




 本文详细介绍了Spark的reduceByKey算子,用于对(key, value)形式的RDD进行按键归约,将相同key的value聚合。通过实例展示了在Spark Shell和IDEA中如何计算学生总分,涉及HDFS的读写操作,并处理权限问题。"
51281545,5613276,Unity制作VR视频播放器教程,"['Unity开发', '虚拟现实', 'VR应用', '3D开发', '游戏开发']
本文详细介绍了Spark的reduceByKey算子,用于对(key, value)形式的RDD进行按键归约,将相同key的value聚合。通过实例展示了在Spark Shell和IDEA中如何计算学生总分,涉及HDFS的读写操作,并处理权限问题。"
51281545,5613276,Unity制作VR视频播放器教程,"['Unity开发', '虚拟现实', 'VR应用', '3D开发', '游戏开发']
(四)按键归约算子 - reduceByKey()
1、按键归约算子功能
- reduceByKey()算子的作用对像是元素为(key,value)形式(Scala元组)的RDD,使用该算子可以将相同key的元素聚集到一起,最终把所有相同key的元素合并成一个元素。该元素的key不变,value可以聚合成一个列表或者进行求和等操作。最终返回的RDD的元素类型和原有类型保持一致。
2、按键归约算子案例
任务1、在Spark Shell里计算学生总分
- 成绩表,包含四个字段(姓名、语文、数学、英语),只有三条记录
- 创建成绩列表
scores,基于成绩列表创建rdd1,对rdd1按键归约得到rdd2,然后查看rdd2内容
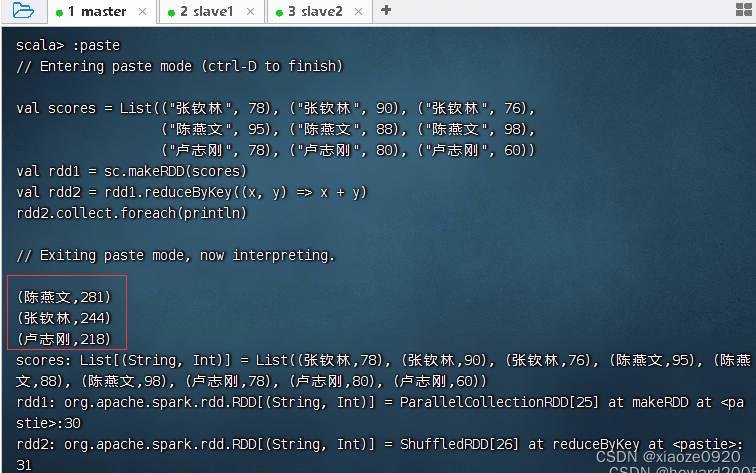
val scores = List(("张钦林", 78), ("张钦林", 90), ("张钦林", 76),
("陈燕文", 95), ("陈燕文", 88), ("陈燕文", 98),
("卢志刚", 78), ("卢志刚", 80), ("卢志刚", 60))
val rdd1 = sc.makeRDD(scores)
val rdd2 = rdd1.reduceByKey((x, y) => x + y)
rdd2.collect.foreach(println)
任务2、在IDEA里计算学生总分
-
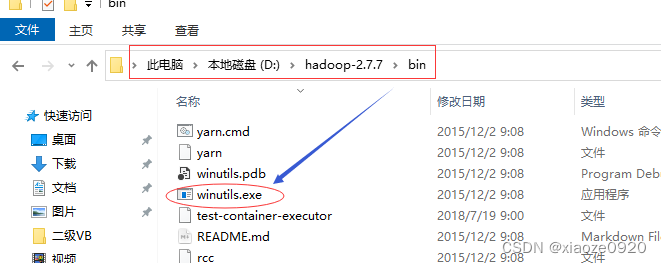
可能存在问题:在Windows下的IDEA中访问HDFS报错
Could not locate executable null\bin\winutils.exe -
下载对应版本的
winutils.exe,放在hadoop安装目录的bin子目录里 -
-
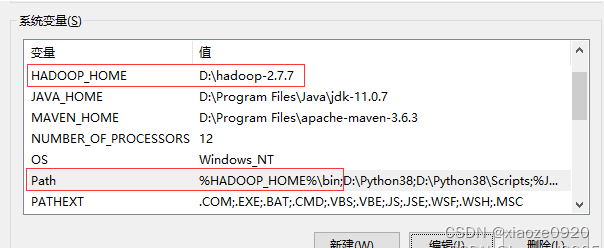
配置hadoop环境变量
-
-
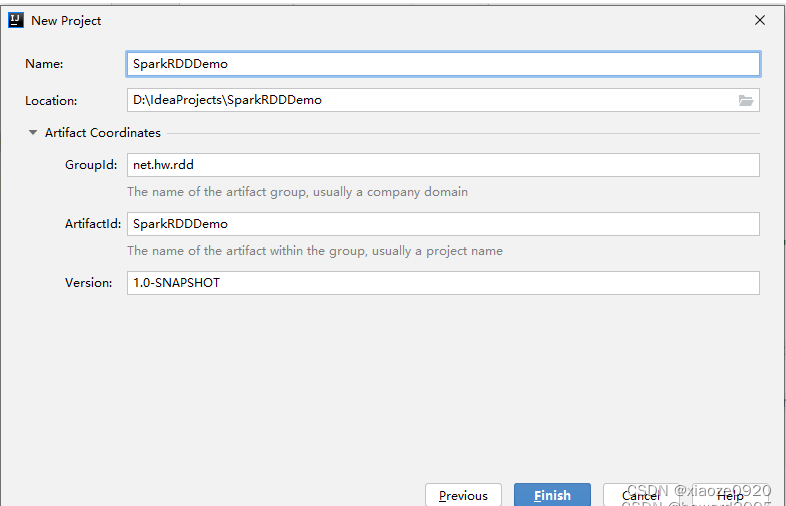
创建Maven项目 - SparkRDDDemo
-
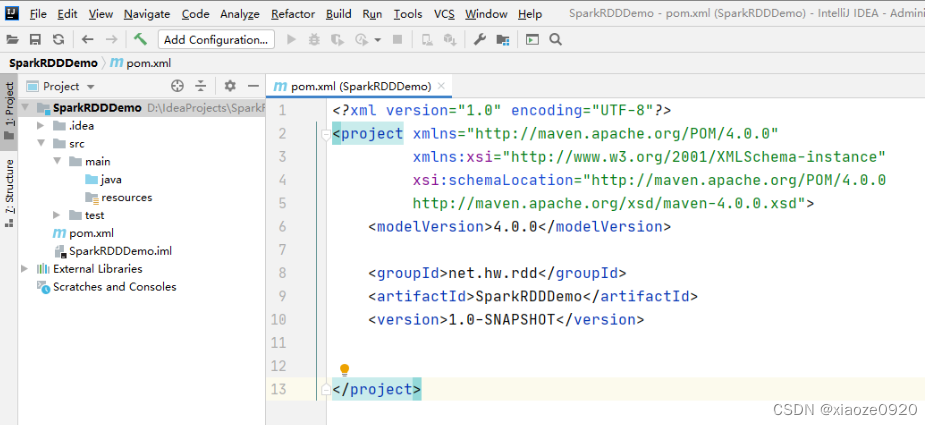
-
将
java目录改为scala -
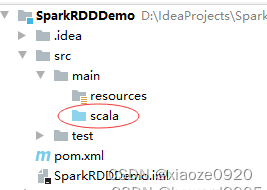
-
在
pom.xml文件里添加依赖和构建插件 -
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>net.hw.rdd</groupId> <artifactId>SparkRDDDemo</artifactId> <version>1.0-SNAPSHOT</version> <dependencies> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>2.12.15</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</artifactId> <version>2.4.4</version> </dependency> </dependencies> <build> <sourceDirectory>src/main/scala</sourceDirectory> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-assembly-plugin</artifactId> <version>3.3.0</version> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.3.2</version> <executions> <execution> <id>scala-compile-first</id> <phase>process-resources</phase> <goals> <goal>add-source</goal> <goal>compile</goal> </goals> </execution> <execution> <id>scala-test-compile</id> <phase>process-test-resources</phase> <goals> <goal>testCompile</goal> </goals> </execution> </executions> </plugin> </plugins> </build> </project>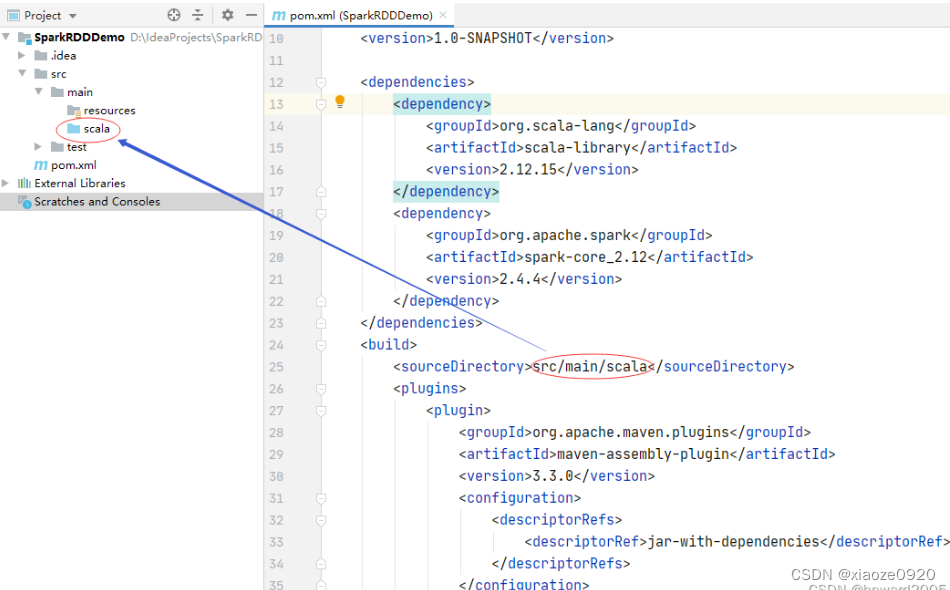
-
在资源文件夹里创建日志属性文件
-
-
log4j.rootLogger=ERROR, stdout, logfile log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n log4j.appender.logfile=org.apache.log4j.FileAppender log4j.appender.logfile.File=target/spark.log log4j.appender.logfile.layout=org.apache.log4j.PatternLayout log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n -
创建
net.hw.rdd包 -
第一种方式:读取二元组成绩列表
- 在
net.hw.rdd包里创建CalculateScoreSum单例对象 -
package net.hw.rdd import org.apache.spark.{SparkConf, SparkContext} /** * 功能:计算总分 * 作者:华卫 * 日期:2022年05月24日 */ object CalculateScoreSum { def main(args: Array[String]): Unit = { // 创建Spark配置对象 val conf = new SparkConf() .setAppName("CalculateScoreSum") .setMaster("local[*]") // 基于配置创建Spark上下文 val sc = new SparkContext(conf) // 创建成绩列表 val scores = List( ("张钦林", 78), ("张钦林", 90), ("张钦林", 76), ("陈燕文", 95), ("陈燕文", 88), ("陈燕文", 98), ("卢志刚", 78), ("卢志刚", 80), ("卢志刚", 60) ) // 基于成绩列表创建RDD val rdd1 = sc.makeRDD(scores) // 对成绩RDD进行按键归约处理 val rdd2 = rdd1.reduceByKey((x, y) => x + y) // 输出归约处理结果 rdd2.collect.foreach(println) } } -
运行程序,查看结果
-
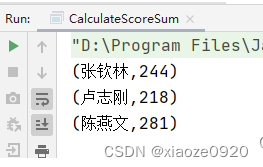
第二种方式:读取四元组成绩列表
- 在
net.hw.rdd包里创建CalculateScoreSum02单例对象 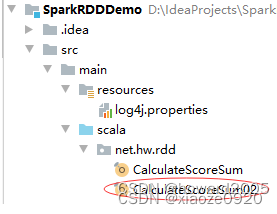
package net.hw.rdd
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.ListBuffer
/**
* 功能:计算总分
* 作者:华卫
* 日期:2022年05月31日
*/
object CalculateScoreSum02 {
def main(args: Array[String]): Unit = {
// 创建Spark配置对象
val conf = new SparkConf()
.setAppName("CalculateScoreSum")
.setMaster("local[*]")
// 基于配置创建Spark上下文
val sc = new SparkContext(conf)
// 创建四元组成绩列表
val scores = List(
("张钦林", 78, 90, 76),
("陈燕文", 95, 88, 98),
("卢志刚", 78, 80, 60)
)
// 将四元组成绩列表转化成二元组成绩列表
val newScores = new ListBuffer[(String, Int)]();
// 通过遍历算子遍历四元组成绩列表
scores.foreach(score => {
newScores += Tuple2(score._1, score._2)
newScores += Tuple2(score._1, score._3)
newScores += Tuple2(score._1, score._4)}
)
// 基于二元组成绩列表创建RDD
val rdd1 = sc.makeRDD(newScores)
// 对成绩RDD进行按键归约处理
val rdd2 = rdd1.reduceByKey((x, y) => x + y)
// 输出归约处理结果
rdd2.collect.foreach(println)
}
}
- 可以采用循环结构将四元组成绩列表转化成二元组成绩列表
-
for (score <- scores) { newScores += Tuple2(score._1, score._2) newScores += Tuple2(score._1, score._3) newScores += Tuple2(score._1, score._4) }运行程序,查看结果
-
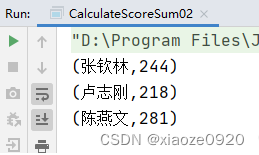
第三种情况:读取HDFS上的成绩文件
- 在master虚拟机的
/home目录里创建成绩文件 -scores.txt 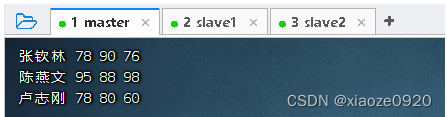
- 将成绩文件上传到HDFS的
/input目录
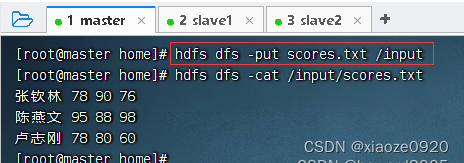
- 在
net.hw.rdd包里创建CalculateScoreSum03单例对象
package net.hw.rdd
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.ListBuffer
/**
* 功能:计算总分
* 作者:华卫
* 日期:2022年05月31日
*/
object CalculateScoreSum03 {
def main(args: Array[String]): Unit = {
// 创建Spark配置对象
val conf = new SparkConf()
.setAppName("CalculateScoreSum")
.setMaster("local[*]")
// 基于配置创建Spark上下文
val sc = new SparkContext(conf)
// 读取成绩文件,生成RDD
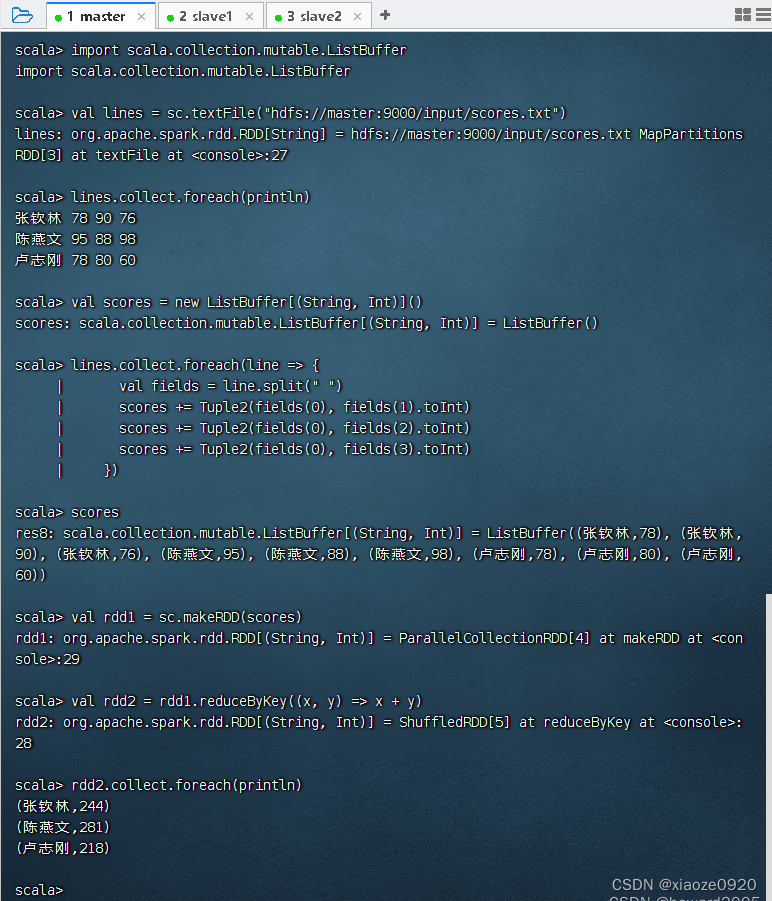
val lines = sc.textFile("hdfs://master:9000/input/scores.txt")
// 定义二元组成绩列表
val scores = new ListBuffer[(String, Int)]()
// 遍历lines,填充二元组成绩列表
lines.collect.foreach(line => {
val fields = line.split(" ")
scores += Tuple2(fields(0), fields(1).toInt)
scores += Tuple2(fields(0), fields(2).toInt)
scores += Tuple2(fields(0), fields(3).toInt)
})
// 基于二元组成绩列表创建RDD
val rdd1 = sc.makeRDD(scores)
// 对成绩RDD进行按键归约处理
val rdd2 = rdd1.reduceByKey((x, y) => x + y)
// 输出归约处理结果
rdd2.collect.foreach(println)
}
}
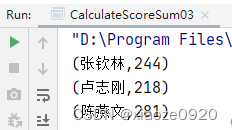
- 运行程序,查看结果
- 在Spark Shell里完成同样的任务
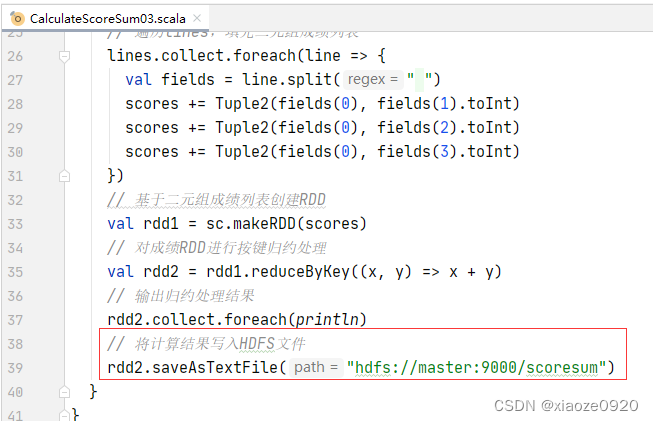
- 修改程序,将计算结果写入HDFS文件
- 运行程序,报错没有
写权限
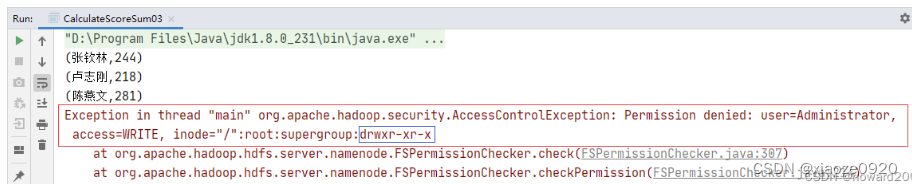
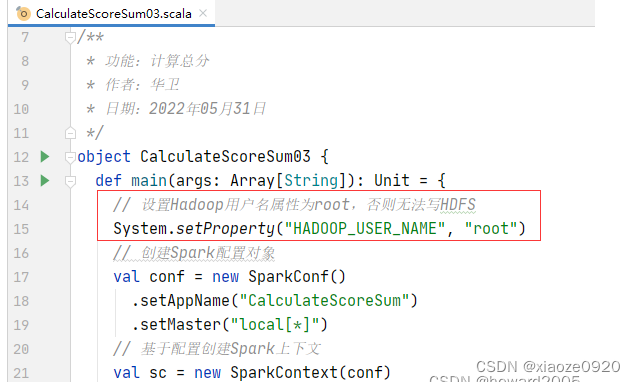
- 设置
HADOOP_USER_NAME属性为root
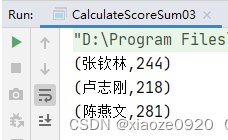
- 运行程序,查看结果
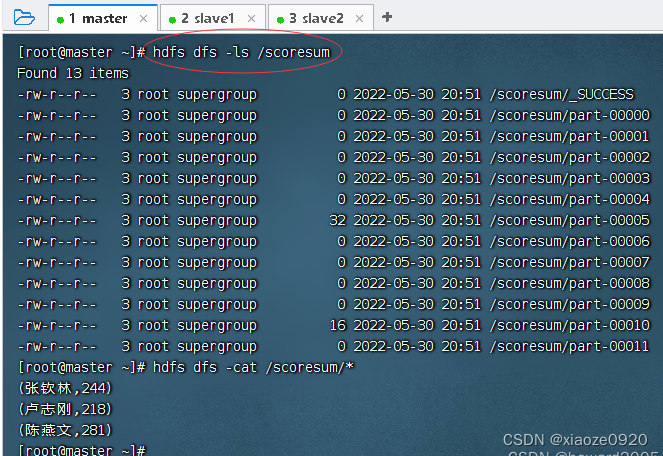
- 查看HDFS上生成的结果文件

















 3482
3482

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









