






E-R 模型
E-R
模型常用于
OLTP
数据库建模,应用到构建数仓时(
数据仓库之父
Bill Inmon
推崇使用
E-R
模型构建数据仓库
)更
偏重数据整合,站在企业整体考虑,将各个系统的数据按相似性一致性、合并处理,为数据分析、决策服务,但并不便于
直接用来支持分析。
缺陷
:
需要全面梳理企业所有的业务和数据流
,
周期长
,
人员要求高
。
E-R
模型分为实体、属性、关系三个核心部分。实体是长方形体现,而属性则是椭圆形,关系为菱形。
E-R
模型的实体(
Entity
)即数据模型中的数据对象,例如人、学生、音乐都可以作为一个数据对象,用长方体来表
示,每个实体都有自己的实体成员(
Entity Member
)或者说实体对象(
Entity Instance
),例如学生实体里包括张三、李
四等,实体成员(
Entity Member
)
/
实体实例(
Entity Instance
) 不需要出现在
E-R
图中。
E-R
模型的属性(
Attribute
)即数据对象所具有的属性,例如学生具有姓名、学号、年级等属性,用椭圆形表示,属
性分为唯一属性(
Unique Attribute
)和非唯一属性,唯一属性指的是唯一可用来标识该实体实例或者成员的属性,用下划
线表示,一般来讲实体都至少有一个唯一属性。
E-R
模型的关系(
Relationship
)用来表现数据对象与数据对象之间的联系,例如学生的实体和成绩的实体之间有一定
的联系,每个学生都有自己的成绩,这就是一种关系,关系用菱形来表示。
E-R
模型中关联关系有三种:
一对一(
1:1
):
1
对
1
关系是指对于实体集
A
与实体集
B
,
A
中的每一个实体至多与
B
中一个实体有关系;反之,在实
体集
B
中的每个实体至多与实体集
A
中一个实体有关系。
一对多(
1:N
):
1
对多关系是指实体集
A
与实体集
B
中至少有
N(N>0)
个实体有关系;并且实体集
B
中每一个实体至多
与实体集
A
中一个实体有关系。
多对多(
M:N
):多对多关系是指实体集
A
中的每一个实体与实体集
B
中至少有
M(M>0)
个实体有关系,并且实体集
B
中的每一个实体与实体集
A
中的至少
N(N>0)
个实体有关系。
设计
E-R
实体关系模型图,步骤如下:
抽象出实体;
找出实体之间的关系;
找出实体的属性;
画出
E-R
关系图。
最后,转化为传统数据库表。并且,
E-R
模型还可以完全使用图数据库代替。
维度建模
Ralph Kimball
推崇数据集市的集合为数据仓库
,同时也
提出了针对数据集市的维度建模
,
将数据仓库中的表划分为
事实表
、
维度表两种类型
。在实际操作中,一般会使用
ODS
(
Operational Data Store
,运营数据存储)层、
DW
(
Data
Warehouse
,数据仓库)层、
ADS
(
Application Data Service
,应用数据服务)层三级结构。
维度建模源自数据集市(
Data Mark
),数据集市可以理解为是一种
“
小型数据仓库
”
,主要面向
OLAP
场景。维度模型
是数据仓库领域大师
Ralph Kimall
所倡导的,他的《数据仓库工具箱》是数据仓库工程领域最流行的数仓建模经典。
维度建模以分析决策的需求出发构建模型,构建的数据模型为分析需求服务,因此它重点解决用户如何更快速完成分
析需求,同时还有较好的大规模复杂查询的响应性能。维度建模是专门应用于分析型数据库、数据仓库、数据集市建模的
方法。
什么是维度:
维度是维度建模的基础和灵魂。在维度建模中,将度量称为
“
事实
”
,将环境描述为
“
维度
”
,维度是用于分析事实所需
要的多样环境。例如,在分析交易过程时,可以通过买家、卖家、商品和时间等维度描述交易发生的环境。
如何获取维度或维度属性?如上面所提到的,一方面,可以在报表中获取;另一方面,可以在和业务人员的交谈中发
现维度或维度属性。因为它们经常出现在查询或报表请求中的
“
按照
”(by)
语句内。例如,用户要
“
按照
”
月份和产品来查看销
售情况,那么用来描述其业务的自然方法应该作为维度或维度属性包括在维度模型中
什么是维度表:
维度表是用户分析数据的窗口,比如时间、地区、用户等。包含表示维度信息列的表,被称为维度表,这些列被称为
维度属性。
维度属性是查询约束条件
、
分组和报表标签生成的基本来源
,
是数据易用性的关键
。
例如,在查询请求中,获取某类目的商品、正常状态的商品等,是通过约束商品类目属性和商品状态属性来实现的;
统计淘宝不同商品类目的每日成交金额,是通过商品维度的类目属性进行分组的;
我们在报表中看到的类目、
BC
类型
(B
指天猫,
C
指集市
)
等,都是维度属性。
所以
维度的作用一般是查询约束
、
分类汇总以及排序
等。
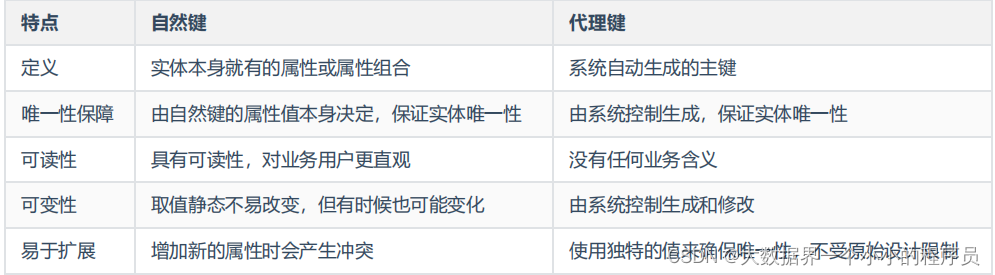
维度使用主键标识其唯一性,主键也是确保与之相连的任何事实表之间存在引用完整性的基础。主键有两种:代理键
和自然键,它们都是用于标识某维度的具体值。但代理键是不具有业务含义的键,一般用于处理缓慢变化维;自然键是具
有业务含义的键。
自然键
:自然键是在数据实体中唯一且非重复的一个属性或属性组合,例如一个人的身份证号码。自然键使用现实世
界中可以唯一标识实体的属性值作为主键。由于自然键是实体本身的属性,因此它可以提供丰富的上下文信息,可以
用于外键关联和查询等操作,但可能存在一些缺点,比如占用空间较大,有时不太适用于分布式系统等。
代理键
:代理键是一个人工创建的主键,它不反映现实世界中的任何实体属性,而是在数据建模过程中添加的特殊属
性,通常是自增的整数标识符。代理键是一种虚拟的、无关信息的主键,但由于其固定的格式,代理键很容易添加和
修改,因此它可以提供更好的性能和可伸缩性。代理键的一个缺点是缺乏上下文信息,可能需要进行额外的数据库
JOIN
操作才能访问到实体的其他属性。
维度设计方法:
维度的设计过程就是确定维度属性的过程
,如何生成维度属性,以及所生成的维度属性的优劣,决定了维度使用的方
便性,成为数据仓库易用性的关键。正如
Kimball
所说的,
数据仓库的能力直接与维度属性的质量和深度成正比
。
下面以淘宝的商品维度为例对维度设计方法进行详细说明。
第一步
:
选择维度或新建维度
。作为维度建模的核心,在企业级数据仓库中必须保证维度的唯一性。以淘宝商品维度
为例,有且只允许有一个维度定义。
第二步
:
确定主维表
。此处的主维表一般是
ODS
表,直接与业务系统同步。以淘宝商品维度为例,
s_auction_auctions
是与前台商品中心系统同步的商品表,此表即是主维表。
第三步
:
确定相关维表
。数据仓库是业务源系统的数据整合,不同业务系统或者同一业务系统中的表之间存在关联
性。根据对业务的梳理,确定哪些表和主维表存在关联关系,并选择其中的某些表用于生成维度属性。以淘宝商品维度为
例,根据对业务逻辑的梳理,可以得到商品与类目、
SPU
、卖家、店铺等维度存在关联关系。
第四步
:
确定维度属性
。本步骤主要包括两个阶段,其中第一个阶段是从主维表中选择维度属性或生成新的维度属
性;第二个阶段是从相关维表中选择维度属性或生成新的维度属性。以淘宝商品维度为例,从主维表
(
s_auction_auctions
)和类目、
SPU
、卖家、店铺等相关维表中选择维度属性或生成新的维度属性。
维度设计原则 :
原则一
:
尽可能生成丰富的维度属性
。比如淘宝商品维度有近百个维度属性,为下游的数据统计、分析、
探查提供了良好的基础。
原则二
:
尽可能多地给出包括一些富有意义的文字性描述
。属性不应该是编码,而应该是真正的文字。在阿里巴巴维
度建模中,一般是编码和文字同时存在,比如商品维度中的商品
ID
和商品标题、类目
ID
和类目名称等。
ID
一般用于不同
表之间的关联,而名称一般用于报表标签。
原则三
:
区分数值型属性和事实
。数值型字段是作为事实还是维度属性,可以参考字段的一般用途。如果通常
用于查
询约束条件或分组统计
,则是
作为维度属性
;如果通常
用于参与度量的计算
,则是
作为事实
。所以
需要同时参考字段的
具体用途
。
比如
商品价格
,
可以用于查询约束条件或统计价格区间的商品数量
,
此时是作为维度属性使用的
;
也可以用于统计
某类目下商品的平均价格
,
此时是作为事实使用的
。再比如
驾校考试成绩
,一般只有通过
(
≥
90)
或失败
(<90)
两种,
可以用
于统计通过和失败的人数
,
此时是作为维度属性使用的
;
也可以用于统计某年龄段下不同月份的平均通过率
,
此时是作
为事实使用的
。
原则四
:
尽量沉淀出通用的维度属性
。有些维度属性获取需要进行比较复杂的逻辑处理,有些需要通过多表关联得
到,或者通过单表的不同字段混合处理得到,或者通过对单表的某个字段进行解析得到。此时,需要将尽可能多的通用的
维度属性进行沉淀。一方面,
可以提高下游使用的方便性
,
减少复杂度
;另一方面,
可以避免下游使用解析时由于各自逻
辑不同而导致口径不一致
。
例如,淘宝商品的
property
字段,使用
key:value
方式存储多个商品属性。商品品牌就存储在此字段中,而商品品牌
是重要的分组统计和查询约束的条件,所以需要将品牌解析出来,作为品牌属性存在。例如,商品是否在线,即在淘宝网
站是否可以查看到此商品,是重要的查询约束的条件,但是无法直接获取,需要进行加工,加工逻辑是:商品状态为
0
和
1
且商品上架时间小于或等于当前时间,则是在线商品;否则是非在线商品。所以需要封装商品是否在线的逻辑作为一个
单独的属性字段。
原则五
:
退化维度
(
DegenerateDimension
)。维度属性也可以存储到事实表中,这种存储到事实表中的维度列被
称为
“
退化维度
”
。与其他存储在维表中的维度一样,退化维度也可以用来进行事实表的过滤查询、实现聚合操作等。
原则六
:
缓慢变化维
(
Slowly Changing Dimensions
)。数据仓库的重要特点之一是反映历史变化,所以如何处理维
度的变化是维度设计的重要工作之一。缓慢变化维的提出是因为在现实世界中,维度的属性并不是静态的,它会随着时间
的流逝发生缓慢的变化,这种随时间发生变化的维度我们一般称之为缓慢变化维(
SCD
)。与数据增长较为快速的事实表
相比,维度变化相对缓慢。
缓慢变化维一般使用代理健作为维度表的主健
。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











