




BOSS直聘岗位python爬取
引用上篇对boss直聘每个岗位的源代码获取了之后,对字段的爬取
前言:https://blog.youkuaiyun.com/weixin_52001949/article/details/135452969
如有问题可私信关注博主
- 工具:Python
- 库文件:BeautifulSoup
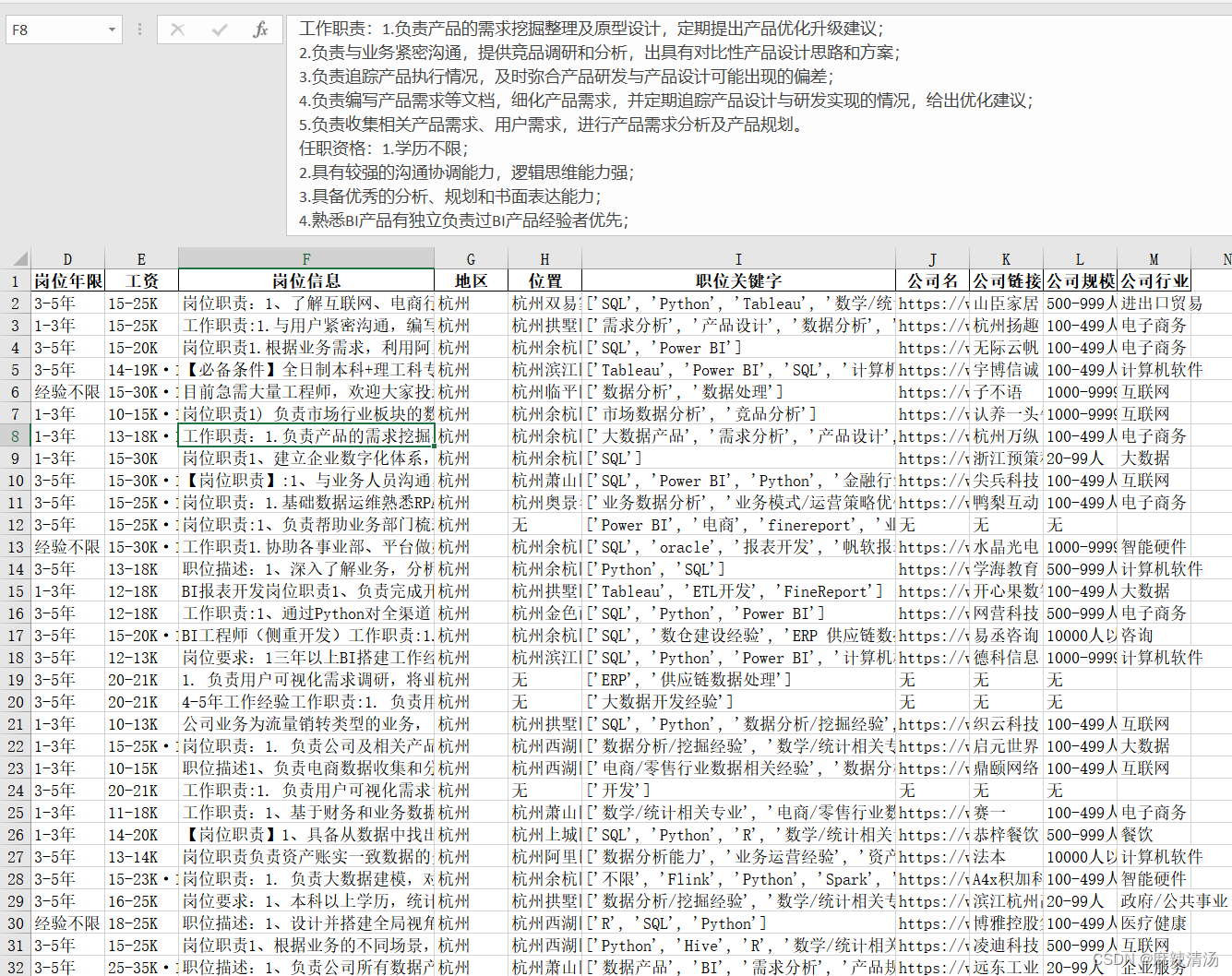
1. 需要获取的字段
岗位名、岗位薪资、地区、工作地址、要求年限、学历、职位描述、岗位职责
公司名、公司规模、公司介绍、公司成立日期、行业
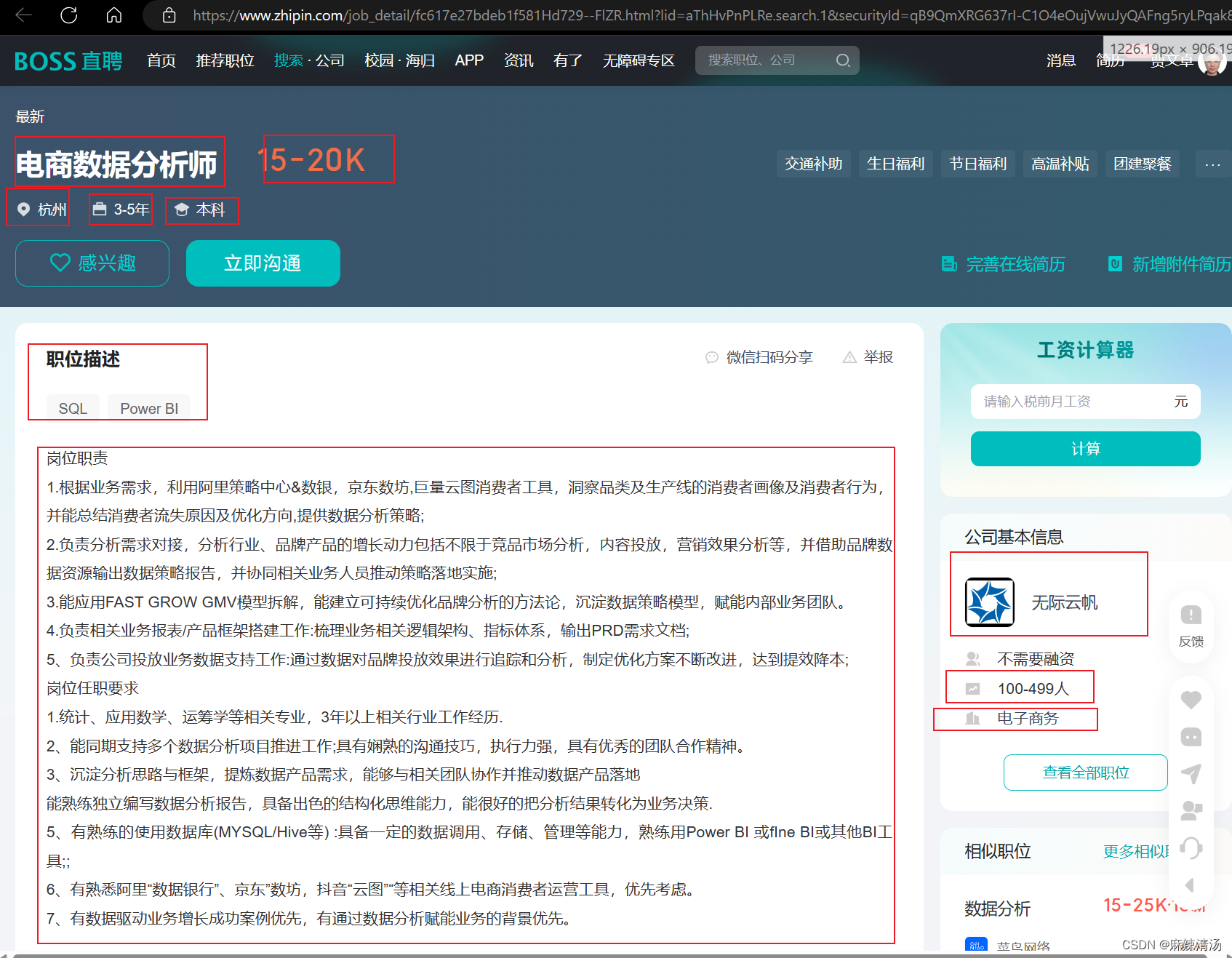
2 .利用beatifulsoup进行解析
将每个字段的信息放在一个列表里,每个岗位一个列表,
岗位=[‘bi1’,‘bi2’,…] ,公司名=[‘a’,‘b’,‘c’,…]
最后用pandas中的Pandas中的DataFrame做成表格输出excel。
- 示例爬取
1. 关键字爬取
思路:
- 定位class,用find_all 获取该ul下的所有li
- 遍历所有li,获取li内的字符串
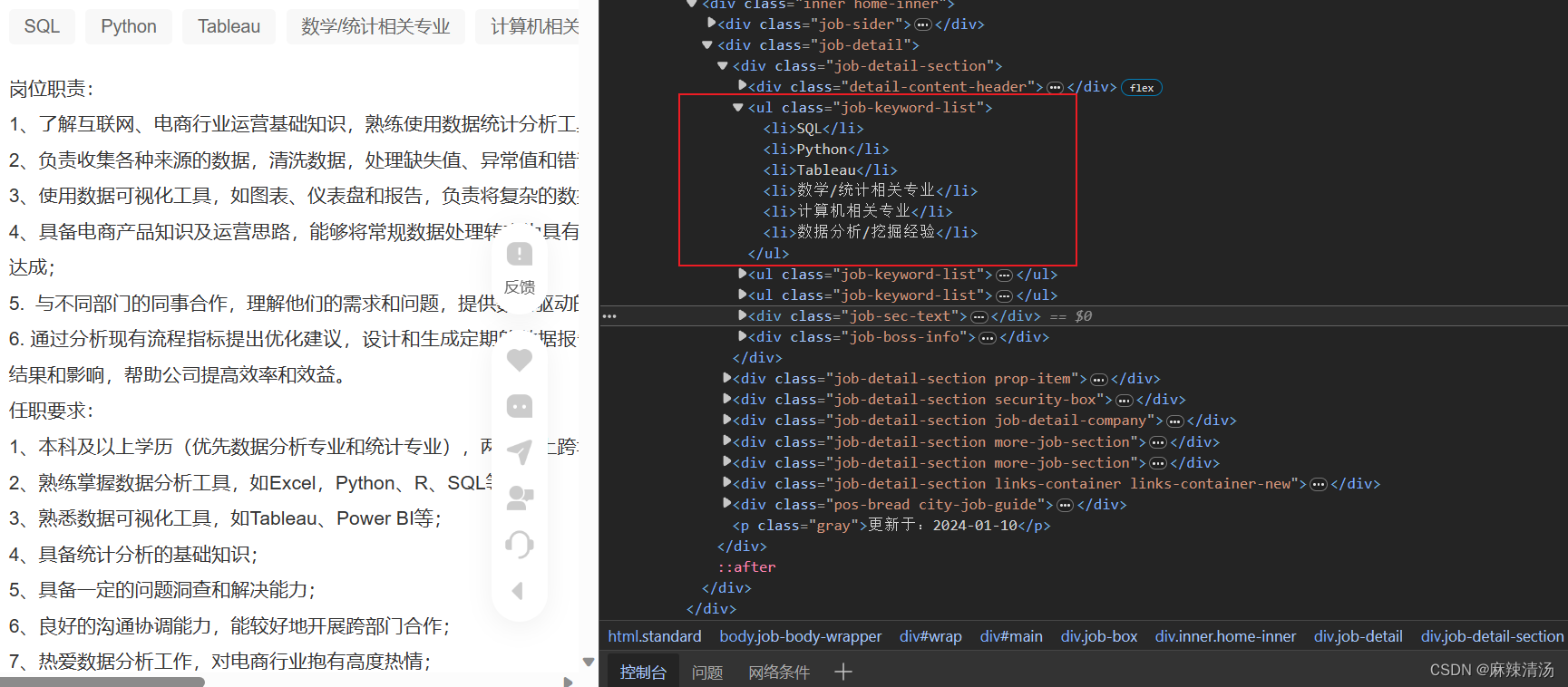
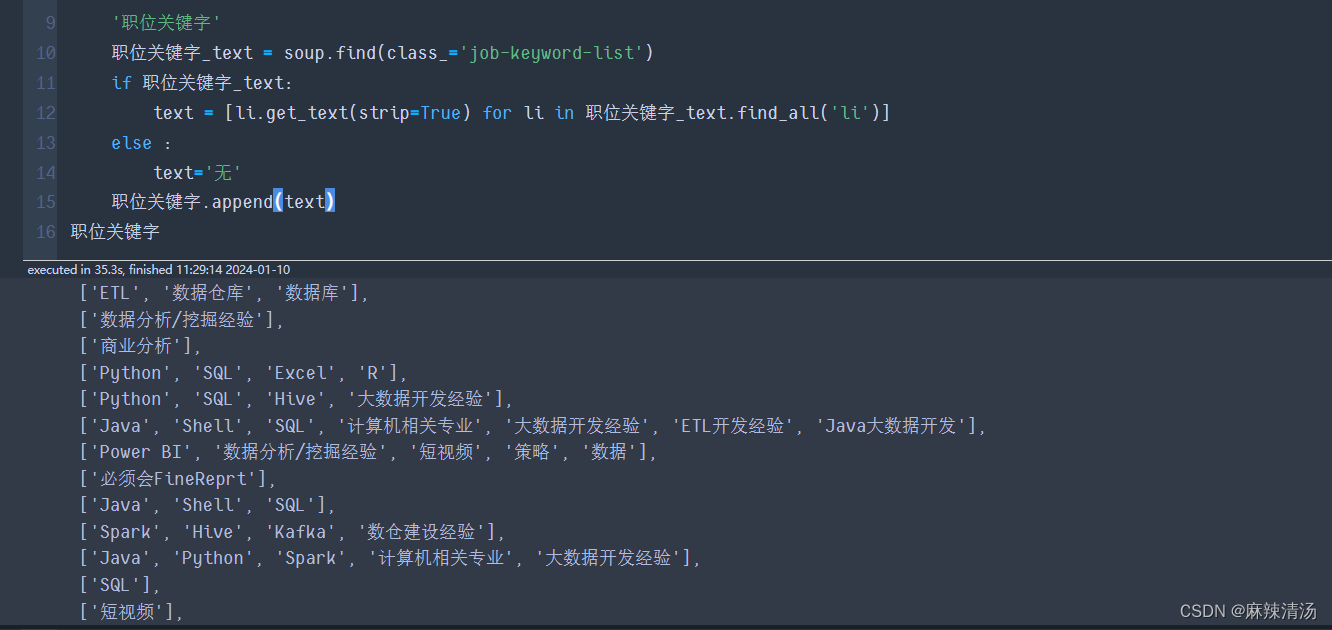
'职位关键字'
职位关键字_text = soup.find(class_='job-keyword-list')
'如果找不到的话该class,报错'
if 职位关键字_text:
text = [li.get_text(strip=True) for li in 职位关键字_text.find_all('li')]
else :
text='无'
职位关键字.append(text)
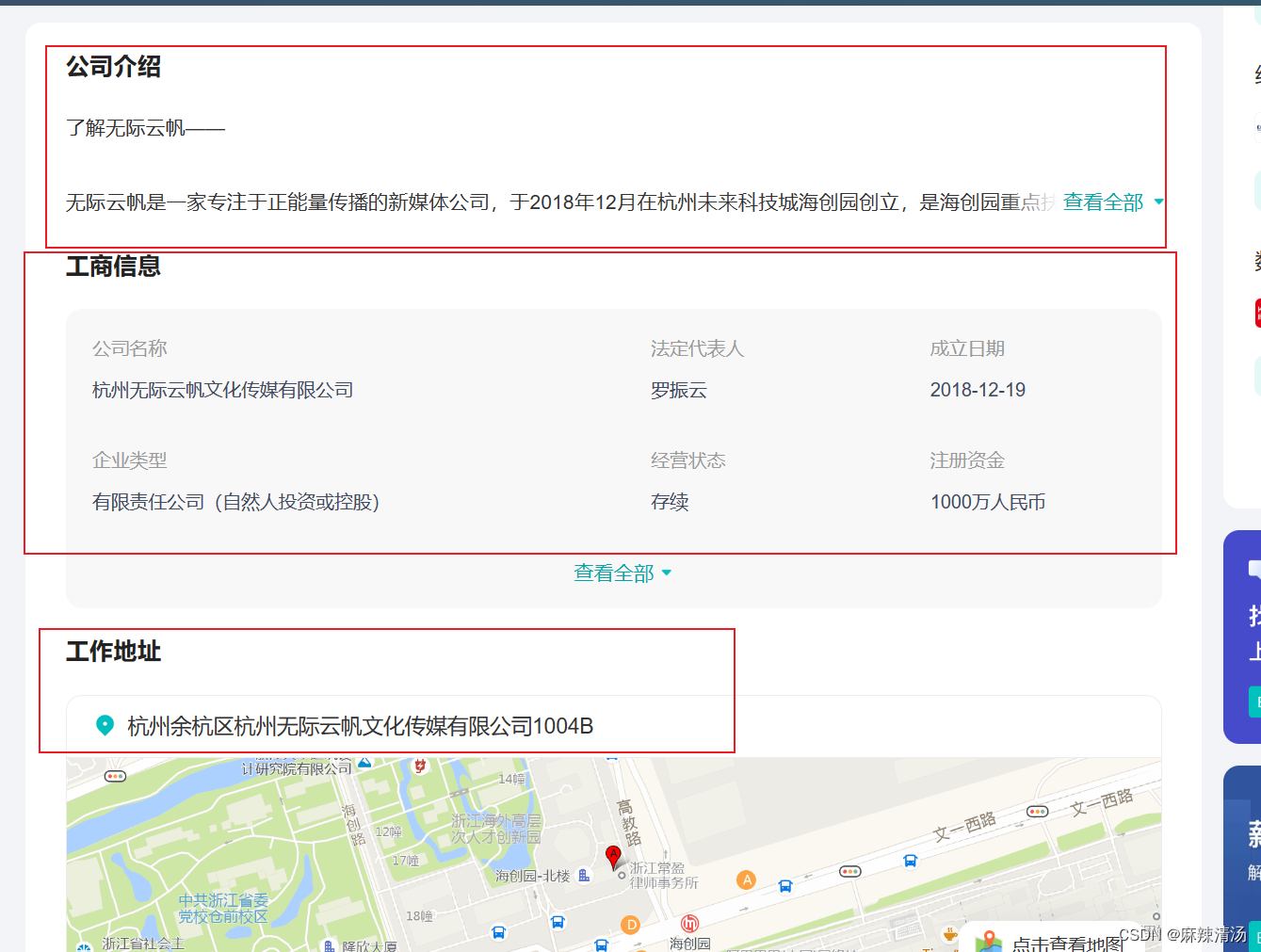
2. 公司信息字段
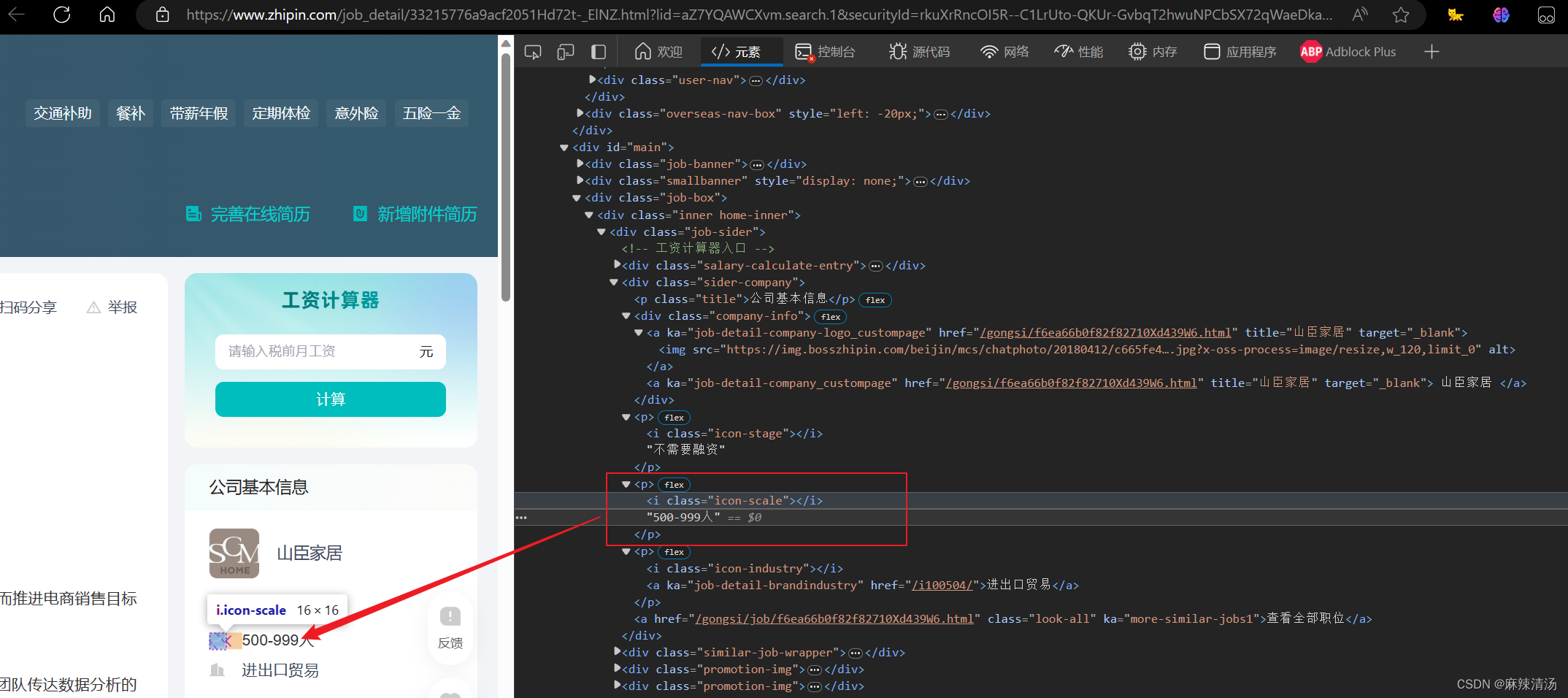
- 字段内容在p标签内,标签内含有一个 的标签。
- 获取思路:找到包含i标签中class=‘icon-scale’ 的p标签
select 方法返回的是一个列表,包含所有匹配的元素。如果没有找到匹配的元素,它会返回一个空列表。要注意的是,select 方法总是返回一个列表,即使只有一个元素匹配。如果你只对第一个匹配的元素感兴趣,可以使用 select_one 方法,它返回单个元素而不是列表。
- soup.select_one:
- 包含选择器: 选择包含类名为 .icon-scale 的 标签的
标签。返回的是一个元素。
soup.select("p:has(i.icon-scale)")
示例代码:
公司规模=[]
公司规模_text = soup.select_one('p:has(i.icon-scale)')
if 公司规模_text:
text=公司规模_text.get_text(strip=True)
公司规模.append(text)
公司行业字段获取
同理找到class为icon-industry

公司行业_text = soup.select_one('p:has(i.icon-industry)')
if 公司行业_text:
text=公司行业_text.get_text(strip=True)
公司行业.append(text)
完整代码扫码获得


















 2713
2713

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









