




 ArrayList是基于动态数组的数据结构,适合随机访问但插入和删除较慢;LinkedList是双向链表,适合频繁的插入和删除操作,但访问效率较低。两者在内存占用和线程安全性上有不同特点,且在容量增长策略上,ArrayList会按一定比例扩容。
ArrayList是基于动态数组的数据结构,适合随机访问但插入和删除较慢;LinkedList是双向链表,适合频繁的插入和删除操作,但访问效率较低。两者在内存占用和线程安全性上有不同特点,且在容量增长策略上,ArrayList会按一定比例扩容。
一、ArrayList
1、概述
ArrayList是实现了List接口的动态数组,所谓动态数组就是他的大小是可变的。实现了所有可选列表操作,并允许包括Null在内的所有元素。除了实现 List 接口外,此类还提供一些方法来操作内部用来存储列表的数组的大小。
每个ArrayList实例都有一个容量,该容量是指用来存储列表元素的数组的大小。默认初始容量是10。默认初始容量为10。随着ArrayList中元素的增加,它的容量也会不断的自动增长。在每次添加元素时,ArrayList都会检查是否需要进行扩容操作,扩容操作带来数据向新数组的重新拷贝,所以如果我们知道具体业务数据量,在构造ArrayList时,可以给ArrayList 指定一个初始容量,这样就会减少扩容时的拷贝问题。当然在添加大量元素前,应用程序也可以使用ensureCapacity操作来增加ArrayList实例的容量,这可以减少递增式再分配的数量。
2、源码分析
ArrayList是实现List接口的,底层采用数组实现,所以它的操作基本上都是基于对数组的操作。
2.1、构造函数
- ArrayList():默认构造函数,提供初始容量为10的空列表。
- ArrayList(int initialCapacity):构造一个具有指定初始容量的空列表。
- ArrayList(Collection<? extends E> c):构造一个包含指定 collection 的元素的列表,这些元素是按照该 collection的迭代器返回它们的顺序排列的。
/**
* 构造一个具有指定初始容量的空列表。
*/
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
/**
* 构造一个初始容量为 10 的空列表
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA; //不会立刻创建数组,会在第一次add()时才会创建
}
/**
* 构造一个包含指定 collection 的元素的列表,这些元素是按照该 collection
* 的迭代器返回它们的顺序排列的。
*/
public ArrayList(Collection<? extends E> c) {
Object[] a = c.toArray();
if ((size = a.length) != 0) {
if (c.getClass() == ArrayList.class) {
elementData = a;
} else {
elementData = Arrays.copyOf(a, size, Object[].class);
}
} else {
// replace with empty array.
elementData = EMPTY_ELEMENTDATA;
}
}
2.2、常用方法
ArrayList提供了add(E e)、add(int index, E element)、addAll(Collection<? extends E> c)、addAll(int index, Collection<? extends E> c)、set(int index, E element)这个五个方法来实现ArrayList增加。
- add():单个插入数据
public boolean add(E e) {
ensureCapacityInternal(size + 1); // 验证是否需要扩容
elementData[size++] = e; //往数组最后的位置赋值
return true;
}
public void add(int index, E element) {
rangeCheckForAdd(index); //判断索引位置是否正确
ensureCapacityInternal(size + 1); // 验证是否需要扩容
/*
* 对源数组进行复制处理(位移),从index + 1到size-index。
* 主要目的就是空出index位置供数据插入,
* 即向右移动当前位于该位置的元素以及所有后续元素。
*/
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
//给指定下标的位置赋值
elementData[index] = element;
size++;
}
在这个方法中最根本的方法就是System.arraycopy()方法,该方法的根本目的就是将index位置空出来以供新数据插入,这里需要进行数组数据的右移,这是非常麻烦和耗时的,所以一般不建议使用该方式添加元素。如果需要向指定中间位置进行大量插入(中间插入)操作,推荐使用LinkedList。
- addAll():批量插入数据
public boolean addAll(Collection<? extends E> c) {
Object[] a = c.toArray(); //将集合c 转换成数组
int numNew = a.length;
ensureCapacityInternal(size + numNew); // 扩容(当前集合长度+c集合长度)
//同上,主要是采用该方法把C集合转为数组后的数据进行复制在插入到当前集合的末尾
System.arraycopy(a, 0, elementData, size, numNew);
size += numNew;
return numNew != 0;
}
public boolean addAll(int index, Collection<? extends E> c) {
rangeCheckForAdd(index); //判断下标位置是否正确
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacityInternal(size + numNew); // 扩容(当前集合长度+c集合长度)
int numMoved = size - index;
// 如果位置不是集合尾部,则需要先把数据向右移动指定长度(添加数据的长度)
if (numMoved > 0)
System.arraycopy(elementData, index, elementData, index + numNew,
numMoved);
// 然后再把数据加入到指定下标位置
System.arraycopy(a, 0, elementData, index, numNew);
size += numNew;
return numNew != 0;
}
这个方法无非就是使用System.arraycopy()方法将C集合(先准换为数组)里面的数据复制到elementData数组中。这里就稍微介绍下System.arraycopy(),因为下面还将大量用到该方法。
该方法的原型为:public static void arraycopy(Object src, int srcPos, Object dest, int destPos, int length)。它的根本目的就是进行数组元素的复制。
即从指定源数组中复制一个数组,复制从指定的位置开始,到目标数组的指定位置结束。将源数组src从srcPos位置开始复制到dest数组中,复制长度为length,数据从dest的destPos位置开始粘贴。
- get():查找指定下标的元素
public E get(int index) {
rangeCheck(index);
checkForComodification();
return ArrayList.this.elementData(offset + index);
}
ArrayList提供了get(int index)用读取ArrayList中的元素。由于ArrayList是动态数组,所以我们完全可以根据下标来获取ArrayList中的元素,所以他的时间复杂度是O(1);存/取的速度是还是比较快的。但如果是查找,插入和删除元素效率就不会太高,因为他们需要去一个一个遍历出结果来进行对比。所以时间复杂度会为O(n)。
2.3、扩容
在上面的新增方法的源码中我们发现每个方法中都存在这个方法:ensureCapacity(),该方法就是ArrayList的扩容方法。在前面就提过ArrayList每次新增元素时都会需要进行容量检测判断,若新增元素后元素的个数会超过ArrayList的容量,就会进行扩容操作来满足新增元素的需求。
所以如果当我们清楚知道业务数据量或者需要插入大量元素前,我们可以使用再创建集合时直接指定容量大小,或者通过ensureCapacity来手动增加ArrayList实例的容量,以减少递增式再分配的数量。
- 源码实现:
//minCapacity :所需的最小容量
private void grow(int minCapacity) {
// 集合长度
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1); //增加原来的1.5倍
// 判断所需要的最小容量大于增加原来的1.5倍的长度,则容量扩大为minCapacity
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0) //判断是否会大于虚拟机的最大容量
newCapacity = hugeCapacity(minCapacity);
// 拷贝数组
elementData = Arrays.copyOf(elementData, newCapacity);
}
扩容逻辑为:
- 调用无参ArrayList()时,初始容量是0;调用有参时,会是你给的参数大小;调用集合会是集合的大小
- 当添加元素时就会进行扩容,会扩容一个10个容量的数组,当集合元素到10个时,会进行第二次扩容,第二次扩容会扩容到上一个数组长度的1.5倍(底层逻辑为:15>>1=7+15=22)先右移移位在加上原来的数组长度,
二、LinkedList
1、概述
Linkedlist基于链表的动态数组(双向链表):
- 可以被当作堆栈(后进先出)、队列(先进先出)或双端队列进行操作。
- 数据添加删除效率高,只需要改变指针指向即可,但是访问数据的平均效率低,需要对链表进行遍历。 非同步,线程不安全。
- 支持null元素、有顺序、元素可以重复
- 不要使用普通for循环去遍历LinkedList,使用迭代器或者foreach循环(foreach循环的原理就是迭代器)去遍历LinkedList即可:
- 这种方式是直接按照地址去找数据的,将会大大提升遍历LinkedList的效率。
2、单向链表和双向链表
2.1、单向链表
- 链表的每个元素称之为结点(Node)
- 物理存储单元上,非连续、非顺序的存储结构
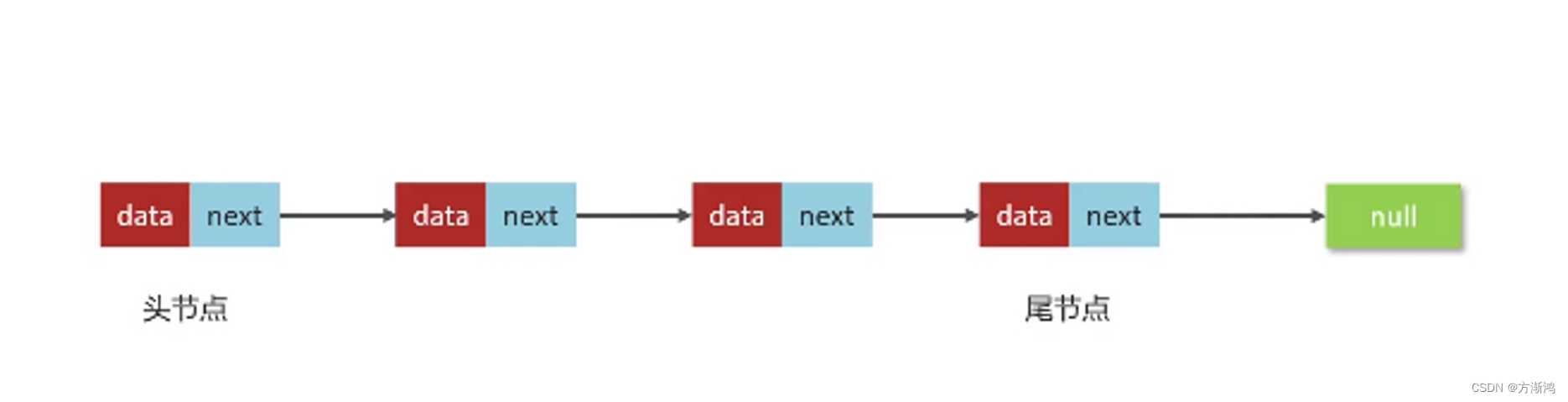
data:数据域,存储数据
next:指针域,指向下一个结点的存储位置
时间复杂度分析:
查询操作
- 只有在查询头结点的时候不需要遍历链表,时间复杂度是O(1);
- 查询其他结点需要遍历链表,时间复杂度是O(n);
新增和删除时间复杂度
- 只有在添加和删除头节点的时候不需要遍历链表,时间复杂度是O(1);
- 添加或删除其他节点需要遍历链表找到对应节点后,才能完成新增或删除节点,时间复杂度是O(n);
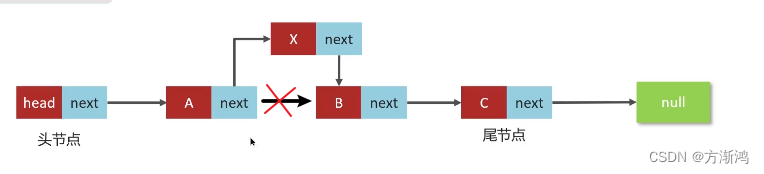
2.2、双向链表
而双向链表,顾名思义,就是支持两个方向:
- 每个结点不止有一个后续指针next指向后面的结点
- 有一个前驱指针prev指向前面的结点

当需要获取前一个结点时,只需要调用prev就行,调取后一个结点则只需要调用next指针就行
对比单向链表 :
- 双向链表需要额外的两个空间来存储后续结点和前驱节点的地址
- 支持双向遍历,这样使得双向链表操作更加灵活
时间复杂度分析:
查询:
- 查询头尾结点的时间复杂度是O(1)
- 平均的查询时间复杂度是O(n)
- 给定结点找前驱结点的时间复杂度为O(1);
增删:
- 头尾结点增删的时间复杂度是O(1)
- 其他部分结点的增删时间复杂度是O(n)
- 给定结点增删的时间复杂度为O(1);
三、ArrayList和LinkedList的区别
1、底层数据存储结构对比

- ArrayList是基于动态数组的数据结构,存储为连续内存
- LinkedList是基于双向链表的数据结构,内存存储上是非连续的
2、操作数据效率:
- 查找:查找对比ArrayList因为底层是基于数组连续性的,实现了一个叫RandomAccess的接口,使得在查找时,会依据下标通过寻址公式进行查找;而LinkedList底层是双向链表,就没有实现该接口,在查找元素时,就只能采用next()迭代器一个一个去迭代寻找
- 增删:ArrayList尾部插入性能较快,而其他部分插入性能就会比较慢,因为在前面的位置插入时,每个数组元素都要向后移动移位;而LinkedList因为是链表结构头部、尾部插入删除时,不需要查找定位,删除添加时不牵扯其他元素,只需要修改指针指向就行,所有较快,但如果是中间元素的删除修改时,需要先定位到要修改的元素的位置,而定位比较耗费时间,所有性能相当于来说会更慢。
- 但如果查找的是未知索引,则ArrayList也需要遍历,时间复杂度上就都会是O(n)
3、内存空间占用:
- ArrayList底层因为是数组,内存连续,节省内存
- LinkedList是双向链表需要存储数据和两个指针,更占内存
- 而且ArrayList可以利用cpu缓冲的局部性原理,所有在进行加载时会一次性加载相邻的元素,到cpu的缓冲里面,内存读取就可以先到cpu缓冲里去读取,这样可以有效的提高执行效率,而LinkedList是链表型的,元素之间只是用指针指向,不一定会相邻,所以没法有效的利用该特性
4、线程安全:
- ArrayList和LinkedList都不是线程安全
- 如果需要实现线程安全可以通过Collections.synchronizedList()进行包裹创建
- Collections.synchronizedList(new LinkedList<>())
- Collections.synchronizedList(new ArrayList<>())


















 952
952

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









