




先看图:

Driver:在Hive中,Driver是一个关键的组件,负责协调和管理Hive查询的执行过程
大致可以分为四步:解析->编译->优化->执行
大致流程如下:
解析:将HQL语句解析为抽象语法树
编译:将抽象语法树编译成查询块,将查询块转换为逻辑查询计划
优化:重写逻辑执行计划,优化逻辑执行计划(RBO 基于规则优化),将逻辑计划转换为物理执行计划
执行:选择最佳的join策略,优化物理执行计划(CBO 基于代价优化)
Hive的工作原理:
先看图: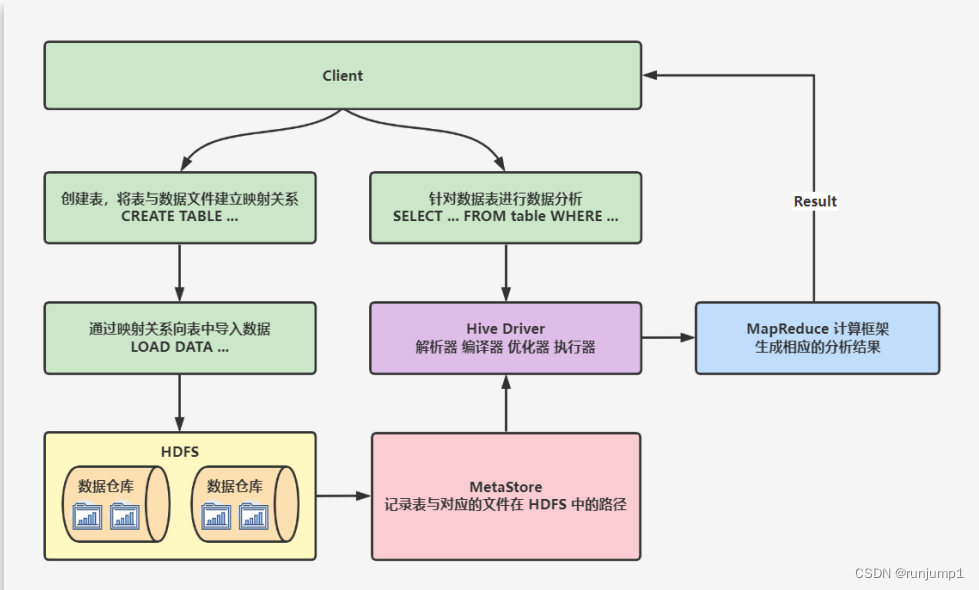
大致可分为五步:
1.创建表,将表与数据文件建立映射关系
2.通过映射关系向表中导入数据,就是把数据仓库中的数据跟这张表进行关联(Load Data)
3.然后元数据就会记录到MetaStore
4.执行查询的时候在进行解析编译优化执行,在解析阶段就会去关联元数据
5.最后通过MR计算返回结果


















 4606
4606

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











