/blob/main/detection/yolo2coco.py
def yolo2coco(dir_list, classes):
for path in dir_list:
dataset = {"categories": [], "annotations": [], "images": []}
for i, cls in enumerate(classes, 0):
dataset["categories"].append(
{"id": i, "name": cls, "supercategory": "mark"})
indexes = list(path[0].iterdir())
id_count = 0
bar = tqdm(indexes, unit=" images ")
for k, index in enumerate(bar):
info = f" {k + 1} / {len(indexes)}"
bar.desc = info
filename = index.name
label_filename = Path(index.name).with_suffix(".txt")
origin_labels_dir = path[1].joinpath(label_filename)
origin_images_dir = path[0].joinpath(index)
img = cv2.imread(origin_images_dir.as_posix())
image_height, image_width, _ = img.shape
dataset["images"].append({"file_name": filename,
"id": k,
"width": image_width,
"height": image_height})
# 移动图片到coco文件夹
move_images(origin_images_dir, filename, path)
if not origin_labels_dir.exists():
print(f"{origin_images_dir} has not label")
continue
with origin_labels_dir.open("r") as f:
labels = f.readlines()
for label in labels:
label = label.strip().split()
x = float(label[1])
y = float(label[2])
w = float(label[3])
h = float(label[4])
# convert x,y,w,h to x1,y1,x2,y2
# 左上角和宽高
x1 = (x - w / 2) * image_width
y1 = (y - h / 2) * image_height
x2 = (x + w / 2) * image_width
y2 = (y + h / 2) * image_height
cls_id = int(label[0])
width = max(0, x2 - x1)
height = max(0, y2 - y1)
dataset["annotations"].append({
"area": width * height,
"bbox": [x1, y1, width, height],
"category_id": cls_id,
"id": id_count,
"image_id": k,
"iscrowd": 0,
"segmentation": [[x1, y1, x2, y1, x2, y2, x1, y2]]})
id_count += 1
annotations = root_dir.joinpath("yolo2coco", "annotations")
if not annotations.exists():
annotations.mkdir()
save_file = annotations.joinpath(f"instances_{path[0].name}2017.json")
with save_file.open("w") as f:
json.dump(dataset, f)
print("Save annotation to {} successfully!".format(save_file))
print("Move images of {}_dataset successfully!".format(path[0].name))
if __name__ == "__main__":
# yolo格式数据根目录
root_dir = Path("G:\Desttop\dataset\spilt")
type_list = ["train", "val", "test"]
dir_list, classes = get_datasets_path(root_dir)
yolo2coco(dir_list, classes)

















 6267
6267

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









