







深度学习基础
课程视频:https://space.bilibili.com/1567748478/channel/seriesdetail?sid=358497
课程教材:https://zh.d2l.ai/
加油加油!俺可以!
深度学习相关介绍
应用:图片分类、物体检测和分割、样式迁移、人脸合成、文字生成图片、文字生成(QA)、无人驾驶。
案例-广告点击:触发(关键词)–> 点击率预估 --> 排序(点击率 * 竞价)
安装
- 使用conda/ miniconda环境
我这里是在Windows下,使用conda环境,如下命令可以创建一个新的环境:
conda create --name d2l python=3.9 -y
激活 d2l 环境:
conda activate d2l
- 安装需要的包
pip install torch==1.12.0
pip install torchvision==0.13.0
pip install d2l==0.17.6
- 接下来,需要下载这本书的代码
进入自己的代码工作目录
d:
cd D:\code\d2l
下载代码:
mkdir d2l-zh && cd d2l-zh
curl https://zh-v2.d2l.ai/d2l-zh-2.0.0.zip -o d2l-zh.zip
下载完之后可以直接在对应路径进行解压,最后切换到解压后的文件目录,输入以下命令:
jupyter notebook
现在可以在Web浏览器中打开http://localhost:8888(通常会自动打开)。 由此,我们可以运行这本书中每个部分的代码,如下图所示。
由于课程中课件是以jupyter幻灯片文件存在的,所以需要安装jupyter幻灯片插件才能查看
pip install rise
数据操作+数据预处理
N维数组样例
- N维数组是机器学习和神经网络的主要数据结构

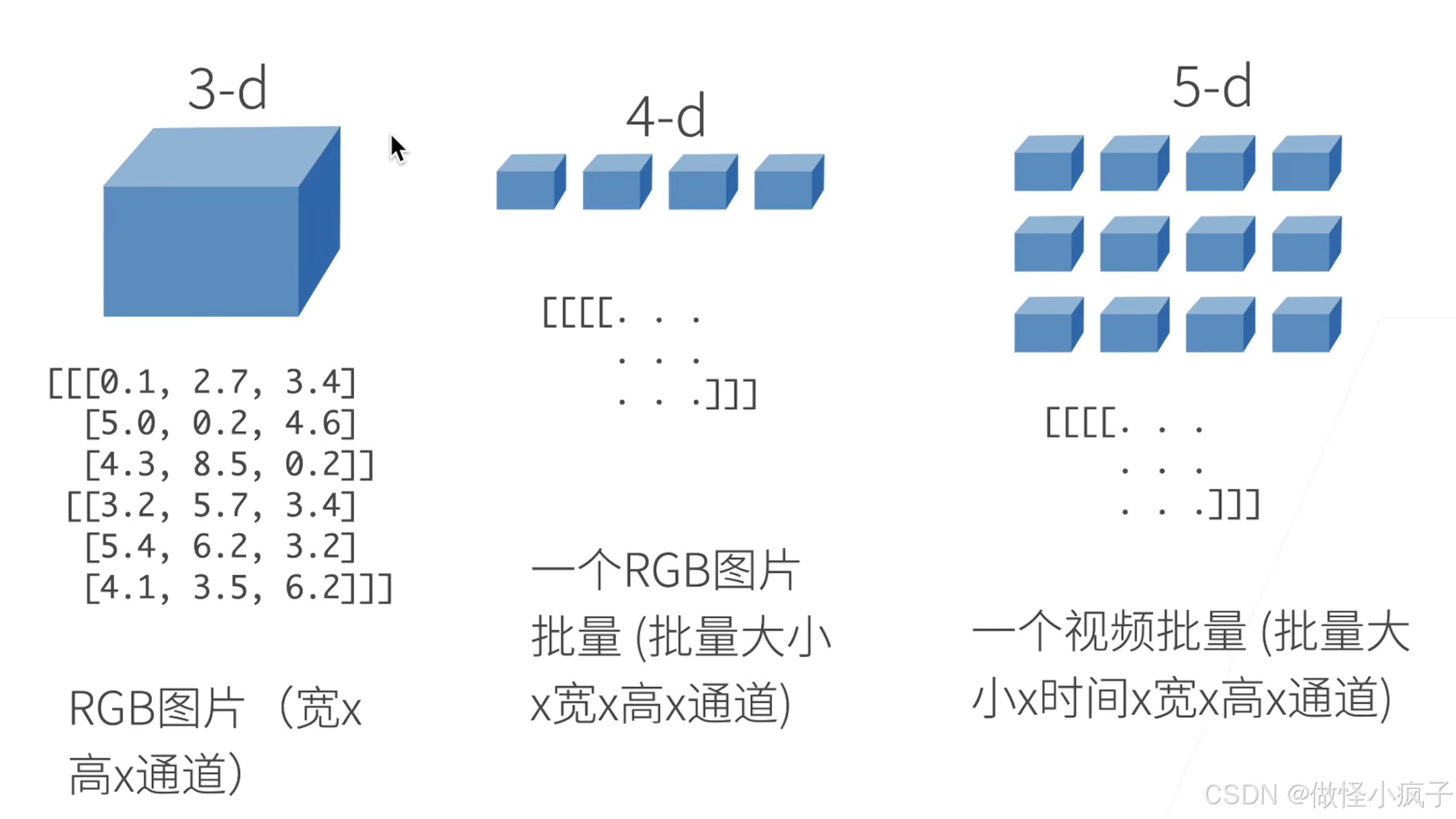
创建数组
- 数组需要
- 形状:例如3 * 4矩阵
- 每个元素的数据类型:例如32位浮点数
- 每个元素的值:例如全是0,或者随机数
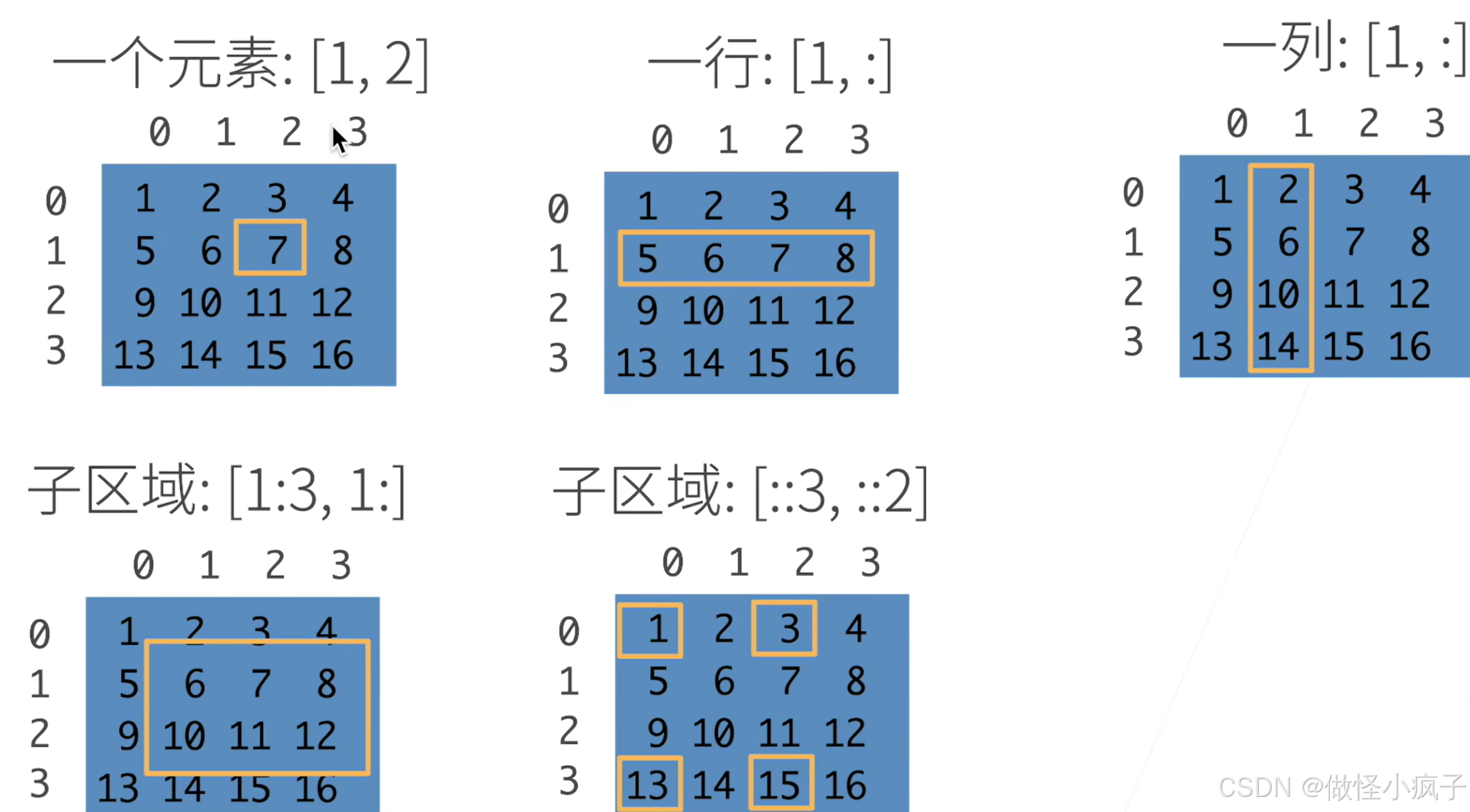
访问元素
- 一个元素:[1, 2]
- 一行:[1, :]
- 一列:[1, :]
- 子区域:[1:3, 1: ] (取到第一行第二行,以及第一列以后的所有元素)
- 子区域:[::3, ::2] (跳着访问,每三行一跳,每两列一跳)
数组相关练习:
1. 张量创建函数:
-
torch.arange(start=0, end, step=1, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False):创建一个从 start 到 end(不包括)的一维张量,步长为 step。- 例如
x = torch.arange(12)创建了一个包含 0 到 11 的一维张量。
- 例如
-
torch.zeros(size, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False):创建一个指定 size 的全零张量。- 例如
torch.zeros((2, 3, 4))创建一个形状为 (2, 3, 4) 的全零张量。
- 例如
-
torch.ones(size, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False):创建一个指定 size 的全一张量。- 例如
torch.ones((2, 3, 4))创建一个形状为 (2, 3, 4) 的全一张量。
- 例如
-
torch.tensor(data, dtype=None, device=None, requires_grad=False, pin_memory=False):从现有的数据(如 Python 列表或嵌套列表)创建张量。- 例如 z = torch.tensor([[2, 1, 3, 4], [1, 2, 3, 4], [4, 3, 1, 2]])。
2. 张量属性和元素信息:
tensor.shape:返回张量的形状- 例如
x.shape可以查看张量 x 的形状。
- 例如
tensor.numel():返回张量中元素的总数。- 例如
x.numel()会返回 x 中元素的数量。
- 例如
tensor.dtype:返回张量的数据类型- 例如,在
x = torch.arange(12, dtype=torch.float32)中使用dtype参数指定了数据类型为 float32。
- 例如,在
3. 张量形状变换函数:
tensor.reshape(*shape):改变张量的形状而不改变元素数量和元素值。- 例如
X = x.reshape(3, 4)将 x 张量重塑为形状为 (3, 4) 的张量。
- 例如
4. 张量的元素级运算:
-
标准算术运算符(+、-、*、/ 和 **):对张量进行元素级的加、减、乘、除和求幂运算。例如 x + y 是元素级相加,x ** y :是求幂。
-
torch.exp(input, out=None):计算张量元素的指数。例如 torch.exp(x) 计算 x 中每个元素的指数。
5. 张量连接函数:
torch.cat(tensors, dim=0):将多个张量在指定维度 dim 上连接在一起。- 例如
torch.cat((x, y), dim=0)是在第 0 维合并 x 和 y 张量,torch.cat((x, y), dim=1)是在第 1 维合并。
- 例如
6. 张量的比较运算:
tensor1 == tensor2:进行元素级的相等比较,返回一个布尔型张量。- 例如
x == y会生成一个与 x 和 y 形状相同的张量,元素表示 x 和 y 对应元素是否相等。
- 例如
7. 张量的元素访问和修改:
tensor[index]:通过索引访问张量元素。- 例如 x[-1] 访问 x 的最后一个元素,x[1:3] 访问 x 的第二行和第三行元素。
tensor[indices] = value:通过索引修改张量元素- 例如
x[1, 2] = 9为 x 中第 2 行第 3 列(下标从0开始)元素赋值为 9,x[0:2, :] = 12为 x 的前两行所有元素赋值为 12,x[0:2, 1:3] = 88为 x 的前两行中第 2 列到第 3 列元素赋值为 88。
- 例如
8. 张量的内存操作:
id(tensor):获取张量的唯一标识符,用于比较张量是否在内存中发生了变化。- 例如
before = id(y)存储 y 的标识符,用于后续检查 y 的内存是否改变。这样赋值y = y + x,会导致开启新的内存,可能造成内存的浪费(实际中要尽量避免这种情况)
- 例如
- 原地操作:使用
x[:] = x + y或x += y来避免额外的内存分配,例如 x += y 直接将 x + y 的结果存储在 x 中,不会重新分配内存。
9. 张量和 numpy 数组的转换:
tensor.numpy():将张量转换为 numpy 数组。- 例如
A = x.numpy()将张量 x 转换为 numpy 数组 A。
- 例如
torch.tensor(array):将 numpy 数组转换为张量。- 例如
B = torch.tensor(A)将 numpy 数组 A 转换为张量 B。
张量和标量的转换:
- 例如
tensor.item():将大小为 1 的张量转换为 Python 标量- 例如
a.item()将张量 a(只有一个元素)转换为 Python 标量,还可以使用 float(a) 或 int(a) 进行相应类型的转换。
- 例如
10. 相关练习代码如下:
import torch
# 张量表示一个数值组成的数组,这个数组可能有多个维度
x = torch.arange(12)
x
# 可以通过张量的shape属性来访问张量的 形状 和 张量中的元素的总数
x.shape
x.numel() # 元素的总数:永远是个标量,这里是12
# 要改变一个张量的形状而不改变元素数量和元素值,可以调用reshape函数
X = x.reshape(3, 4)
X
# 使用全0、全1、其他常量或者从特定分布中随机采样的数字
torch.zeros((2, 3, 4))
torch.ones((2, 3, 4))
# 通过提供包含数值的python列表(或嵌套列表)来为所需张量中的每个元素赋予确定值
z = torch.tensor([[2, 1, 3, 4], [1, 2, 3, 4], [4, 3, 1, 2]])
z.shape
# 常见的标准算术运算符(+、-、*、/和**)都可以被升级为按元素运算
x = torch.tensor([1.0, 2, 4 ,8])
y = torch.tensor([2, 2, 2, 2])
x + y, x - y, x * y, x / y, x**y # ** 是求幂运算
# 按元素方式应用更多的计算
torch.exp(x 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1633
1633

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









