







 SMOKE是一种创新的单阶段3D目标检测方法,它摒弃了传统的2D提案网络,转而使用关键点估计与3D变量回归。通过多步解耦策略,显著提高了训练效率和检测精度。该方法使用DLA-34作为Backbone,通过关键点分支和回归分支联合预测对象的3D边界框。
SMOKE是一种创新的单阶段3D目标检测方法,它摒弃了传统的2D提案网络,转而使用关键点估计与3D变量回归。通过多步解耦策略,显著提高了训练效率和检测精度。该方法使用DLA-34作为Backbone,通过关键点分支和回归分支联合预测对象的3D边界框。
动机:
in this paper that predicts a 3D bounding box for each detected object by combining a single keypoint estimate with regressed 3D variables. As a second contribution, we propose a multi-step disentangling approach for constructing the 3D bounding box, which signifificantly improves both training convergence and detection accuracy.
【CC】首先对于3D BB位置预测放弃了2D BB的RPN,使用keypointde+3D变量回归的方式. 其次,对于3D BB的构造采用解耦的多阶段方式提升了训练的便利性和精度
相关工作:
Previous state-of-the-art monocular 3D object detection algorithms [25, 1, 21] heavily depend on region-based convolutional neural networks (R-CNN) or region proposal network (RPN) structures [28, 18, 7]. Based on the learned high number of 2D proposals, these approaches attach an additional network branch to either learn 3D information or to generate a pseudo point cloud and feed it into point cloud-detection network.
【CC】老的方式都是基于先proposal一堆2D BB,然后要么 1)增加额外的网络层去学习3D信息 要么2)生成伪点云然后塞到点云检测网络
In this paper, we propose an innovative single-stage 3D object detection method that pairs each object with a single keypoint. We transform these variables together with projected keypoint to 8 corner representation of 3D boxes and regress them with a unifified loss function. The second contribution of our work is a multi-step disentanglement approach for 3D bounding box regression.
【CC】将目标检测变成了key point的估计;3D-BB基础表达为8个3D点,解耦去回归3D-BB
形式化描述:
Given a single RGB image I ∈ R W×H×3, with W being the width and H being the height of the image, find for each present object its category label C and its 3D bounding box B, where the latter is parameterized by 7 variables (h, w, l, x, y, z, θ). Here, (h, w, l) represent
the height, weight, and length of each object in meters, and (x, y, z) is the coordinates (in meters) of the object center in the camera coordinate frame. Variable θ is the yaw orientation of the corresponding cubic box.
【CC】输入图片I,输出类别C和3D-BB B;B表示为7维变量 (h, w, l, x, y, z, θ), 其中(h, w, l)表示高/宽/长,(x, y, z) 相机坐标系下(其实就是自车坐标系)的中心点,θ表示航向角
网络架构: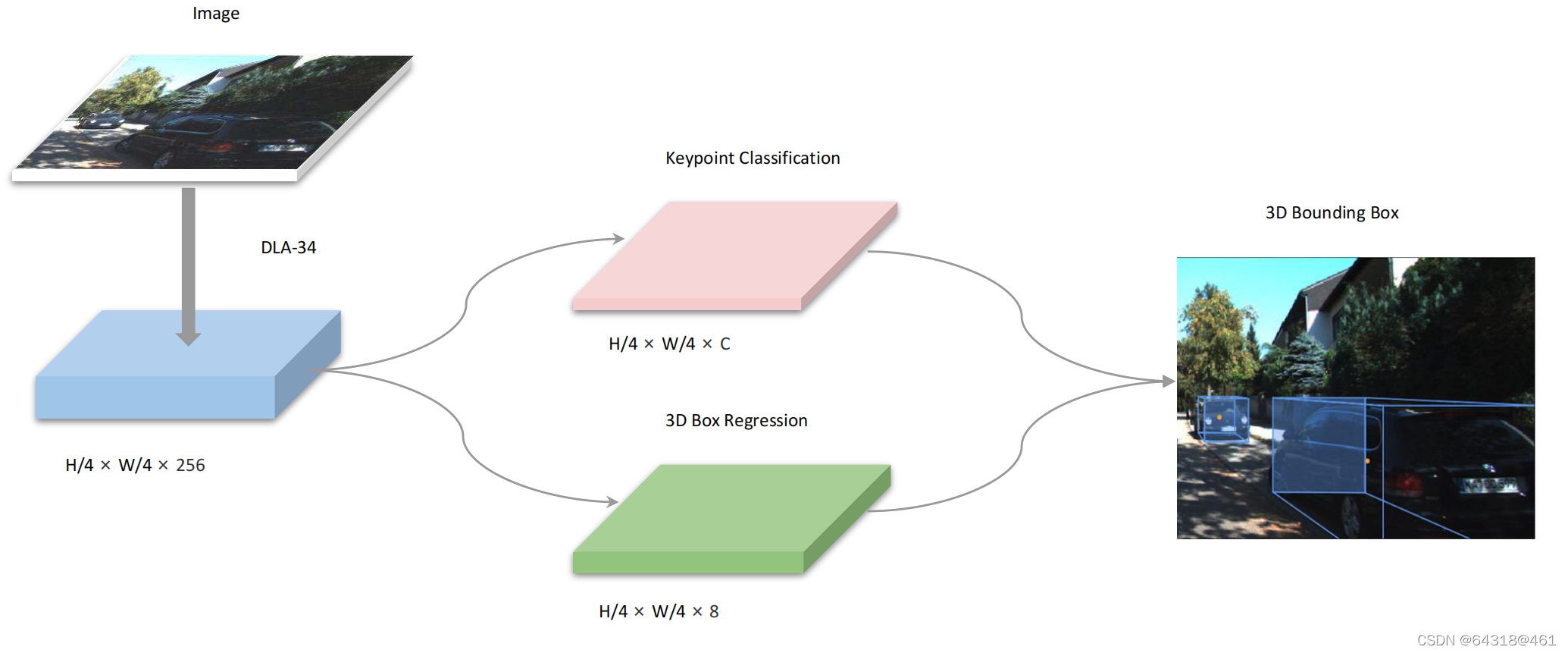
Figure 2. Network Structure of SMOKE. We leverage DLA-34 [41] to extract features from images. The size of the feature map is 1:4 due to downsampling by 4 of the original image. Two separate branches are attached to the feature map to perform keypoint classification(pink) and 3D box regression (green) jointly. The 3D bounding box is obtained by combining information from two branches.
【CC】Backbone是DLA-34,1/4的下采样;两个Header分别是keypoint 分类/3D-BB回归
Backbone
We use a hierarchi
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1059
1059

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









