






DKRL(将结构和文本融合)
DKRL的能量函数
![]()
其中ES是基于结构的表示的能量函数,其公式与TransE相同,而ED是基于描述的表示的能量函数。
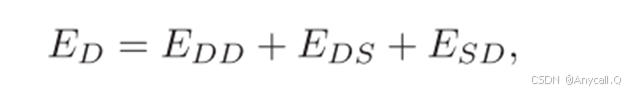
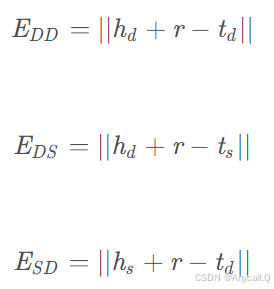
f(d) 是实体描述 d 的向量表示,用距离衡量实体与其描述的匹配程度、实体与其结构关系(即知识图谱中的实体和关系三元组)的一致性、衡量结构信息和描述信息之间的一致性。
通过将这三个部分结合在一起,DKRL 能够同时学习实体的描述、结构信息,并将二者有机结合,提高对实体的表征能力。
在本文中,提出了两个编码器来构建基于描述的表示
连续字袋编码器
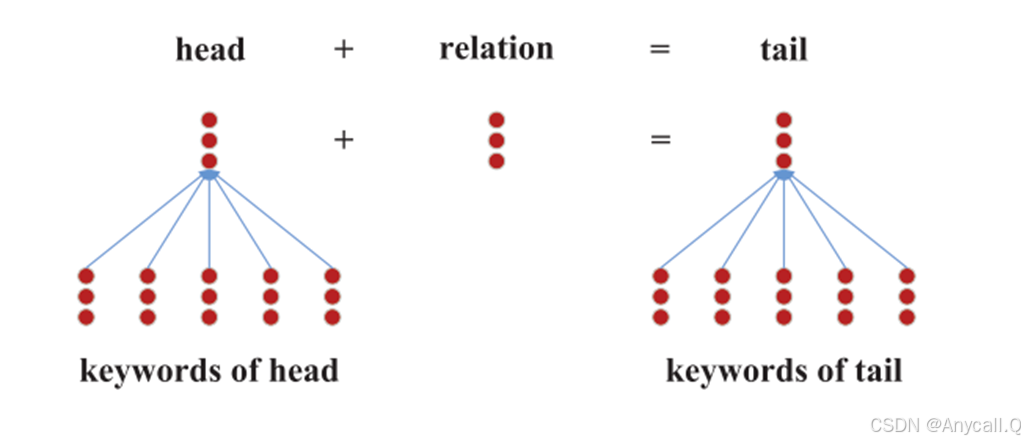
连续词袋模型(Continuous Bag of Words, CBOW)是用于自然语言处理任务中的一种词嵌入模型,常用于生成词向量。CBOW 通过上下文预测目标词。其基本原理是:给定一个词的上下文(即前后若干个词),模型预测这个词本身。(假设有一个句子“猫在草地上玩耍”,若选择“草地”为目标词,上下文则为“猫在”和“上玩耍”。CBOW 模型会通过这些上下文词预测目标词“草地”。)
我们在每个实体的描述中选择前n个关键词作为输入(一些经典的文本特征,如TF-IDF,可以用于对关键词进行排序)。 然后我们简单地将关键词的嵌入相加,得到忽略词序的实体嵌入:
![]()
卷积神经网络编码器
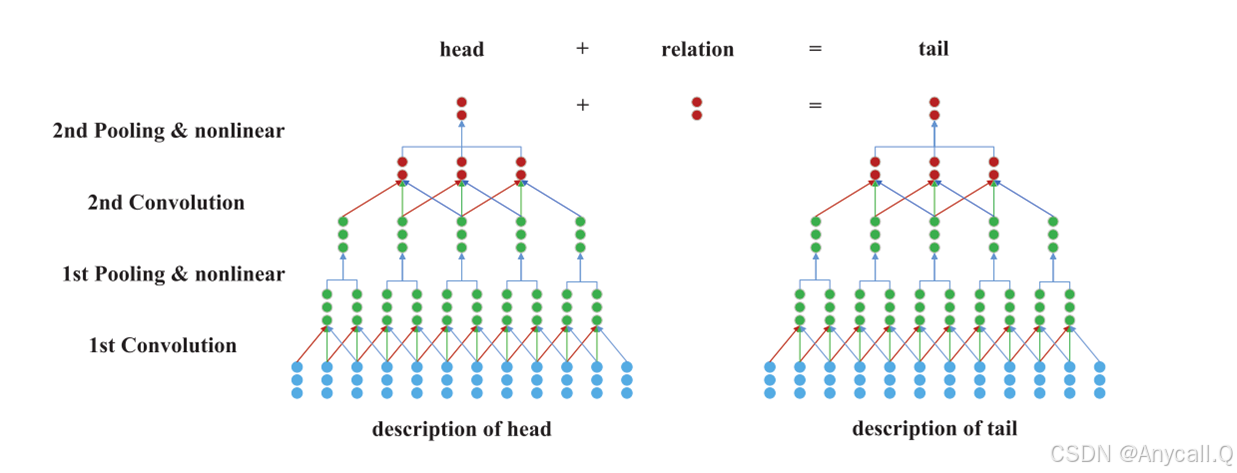
设Z(l)为第l个卷积层的输出,设X(l)为第l个卷积层的输入。
预处理中,我们首先从原始文本中删除所有停止词(频率很高,但对语义贡献较少的词),然后在描述中标记所有短语(我们简单地选择训练集中的所有实体名称作为短语),并将这些短语视为单词。之后,每个单词都由一个单词嵌入表示,作为卷积层的输入。
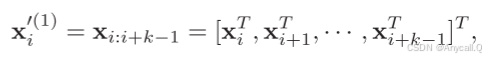
卷积中,首先,大小为 k 的窗口将滑动 ![]() 中的输入向量以获得
中的输入向量以获得 ![]() ,
,![]() 是表示为一组向量(x0,x1,…,xn)的预处理描述,
是表示为一组向量(x0,x1,…,xn)的预处理描述,![]() 表示
表示![]() 的第 i 个向量通过连接输入句子的第i个窗口中的k个列向量得到的。
的第 i 个向量通过连接输入句子的第i个窗口中的k个列向量得到的。
由于在进行窗口处理时输入的长度是可变的,我们还在每个输入向量的末尾添加全零填充向量。卷积层的第i个输出向量为:
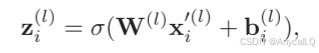
通过这种方式,我们可以对齐输入句子的可变长度,同时避免全零填充可能产生的副作用。
池化中,前面用最大池化,最后一次用平均池化
损失函数:
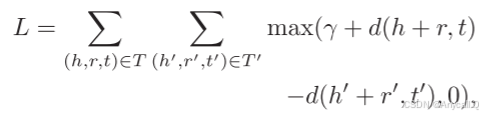
IKRL(将结构和图像融合)
IKRL的能量函数
![]()
ESS是与TransE相同的能量函数,只取决于基于结构的表示:
![]()
EII中头实体和尾实体都是基于图像的表示:
![]()
![]()
确保基于结构的表示和基于图像的表示都被学习到相同的向量空间中。
IKRL模型的总体架构
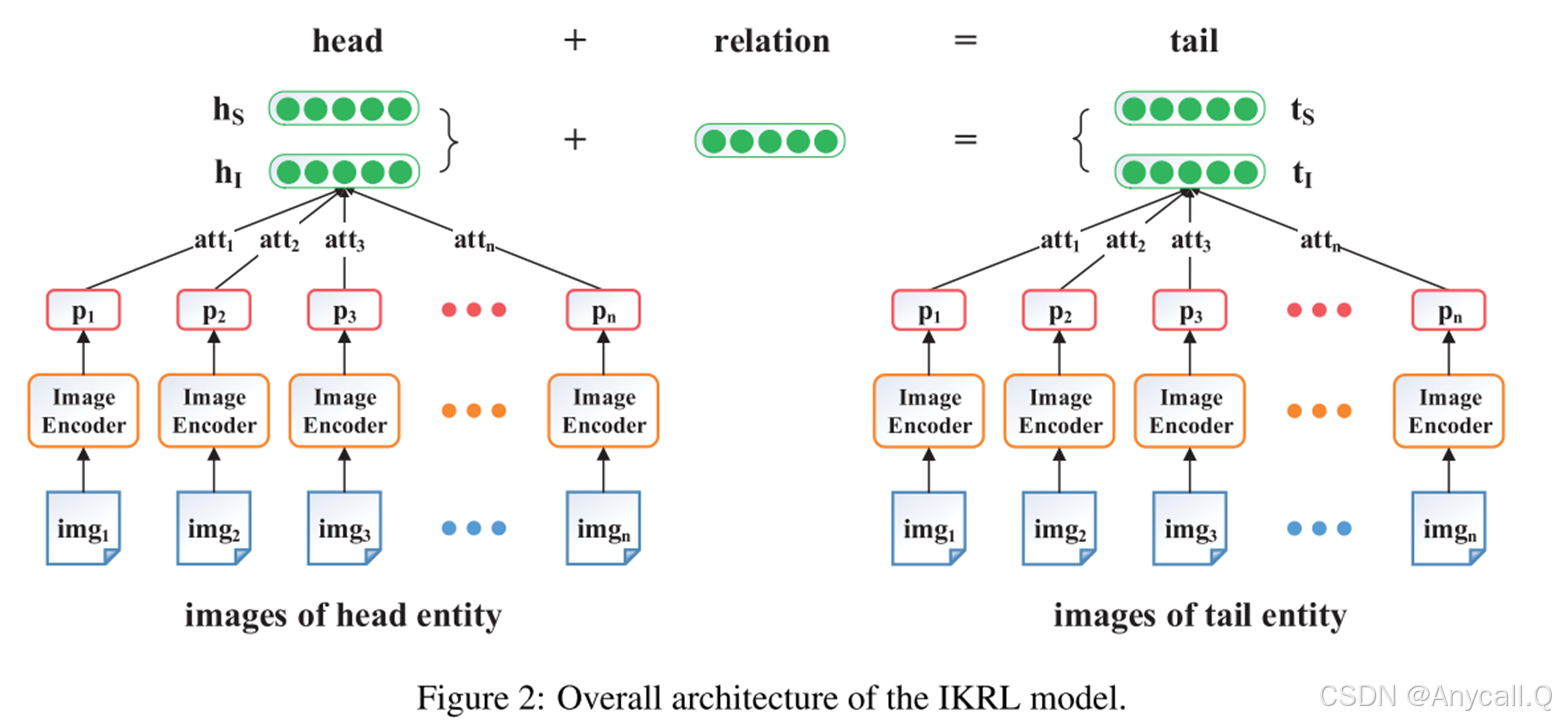
每个实体具有多个提供重要视觉信息的实体图像。首先设计了一个神经网络图像编码器,以每一幅实体图像为输入。图像编码器的目标是从图像中提取信息特征,并在实体空间中构造图像表示。其次,为了实现多个图像表示的融合,我们实现了一种基于实例级注意力的学习方法,自动计算每个实体在不同图像实例上所应给予的注意力。最后,在全局能量函数下,将聚合后的图像表示与结构表示进行联合学习。
神经网络图像编码器:
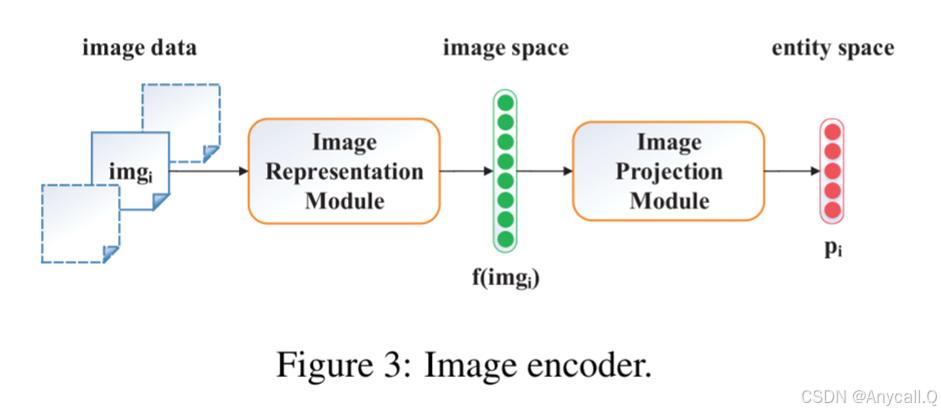
图像表示模块利用神经网络来提取图像中的鉴别性特征,并为每个图像构建图像特征表示。
图像投影模块试图将这些图像特征表示从图像空间投影到实体空间。图像表示模块使用了AlexNet(作为神经网络来提取图像的特征,包含5个卷积层、2个全连接层和1个softmax层),用一个共享的投影矩阵将图像特征表示从图像空间转移到实体空间。
第i幅图像在实体空间中基于图像的表示pi被定义为:
![]()
f (imgi)代表图像空间中的第i个图像特征表示,由图像表示模块构建
多个图像表示的融合:
一种基于实例级注意力的学习方法,自动计算每个实体在不同图像实例上所应给予的注意力。最后,在全局能量函数下,将聚合后的图像表示与结构表示进行联合学习。对于第k个实体的第i个图像表示p(k)i,注意力被定义如下:
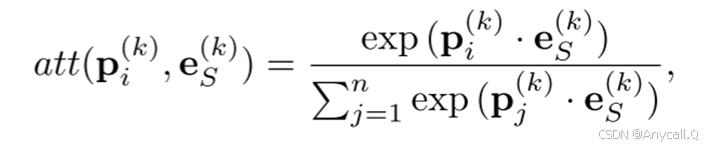
![]() 表示第k个实体的第i个图像的特征,
表示第k个实体的第i个图像的特征,![]() 表示第k个实体的基于结构的表示
表示第k个实体的基于结构的表示
通过上述基于注意力的方法,便可求出第k个实体的集成IBR
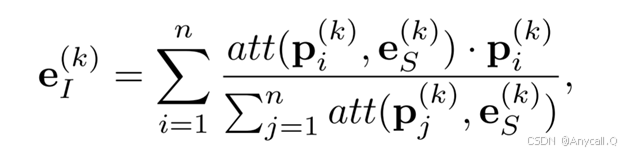
e(k)I本质上就是对第K个实体的i个图像表示p(k)i求加权平均,权重就是上面求的注意力

















 321
321

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









