






动机
当前知识库补全的方法主要是将实体和关系嵌入到一个低维的向量空间,但是却只利用了知识库中的三元组结构 (<s,r,o>) 数据,而忽略了知识库中大量存在的文本,图片和数值信息。
本文将三元组以及多模态数据一起嵌入到向量空间,不仅能够使链接预测更加准确,而且还能产生知识库中实体缺失的多模态数据。
通过不同的 encoders,将多模态数据嵌入成低维向量做链接预测;
通过不同的 decoders,能够产生实体缺失的多模态数据。
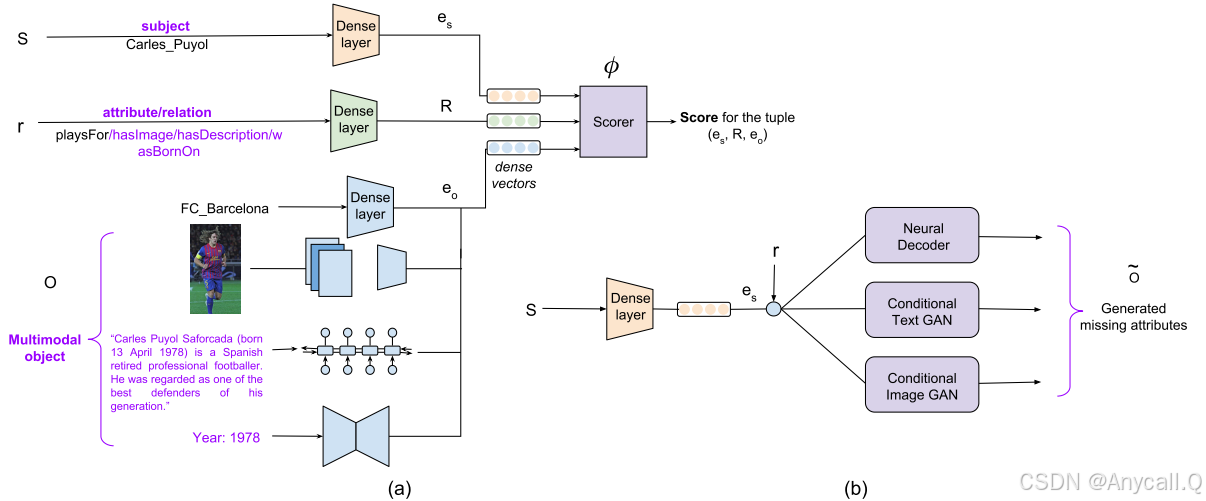
Encoding Multimodal Data(多模态数据的嵌入)
1、结构化数据:对于知识库中的实体,将他们的 one-hot 编码通过一个 denselayer (全连接层)得到它们的 embedding;
2、 数值信息:全连接网络,即通过一个前馈层,获得数值的 embedding;
3、文本:对于那些很短的文本,比如名字和标题,利用双向的 GRUs 编码字符;对于那些相对长的文本,通过 CNN 在词向量上卷积和池化得到最终编码;
4、图片:利用在 ImageNet 上预训练好的 VGG 网络,得到图片的 embedding;
训练:目标函数(二元交叉熵损失):
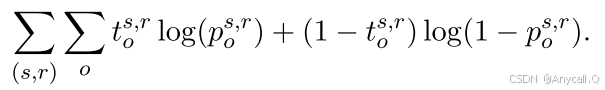
其中:
![]() 是一个 one-hot 向量。如果知识库中存在 <s, r, o> 这个三元组,
是一个 one-hot 向量。如果知识库中存在 <s, r, o> 这个三元组,![]() 值为 1,否则
值为 1,否则![]() 值为 0。
值为 0。![]() 是 <s, r, o> 模型预测出来的这个三元组成立的概率,它的值介于 0 到 1 之间。
是 <s, r, o> 模型预测出来的这个三元组成立的概率,它的值介于 0 到 1 之间。
在使用 ConvE 和 DistMult 模型时,训练过程采用了二进制交叉熵损失函数来优化模型。训练时没有进行负采样,直接对所有可能的三元组进行评分。
Decoding Multimodal Data(解码多模态数据)
1、数值和分类数据:利用一个全连接网络,输入是已经训练好的向量,输出是数值和类别,损失函数是 RMSE(均方根误差,用于数值预测)或者 cross-entropy(交叉熵损失,用于分类任务);
2、 文本:利用 ARAE 模型,输入是训练好的连续向量,输出是文本;
3、 图片:利用 GAN 模型来产生图片。
本文的创新点是引入了多模态数据来做知识库中的链接预测和生成实体缺失的多模态数据。但是不足之处在于不知道到底引入的哪一部分多模态数据对最终的链接预测产生提升,以及产生的多模态数据质量不是很理想。这有待于后续工作的改进。

















 751
751

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









