






今天来总结一下机器学习中的一些零零散散的知识。
坐标:北京
天气:晴 伴有微风
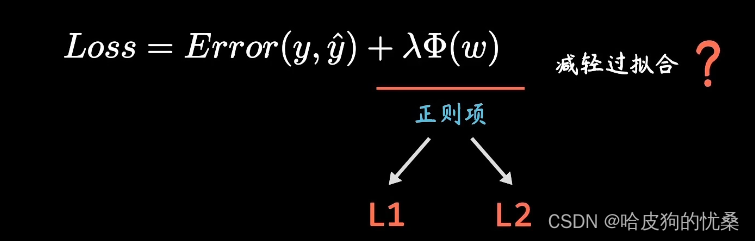
正则化(regularization):
机器学习中经常会在损失函数中加入正则项(或者惩罚项),称之为正则化(Regularize)。
目的:防止模型过拟合
原理:在损失函数上加上某些规则(限制),缩小解空间,从而减少求出过拟合解的可能性
我们在模型的损失函数中加入正则项可以得到目标函数。其中λ被称为正则化系数,当λ越大时,正则化约束越强。
 极大似然估计:
极大似然估计:
①利用已知的样本信息,反推一个模型,模型的参数会使得这些样本出现的概率最大。
②极大似然估计只是求模型参数的方法
举个栗子:
某个箱子中有6个蓝色球和3个黄色球。现在闭眼取出5个球,分别是3个蓝色球和2个黄球。那么请你估计一下这个箱子中蓝球和黄球的比例是多少?
你肯定会猜3:2对吧?
如果用极大似然估计的方法去求解:
设箱子中蓝球的比例为p,即从箱子中取到蓝球的概率为p,取到黄球的概率为1-p

整理后似然函数为:(1-
)
之后求导求极大似然函数最大值就行了
过拟合
泛化误差:机器学习方法训练出来一个模型,希望它不仅仅是对于已知的数据(训练数据)性能表现良好,对于未知的数据(测试数据)也应该表现良好,也就是具有良好的generalization能力,这就是泛化能力。测试数据的误差,也被称为泛化误差。
什么叫过拟合呢?“拟合”表示的是模型对数据的学习程度,在新的样本上回归误差或分类错误越少的模型,“拟合”程度越好。如果把历史数据叫做“训练样本”,把新的拿来预测的样本数据叫做“测试样本”,那么“训练误差”很小,而“测试误差”很大,就叫“过拟合(overfitting)",这是我们不希望得到的结果;
如何避免过拟合?
①过拟合说明数据不够用,太少了,我们可以增加样本数据,如果还能获取更多数据当然更好,但是一般数据已经是固定的了,所以可以对原有数据进行处理,比如上采样、数据增强等等,让数据看似“增多”。
②过拟合说明我把全部样本数据信息都学到了,那如果我在训练模型过程中,每次迭代不用全部样本,而是部分样本,所以深度学习里的“Dropout”方法就是这种原理,在模型训练过程中,随机的丢弃掉一部分样本,这部分样本不参与参数更新。还有卷积神经网络中的池化层也有此作用。
③我们使用的是原始数据去训练模型,如果适当地对特征进行一些处理,人为地改变数据,丢弃掉个别数据的偶然性提取共性,是不是也可以达到防止过拟合的效果。比如归一化(标准化)、离散化(分箱),LightGBM模型优异的性能就是采用的直方图分箱的方式,既提高了计算效率,又防止过拟合。
④采用单个模型可能存在过拟合,如果将多个模型进行集成融合就可以取长补短,在某种程度上降低了过拟合。
所以对于初学者来说,当你遇到以上这些操作的时候要明白它们的目的是什么,不然就会摸不着头脑。
损失函数
一、损失函数是什么
损失函数(Loss Function)是机器学习和深度学习中的一个重要概念,用于衡量模型预测结果与真实结果之间的差异或误差。它是一个数值评估指标,通过对模型输出和真实标签之间的比较,提供了对模型性能的度量。
二、损失函数的作用和使用场景
1.作用
(1)衡量模型性能:损失函数用于评估模型的预测结果与真实结果之间的误差程度。较小的损失值表示模型的预测结果与真实结果更接近,反之则表示误差较大。因此,损失函数提供了一种度量模型性能的方式。
(2)参数优化:在训练机器学习和深度学习模型时,损失函数被用作优化算法的目标函数。通过最小化损失函数,可以调整模型的参数,使模型能够更好地逼近真实结果。
(3)反向传播:在深度学习中,通过反向传播算法计算损失函数对模型参数的梯度。这些梯度被用于参数更新,以便优化模型。损失函数在反向传播中扮演着重要的角色,指导参数的调整方向。
(4)模型选择和比较:不同的损失函数适用于不同类型的问题和模型。通过选择合适的损失函数,可以根据问题的特性来优化模型的性能,并对不同模型进行比较和选择。
因此,损失函数在机器学习和深度学习中起到了衡量模型性能、指导参数优化和模型选择的重要作用。它是模型训练和评估的核心组成部分。
2.使用场景
损失函数的使用场景包括但不限于以下几个方面:
(1)模型训练:在机器学习和深度学习中,损失函数被用于指导模型的训练过程。通过最小化损失函数,可以调整模型的参数,使其能够更好地拟合训练数据,提高模型的性能。
(2)模型评估:损失函数用于评估模型在训练数据以外的数据上的性能。通过计算模型在验证集或测试集上的损失值,可以判断模型的泛化能力和预测准确度。较小的损失值通常表示模型更好地适应了新数据。
(3)优化算法:损失函数在优化算法中起到了重要作用,特别是在梯度下降等基于梯度的优化算法中。通过计算损失函数对模型参数的梯度,可以确定参数的更新方向和步长,以便优化模型。
(4)模型选择和比较:不同类型的问题和模型可能适用于不同的损失函数。根据问题的特性和需求,选择合适的损失函数可以帮助优化模型性能,并对不同模型进行比较和选择。
需要注意的是,选择适当的损失函数取决于问题的性质和所需的模型行为。不同的损失函数对模型的训练和性能产生不同的影响,因此需要根据具体情况进行选择和调整。
三、损失函数的特点
损失函数具有以下几个特点:
(1)衡量模型性能:损失函数用于衡量模型的预测结果与真实结果之间的差异或误差。它提供了对模型性能的度量,通过损失值的大小可以判断模型的拟合能力和预测准确度。
(2)反映目标:损失函数的设计应该与问题的目标密切相关。例如,对于回归问题,常用的均方误差损失函数关注预测值与真实值的平方差;而对于分类问题,交叉熵损失函数则关注预测结果的概率分布与真实标签之间的差异。
(3)可微性:在深度学习中,损失函数的可微性对于使用梯度下降等基于梯度的优化算法至关重要。可微性意味着可以计算损失函数对模型参数的导数,从而进行参数更新和优化。
(4)凸性:对于优化问题,具有凸性的损失函数通常更容易求解。凸性意味着损失函数的局部最小值也是全局最小值,从而使优化算法更有可能收敛到全局最优解。
(5)鲁棒性:损失函数应该对异常值或噪声具有一定的鲁棒性。一些损失函数,例如Huber损失,对于离群点的影响相对较小,从而能够更稳健地适应数据中的异常情况。
(6)可解释性:有些损失函数具有良好的可解释性,可以提供有关模型性能的直观理解。例如,对于分类问题,交叉熵损失函数可以解释为最小化模型对真实类别的不确定性。
需要根据具体的问题和需求选择合适的损失函数,以达到对模型性能的有效评估和优化。不同的损失函数可能适用于不同的情况,因此在实践中需要进行权衡和选择。
四、常见的损失函数
(1)均方误差(Mean Squared Error,MSE):用于回归问题,计算预测值与真实值之间的平均平方差。
(2)交叉熵损失(Cross-Entropy Loss):用于分类问题,特别是二分类和多分类问题。常见的交叉熵损失函数有二分类交叉熵损失(Binary Cross-Entropy Loss)和多分类交叉熵损失(Categorical Cross-Entropy Loss)。
(3)对数似然损失(Log Loss):与交叉熵损失类似,常用于二分类问题。
(4)Hinge损失:用于支持向量机(SVM)中的最大间隔分类问题。
(5)KL散度(Kullback-Leibler Divergence):用于衡量两个概率分布之间的差异。
(6)Huber损失:介于均方误差和绝对值误差之间,对异常值不敏感。
(7)绝对值误差(Mean Absolute Error,MAE):计算预测值与真实值之间的平均绝对差。
(8)二分类Hinge损失:用于支持向量机(SVM)中的二分类问题。
这些仅是常见的损失函数示例,根据具体问题的性质和需求,还可以使用其他定制的损失函数。
五、损失函数代码示例
下面是几个常见损失函数的代码示例,使用Python和一些常见的深度学习框架(如TensorFlow和PyTorch)来实现:
(1)均方误差(Mean Squared Error,MSE):
import tensorflow as tf
# 预测值
predictions = tf.constant([1.0, 2.0, 3.0])
# 真实值
labels = tf.constant([0.5, 2.5, 3.5])
# 计算均方误差
mse = tf.reduce_mean(tf.square(predictions - labels))
# 打印均方误差
print(mse.numpy())
(2)交叉熵损失(Cross-Entropy Loss):
import torch
import torch.nn as nn
# 创建损失函数对象
loss_fn = nn.CrossEntropyLoss()
# 预测值(模型输出)
predictions = torch.tensor([[0.5, 0.2, 0.3], [0.1, 0.8, 0.1]])
# 真实标签
labels = torch.tensor([0, 2])
# 计算交叉熵损失
loss = loss_fn(predictions, labels)
# 打印交叉熵损失
print(loss.item())
3.对数似然损失(Log Loss):
import numpy as np
# 预测概率
probabilities = np.array([0.9, 0.2, 0.8])
# 真实标签(二分类问题中的0和1)
labels = np.array([1, 0, 1])
# 计算对数似然损失
log_loss = -np.mean(labels * np.log(probabilities) + (1 - labels) * np.log(1 - probabilities))
# 打印对数似然损失
print(log_loss)
极大似然函数
问题引入:
-问题Ⅰ:
一个老猎人与其学生一起去打猎,一只野兔前方经过,只听到了两声枪响,,野兔只被一枪打中而倒下。问:是谁打中的呢?
答:极有可能是老猎人打中的。
-问题Ⅱ:
有一个箱子,装有形状相同的黑色球和白色球100个,其中一种颜色90个,另一种颜色球10个.
现从箱中任取一球,结果所取得的球是黑色球。问:黑球多少个?白球多少个?
答:极有可能黑球是90个,白球是10个。
极大似然估计法的依据就是:概率最大的事件最可能发生。
极大似然原理及其数学表述:
若一试验有n个可能结果A1,A2,A3,......,An,现做一试验,若事件A1发生了,则认为事件A1在这n个可能结果中出现的概率最大。
损失函数部分参考:
损失函数(loss function)(基本介绍,作用,场景,特点,常见损失函数,代码示例)_一路向前,积极向上的博客-优快云博客

















 6124
6124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









