




kettle篇: 增量更新
- 为什么要使用增量更新呢?想象一下,巨量数据中,每天变化的只是其中一小部分。如果每次都全量更新,那无疑是对时间和资源的极大浪费。
增量更新可以做到聪明地只处理那些发生变化的数据,确保我们既能保持数据的时效性,又不必为不必要的操作买单。
- 场景描述
有两张数据表,tablea(源表),tableb(目标表),存在不同的数据库中,现需要使用kettle作为ETL工具,将tablea里的数据抽取到tableb里。
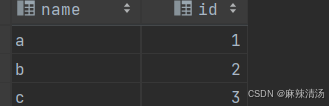
tablea:
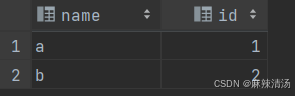
tableb:
一、 建立作业和转换
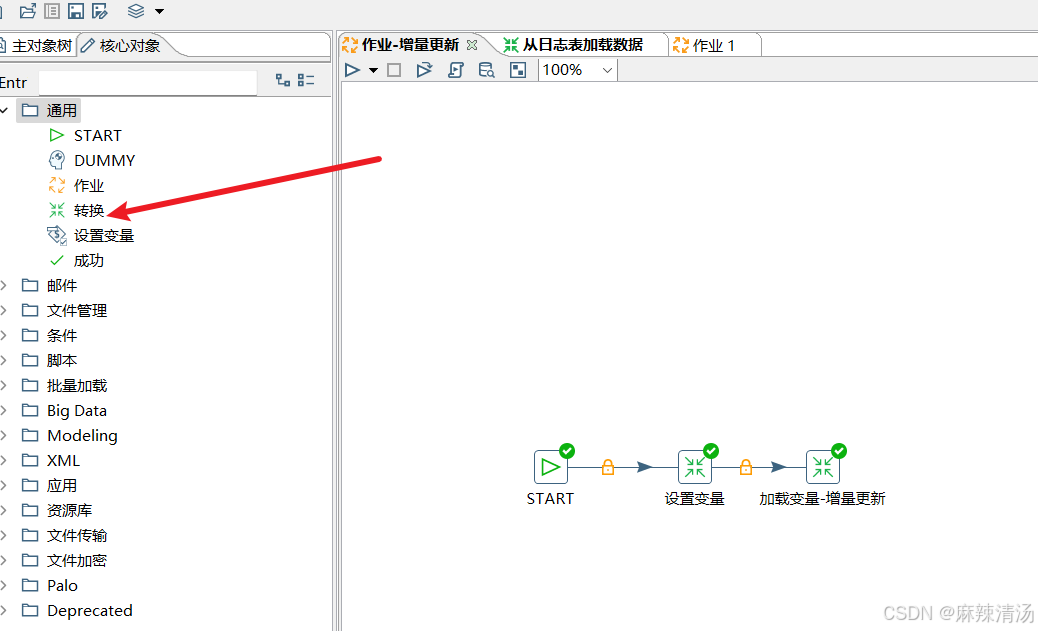
二、 转换1:设置变量
增量更新的逻辑:获取tableb的最大id,sql获取tablea中大于这个id的行进行插入更新。
- 在设置变量的转换中添加表输入对象]
- 设置好数据库连接
- sql获取tableb的最大id
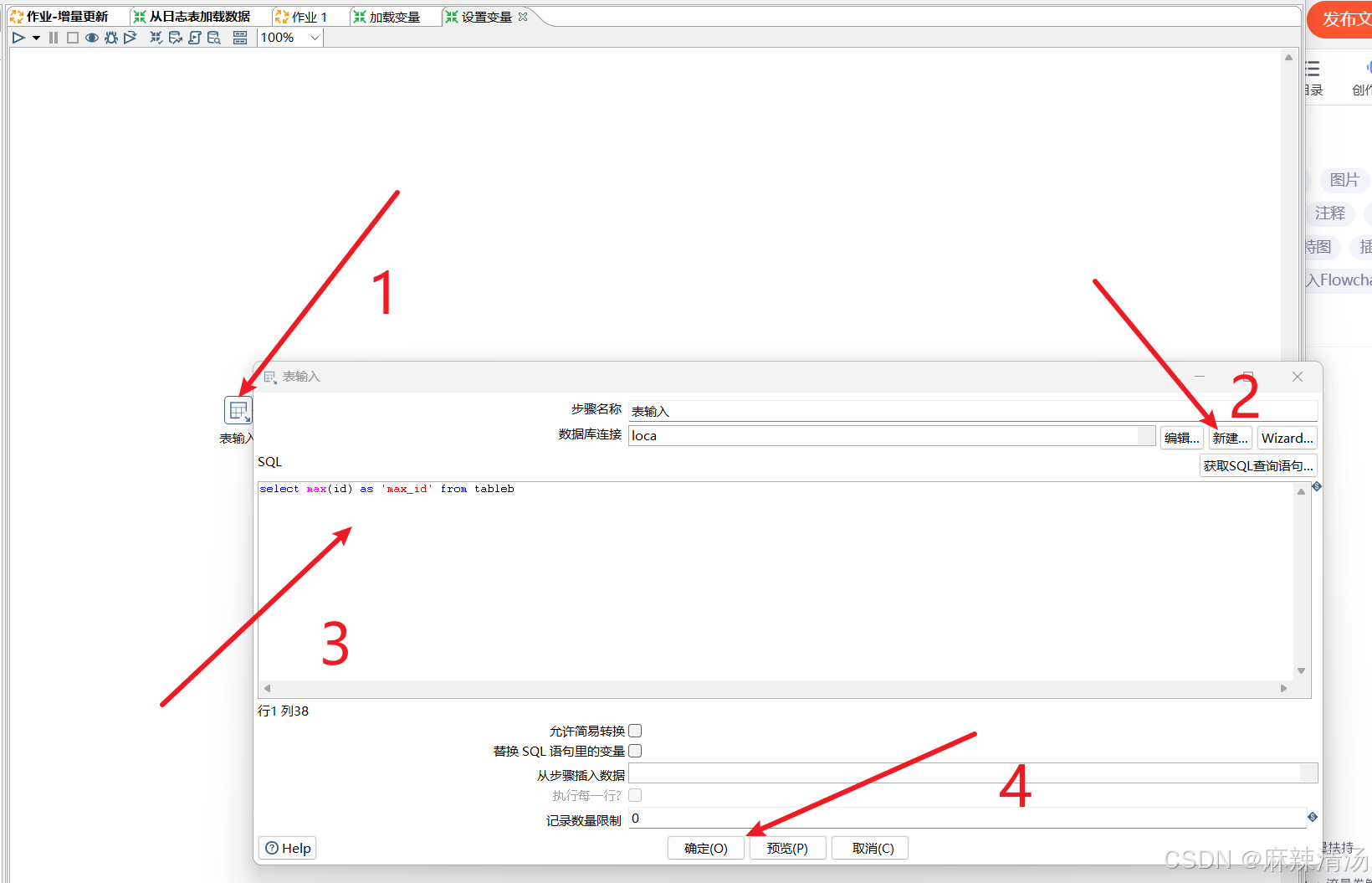
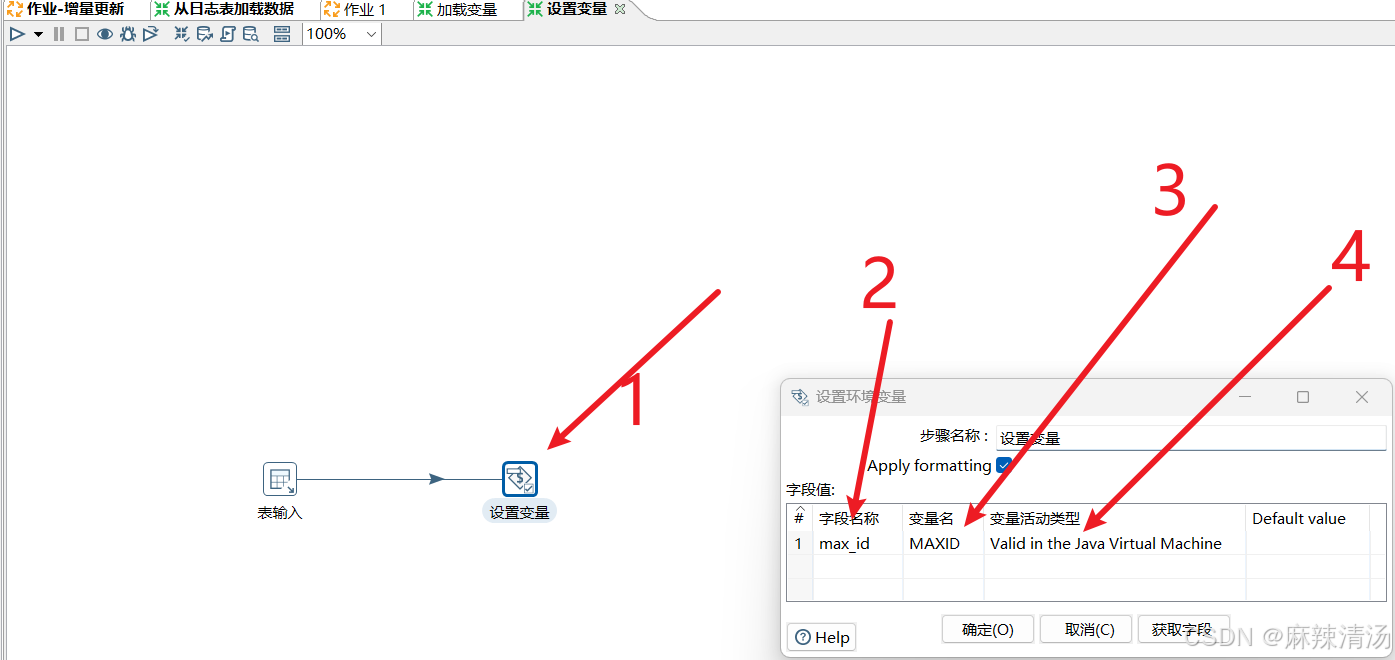
1- 添加设置变量组件
2- 字段名称里填写前面表输入的字段名
3- 变量自定义为MAXID
4- 最后设置变量活动类型为整个环境
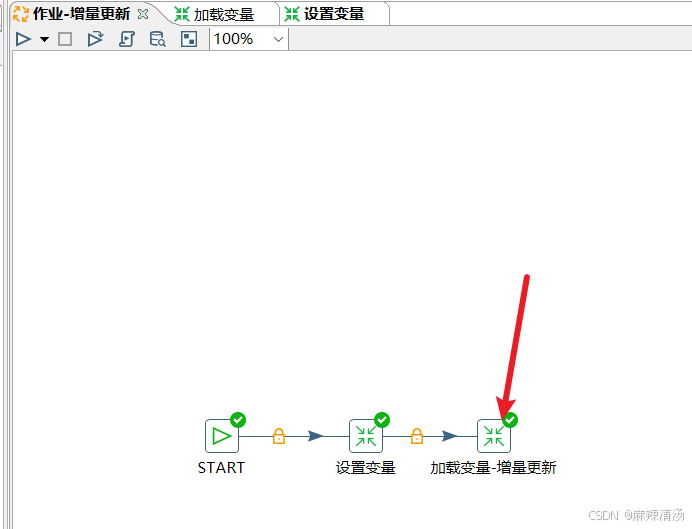
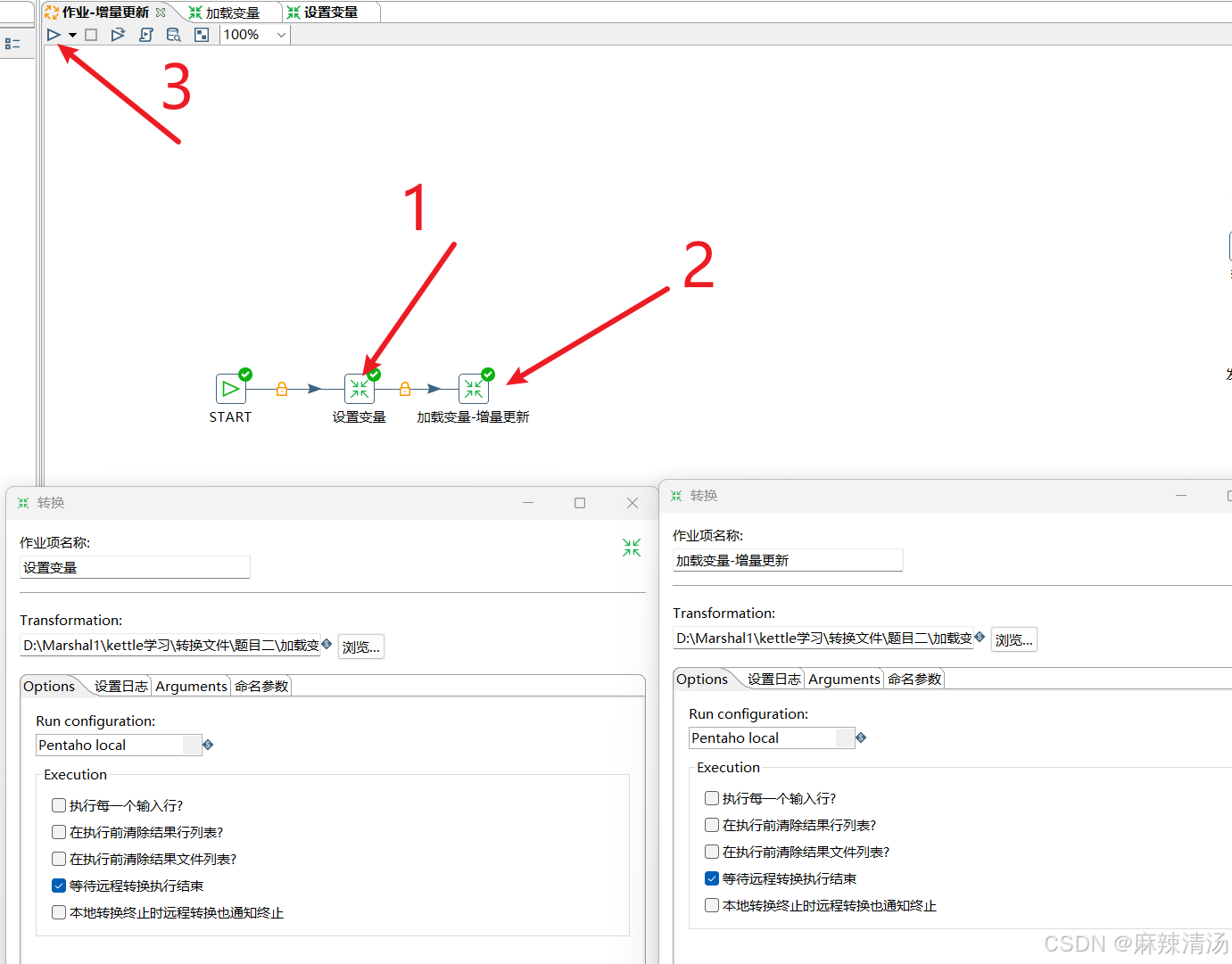
三、加载变量并更新
进入到加载变量的转换中
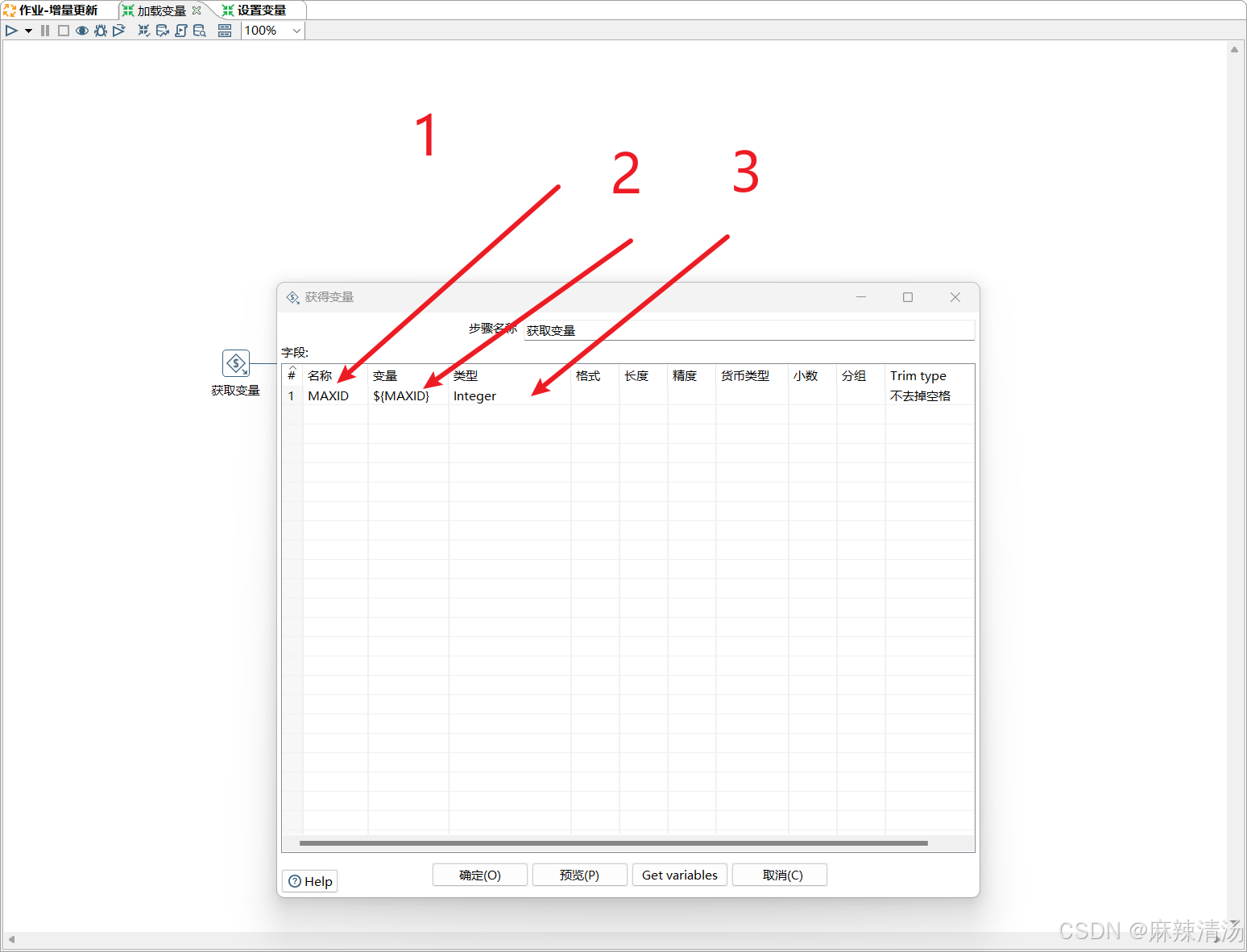
- 添加获取变量组件
- 填写变量名称,这里名称要和之前设置变量时一致
- 变量栏目下添加${变量名}, 设置好类型点击确定
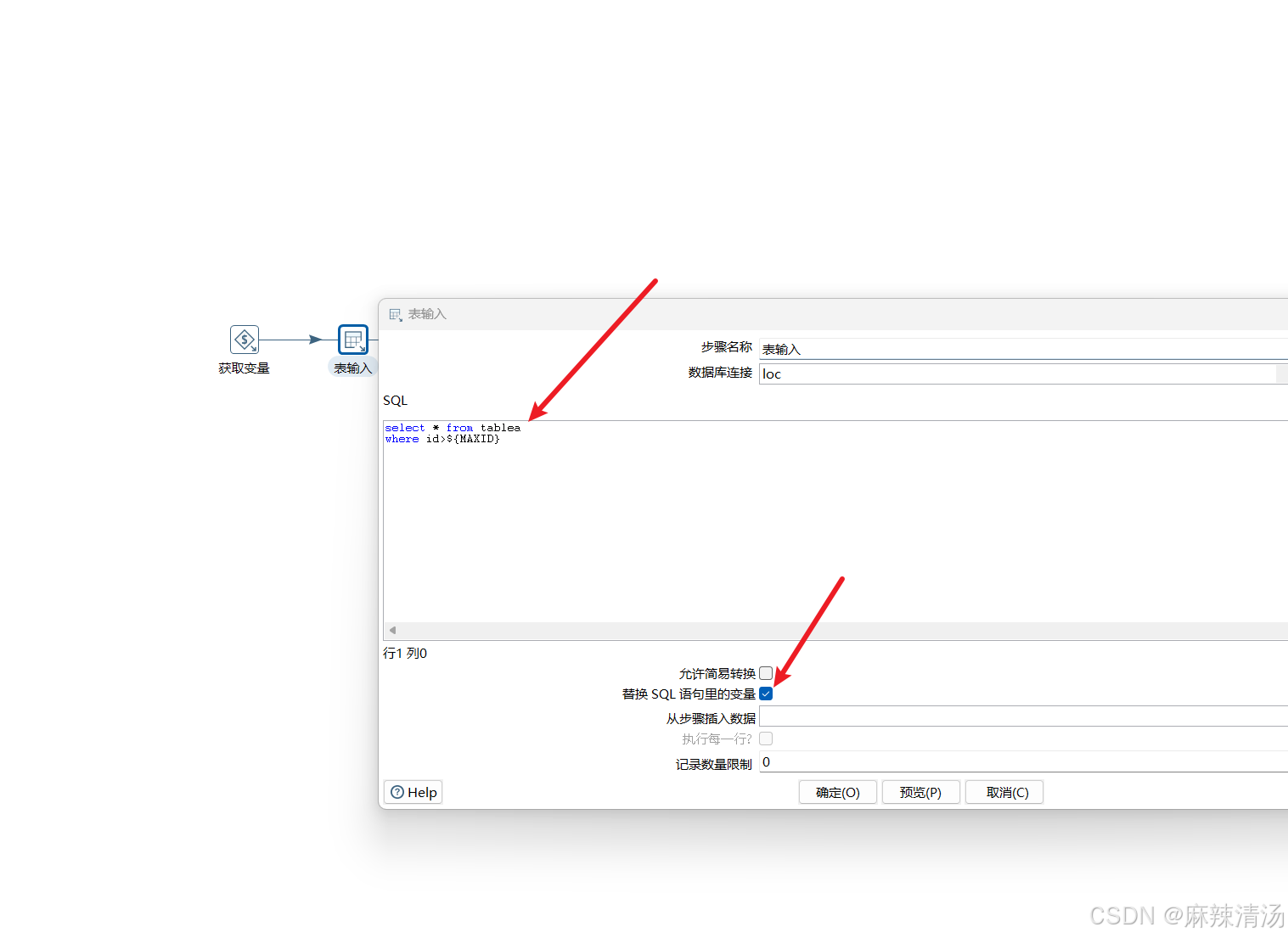
- 这里添加表输入,获取表a的数据,通过id>${MAXID} 来获取需要插入/更新的行
- 下面再点击 《替换SQL语句里的变量》!!
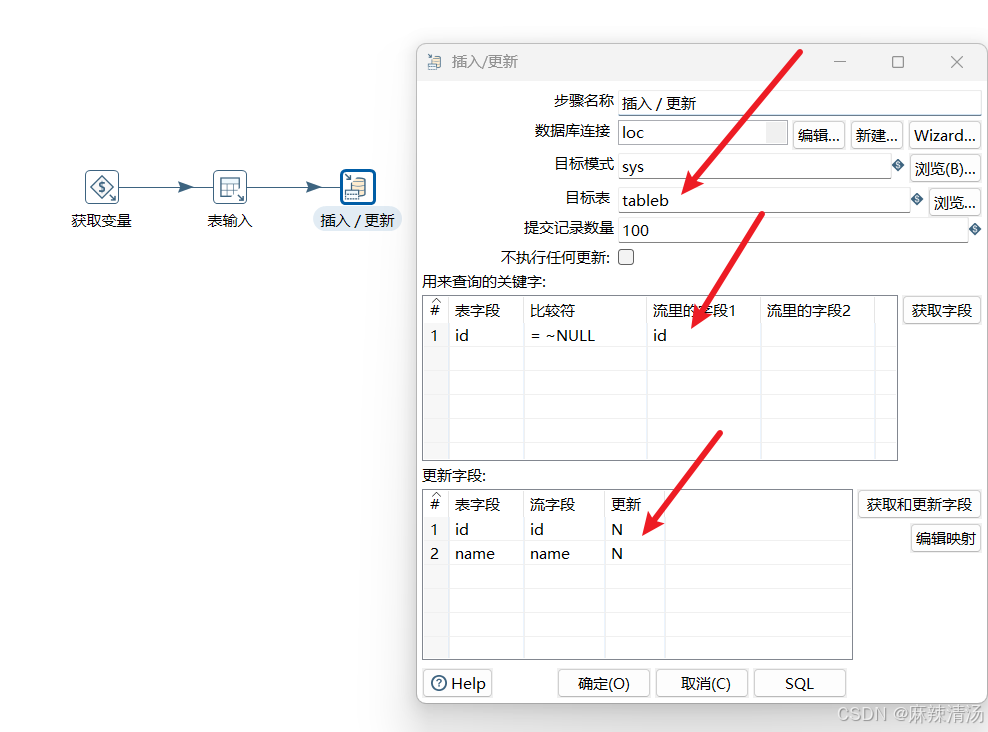
- 添加插入/更新组件,向tableb插入数据
- 通过id=id来判断是否需要更新
- 然后选择更新的字段,这里id、name都更新。然后确定
四、 执行作业
- 双击设置变量和加载变量转换,并且放入对应的转换之后,点击三角形,执行作业


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









