






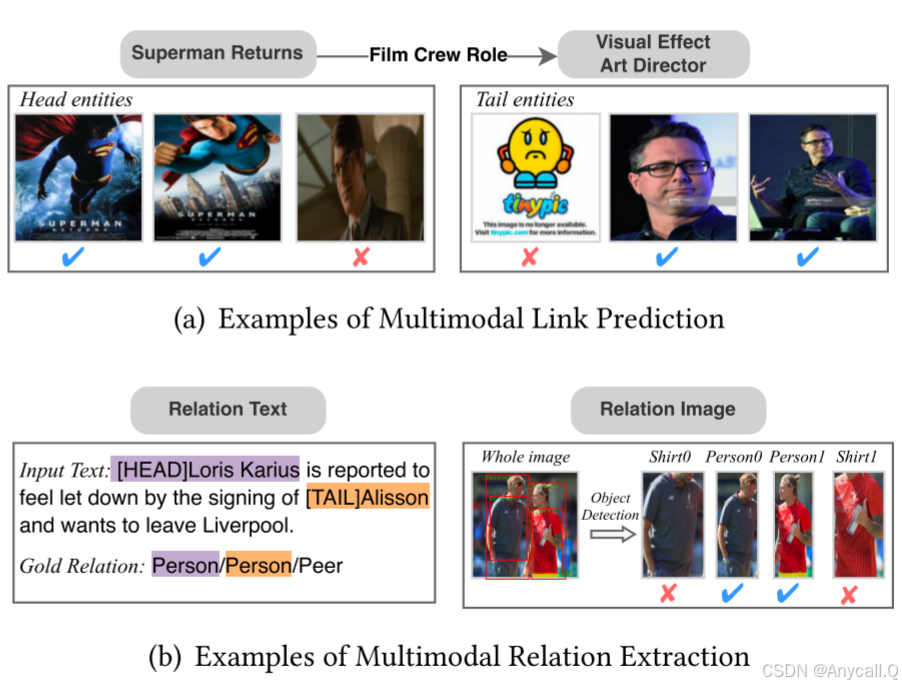
Figure 1:并非所有图像/对象都与文本输入相关,同一实体周围带有 ✔ 的图像/对象具有相关的视觉特征。 相反,带有 ✗ 的其他图像/对象与相应的实体无关。
对于多模态链接预测任务:每个实体拥有许多关联图像,这可以增强缺失三元组预测的实体表示
对于MNER(多模态命名实体识别) 和 MRE(多模态关系提取):每个短句都包含一个相应的图像,以补充实体和关系提取的文本上下文。
局限性:
1. 架构普遍性:应该推导出一个统一的模型,更有效和方便的扩大多模态KGC的不同子任务的应用
2. 模态矛盾:纳入不相关视觉信息的噪音会导致模态矛盾(有些图像甚至包含大量背景噪声,这可能会误导实体表示)
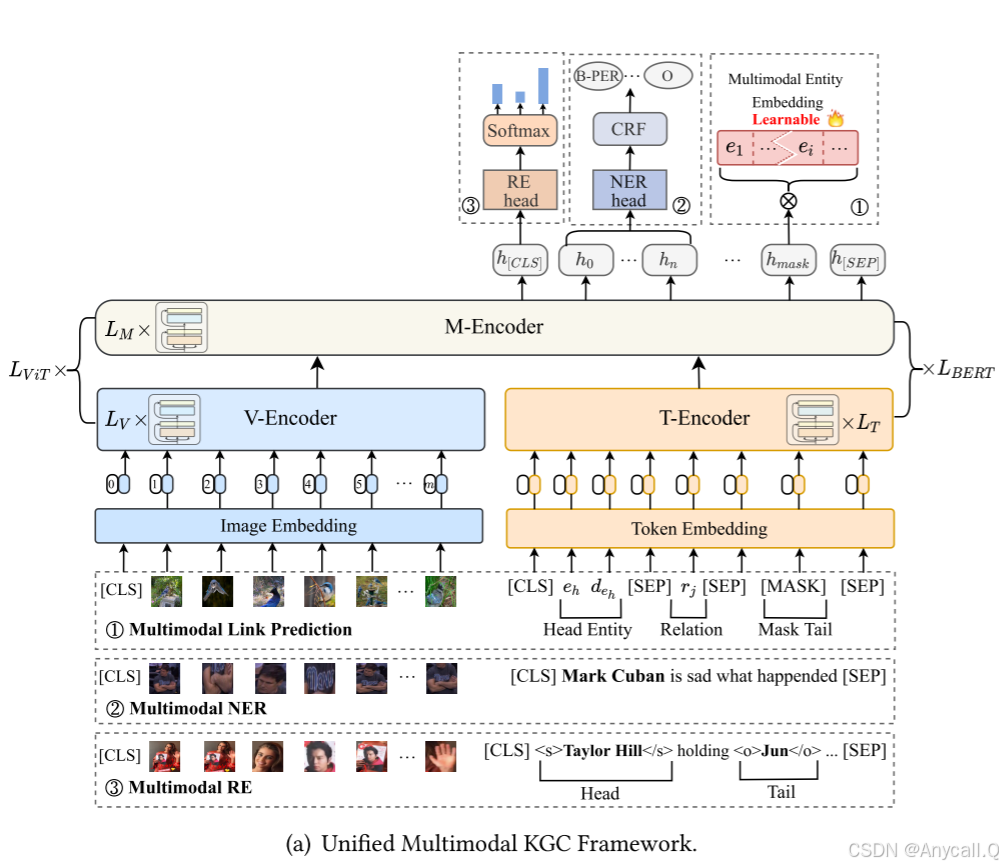
任务范式
1、Missing Entity Prediction(缺失实体预测)
将实体𝑒ℎ的多个修补图像处理到视觉侧,并将该三元组(𝑒ℎ,𝑟,?)转换为文本侧的输入序列:

其中 eℎ 为头实体,deh为头实体描述,mask为掩码,
CLS标记是放在输入序列的最前面,用作整个序列的聚合表示,
SEP标记用于区分不同的句子或段落。明确表示句子的边界
计算在𝑒ℎ,𝑟,Iℎ条件下𝑒t 的概率:
![]()
![]()
最后,通过二进制交叉熵损失训练MKGformer来预测多标签分类实体[MASK]
2、MRE(多模态关系提取)
关系提取旨在将文本中提到的关系链接到知识图谱中的关系类型。给定文本T和相应的图像I,旨在预测实体对 (𝑒ℎ,𝑒t) 之间的关系,并将关系类型的分布输出为:
![]()
3、MNER(多模态实体识别)
MNER是从文本序列和相应图像中提取命名实体的任务。给定一个标记序列 𝑇 = {𝑤1, . . . , 𝑤𝑛 }及其对应的图像 I,专注于将序列标签上的分布建模为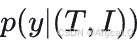 ,其中y是标签 ,𝑦 = {𝑦1, . . . , 𝑦𝑛 }的标签序列
,其中y是标签 ,𝑦 = {𝑦1, . . . , 𝑦𝑛 }的标签序列
V-Encoder(视觉编码器):
对图像进行分块、展平、投影,拼接嵌入
我们先将每个图像重新划分为到统一的𝐻×𝑊像素,然后将图像重新调整为 u = HW / P^2 个展平的二维小块(patch),其中 P 是每个小块的尺寸,
每个图像的小块经过池化和投影处理,变成 ![]() 的形式,其中 dV 是 ViT 模型(Vision Transformer模型)隐层状态的维度
的形式,其中 dV 是 ViT 模型(Vision Transformer模型)隐层状态的维度
将 o 张图像的小块嵌入表示拼接起来,得到视觉序列表示 ![]() ,其中 m = u × o
,其中 m = u × o
这样可以得到所有图像拼接后的特征表示,![]() 可以作为视觉特征输入后续的模型部分。
可以作为视觉特征输入后续的模型部分。
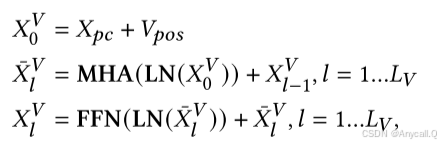
Vpos代表图像对应的位置嵌入,那么初始的图编码就是视觉特征编码+位置编码,
接着每层先进行LN(层归一化),再MHA(多头自注意力)再残差连接
最后一层先进行LN,再FFN(全连接)再残差连接
T-Encoder(文本编码器):
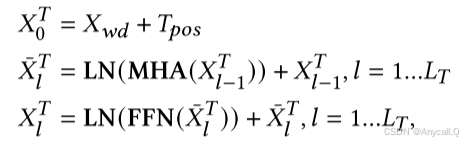
将文本序列 {𝑤1, . . . , 𝑤𝑛 } 通过词嵌入矩阵嵌入到 𝑋𝑤𝑑,再加上位置编码
剩余步骤和V-Encoder类似
M-Encoder(多模态编码器) :
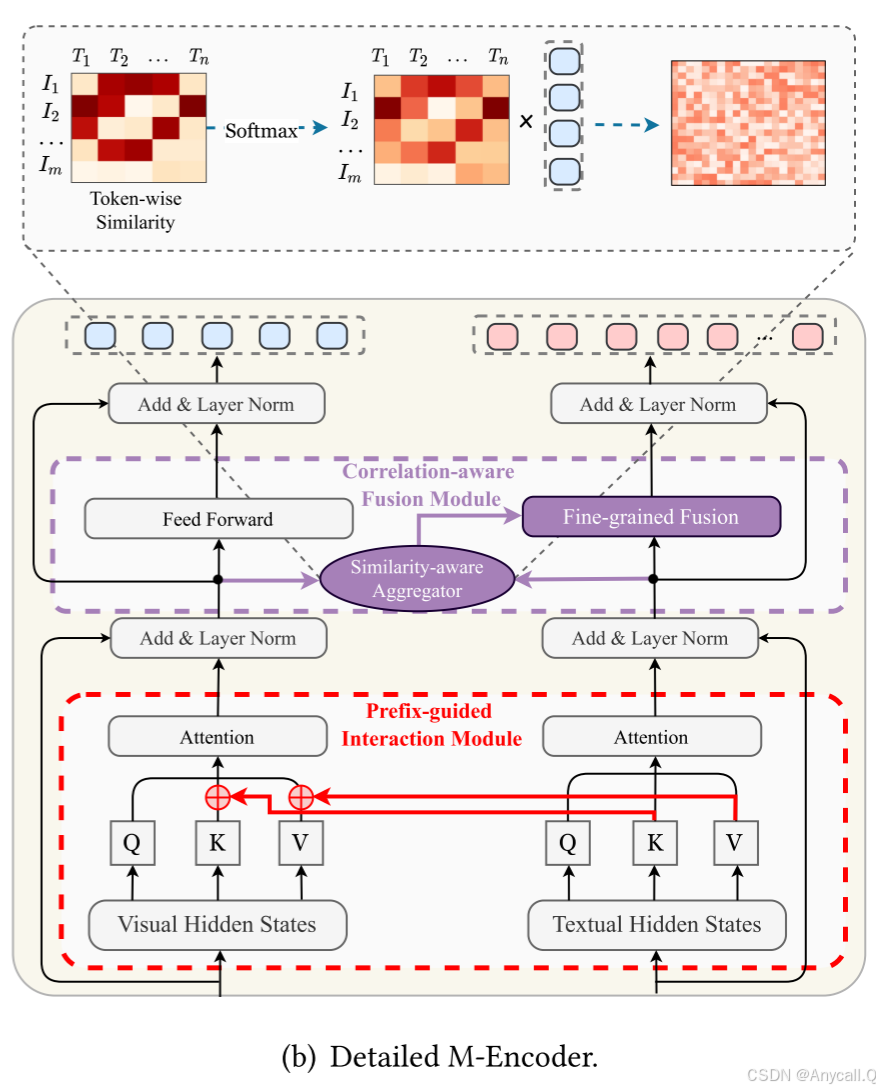
具体来说,我们在自注意力模块中提出了一个前缀引导交互模块(PGI)来预先减少模态异质性。我们还在 FFN 层中提出了一个相关感知融合模块(CAF),以减少不相关图像元素引起的噪声的影响。
前缀引导的交互模块:
提出了一种前缀引导的交互机制,通过计算各层的多头关注度,对混合键和混合值进行处理,从而预先降低通道的异构性。
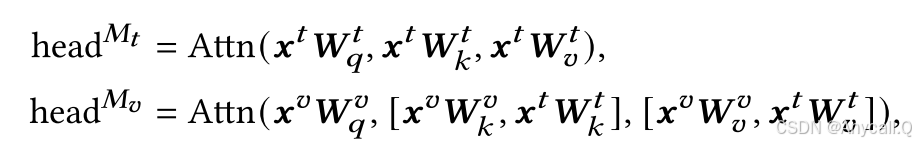
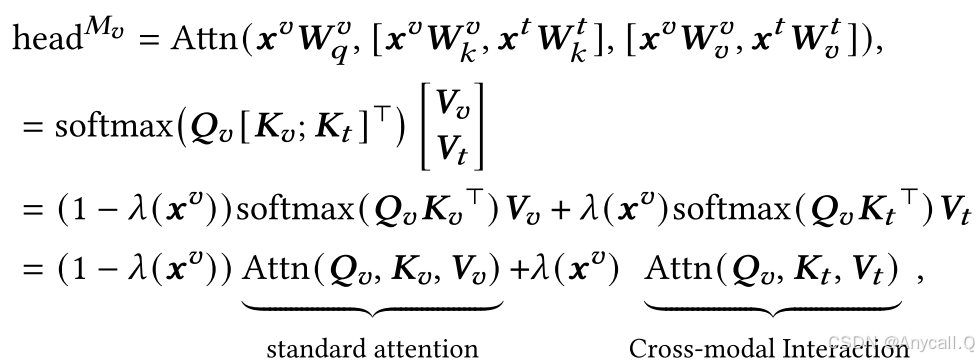
第一个项Attention是视觉方面的标准注意力,而第二个项表示跨模态交互。前缀引导的交互机制通过标量因子(即 1−𝜆 )将原始视觉注意概率的权重降低,并重新分配剩余的注意力概率质量 𝜆 以关注文本注意力,这类似于线性插值。
相关感知融合模块:
为了缓解噪声的不利影响,我们应用了一个相关性感知融合模块来进行两个通道之间的跨通道交互。
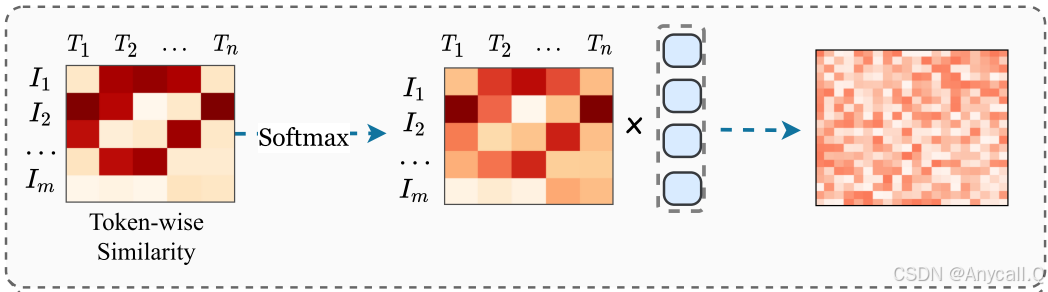
对于文本标记,我们计算其所有视觉标记的相似度矩阵如下:
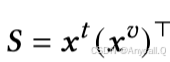
然后,对文本标记的相似矩阵𝑺执行softmax函数,并对图像中的视觉标记使用平均标记智能聚合器(将多个特征平均或加权平均的技术,)
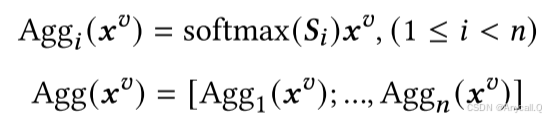
将相似感知的聚合视觉隐藏状态合并到FFN层的文本隐藏状态中,并将FFN过程的计算修改为:
![]()
总结
本文在自注意层提出了一个前缀引导的交互模块(PGI),以预先减少模态异质性,并进一步设计了一个相关感知融合模块(CFM),在FFN层实现了token-wise细粒度融合,以减少来自不相关图像/对象的噪声。在四个数据集上的大量实验结果证明了我们的MKGformer的有效性和鲁棒性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









