







 本文详细介绍了Spark的合并算子union(), 排序算子sortBy()及其按键排序sortByKey(),连接算子如内连接join()、左外连接leftOuterJoin()、右外连接rightOuterJoin()和全外连接fullOuterJoin(),以及交集、去重、组合分组、归约、按键计数、前截取、遍历和存文件等算子的功能和使用案例。"
114345833,10541041,C语言连接MySQL数据库教程,"['数据库连接', 'C语言开发', 'MySQL API']
本文详细介绍了Spark的合并算子union(), 排序算子sortBy()及其按键排序sortByKey(),连接算子如内连接join()、左外连接leftOuterJoin()、右外连接rightOuterJoin()和全外连接fullOuterJoin(),以及交集、去重、组合分组、归约、按键计数、前截取、遍历和存文件等算子的功能和使用案例。"
114345833,10541041,C语言连接MySQL数据库教程,"['数据库连接', 'C语言开发', 'MySQL API']
(五)合并算子 - union()
1、合并算子功能
- union()算子将两个RDD合并为一个新的RDD,主要用于对不同的数据来源进行合并,两个RDD中的数据类型要保持一致。
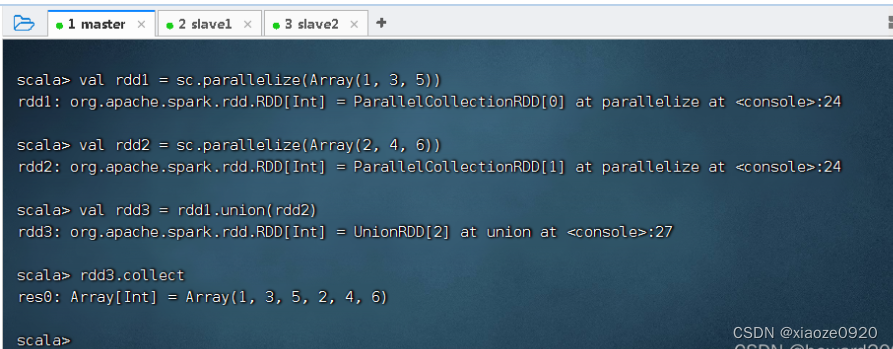
2、合并算子案例
- 创建两个RDD,合并成一个新RDD
(六)排序算子 - sortBy()
1、排序算子功能
sortBy()算子将RDD中的元素按照某个规则进行排序。该算子的第一个参数为排序函数,第二个参数是一个布尔值,指定升序(默认)或降序。若需要降序排列,则需将第二个参数置为false。
2、排序算子案例
一个数组中存放了三个元组,将该数组转为RDD集合,然后对该RDD按照每个元素中的第二个值进行降序排列。
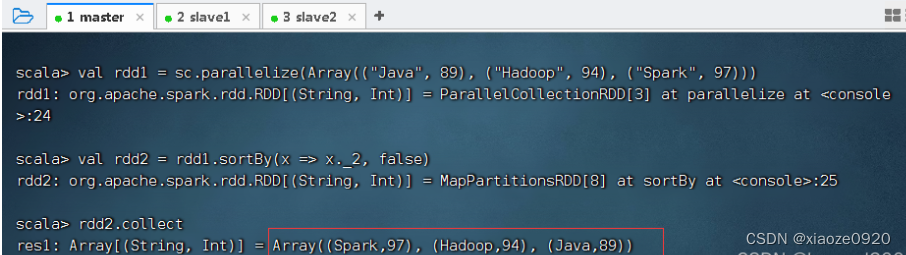
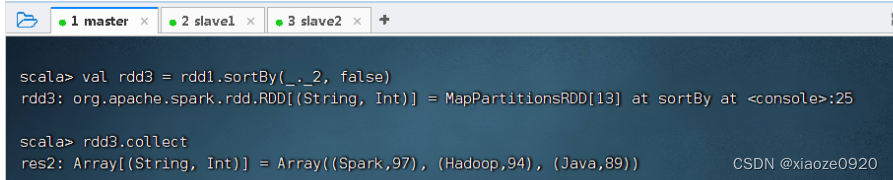
sortBy(x=>x._2,false)中的x代表rdd1中的每个元素。由于rdd1的每个元素是一个元组,因此使用x._2取得每个元素的第二个值。当然,sortBy(x=>x._2,false)也可以直接简化为sortBy(_._2,false)
(七)按键排序算子 - sortByKey()
1、按键排序算子功能
sortByKey()算子将(key,value)形式的RDD按照key进行排序。默认升序,若需降序排列,则可以传入参数false。
2、按键排序算子案例
将三个二元组构成的RDD按键先降序排列,然后升序排列
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 542
542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









