







-工作实践(机器视觉应用工程师)
设备:
Jeston Nano Orginx 8G

推理要求:
| 设备 | 640×480 图像推理 时间 / 内存占用 | 1280×720 图像推理 时间 / 内存占用 | 1920×1080 图像推理 时间 / 内存占用 |
|---|---|---|---|
| Jetson Orin Nano 8GB | 0.03 s / 800 MB | 0.07 s / 900 MB | 0.15 s / 1000 MB |
Ubuntu 环境换源(开发板Ubuntu14.04 desktop)
- 备份原文件:
bash
sudo cp /etc/apt/sources.list /etc/apt/sources.list.bak - 编辑软件源列表:
bash
替换为以下内容:sudo nano /etc/apt/sources.listbash
deb http://mirrors.aliyun.com/ubuntu-ports/ focal main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu-ports/ focal main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu-ports/ focal-security main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu-ports/ focal-security main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu-ports/ focal-updates main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu-ports/ focal-updates main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu-ports/ focal-backports main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu-ports/ focal-backports main restricted universe multiverse - 更新软件包索引:
bash
sudo apt-get update
注意:
- 确保系统架构(如 arm64)与镜像源匹配。
- 若仍报错,检查网络或尝试其他镜像源(如清华源)。(这里我使用了移动热点才正常,公司局域网wifi子网太多被清华源屏蔽了)
部署pytorch环境
pytorch NV网站:PyTorch for Jetson - Announcements - NVIDIA Developer Forums
本人的环境使用python3.8,无conda环境
安装环境:
- PyTorch 版本:2.0.0+nv23.05
- torchvision 版本:0.15.0
Torchvision的网站位置:
GitHub - pytorch/vision at release/0.15
安装jetson-stats
打开terminal
sudo apt-get install python3-pip
sudo -H pip3 install jetson-stats
安装完成之后直接在terminal中输入
jtop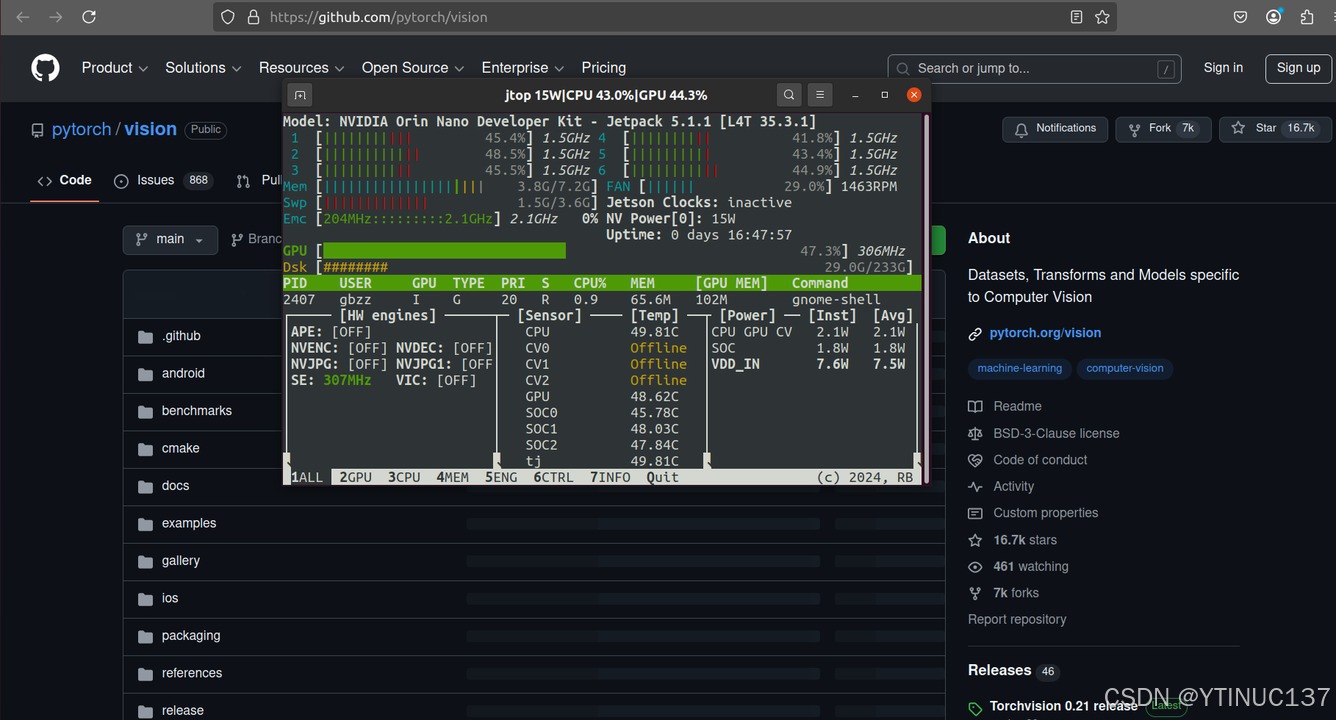
点击INFO查看开发板的参数细节:
安装cuda11.4 cudnn
1.CUDA
terminal输入
sudo apt-get install cuda-toolkit
安装完成之后,将以下复制到 .bashrc文件末尾
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-11.4/lib64
export PATH=$PATH:/usr/local/cuda-11.4/bin
export CUDA_HOME=$CUDA_HOME:/usr/local/cuda-11.4
可以手动打开.bashrc文件,也可以用命令直接打开
sudo gedit ~/.bashrc
配置为sudo apt-get update一下
2.cuDNN
首先查看仓库提供的cuDNN有哪一些。
sudo apt-cache policy libcudnn8
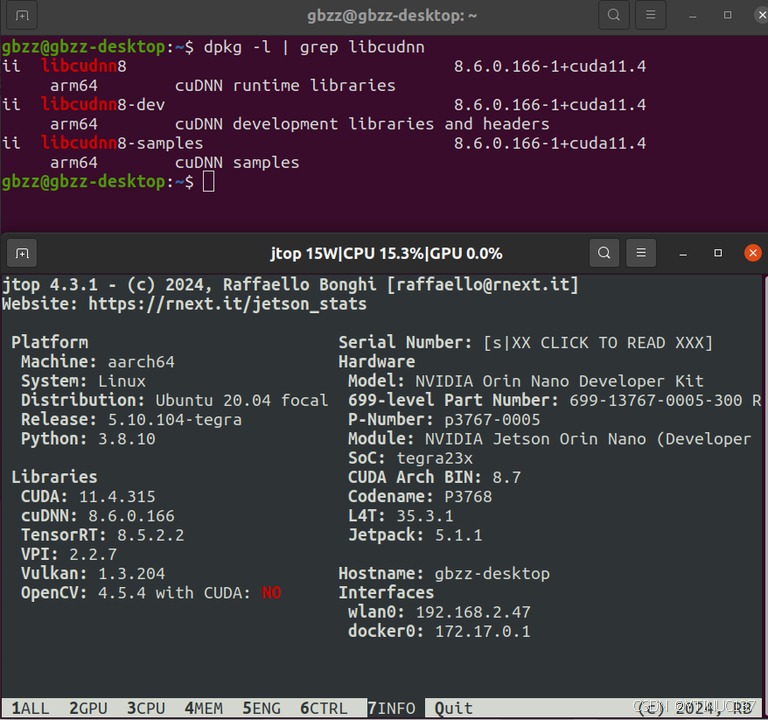
配置完之后去官网下载torch对应的版本,我下载的是
- PyTorch:
2.0.0+nv23.05 - torchvision:
0.15.0(尝试从源码编译安装,但存在问题)
下载torchvison之后,在vision文件夹中
python setup.py install --user检验torch和torchvision的环境是否成功:
以下是 testversion.py 的示例代码,你可以用来验证 torchvision 是否能正常工作:
python
import torch
import torchvision
from torchvision.io import read_image
print(f"torch 版本: {torch.__version__}")
print(f"torchvision 版本: {torchvision.__version__}")
# 检查 CUDA 是否可用
if torch.cuda.is_available():
print("CUDA 可用")
else:
print("CUDA 不可用")
# 简单测试 torchvision 的功能
try:
img = read_image('output.jpg') # 替换为实际的图片路径
print(f"读取的图像形状: {img.shape}")
except Exception as e:
print(f"读取图像时出错: {e}")
Torchvison 报错无法读取照片的解决
依赖安装
- 安装图像库依赖
sudo apt-get update sudo apt-get install libjpeg-dev libpng-dev
运行成功的结果:

segment-anything
亲测,sam的小模型可以正常运行,较大的模型参数运行killed,内存交换不够
YOLOV8检测
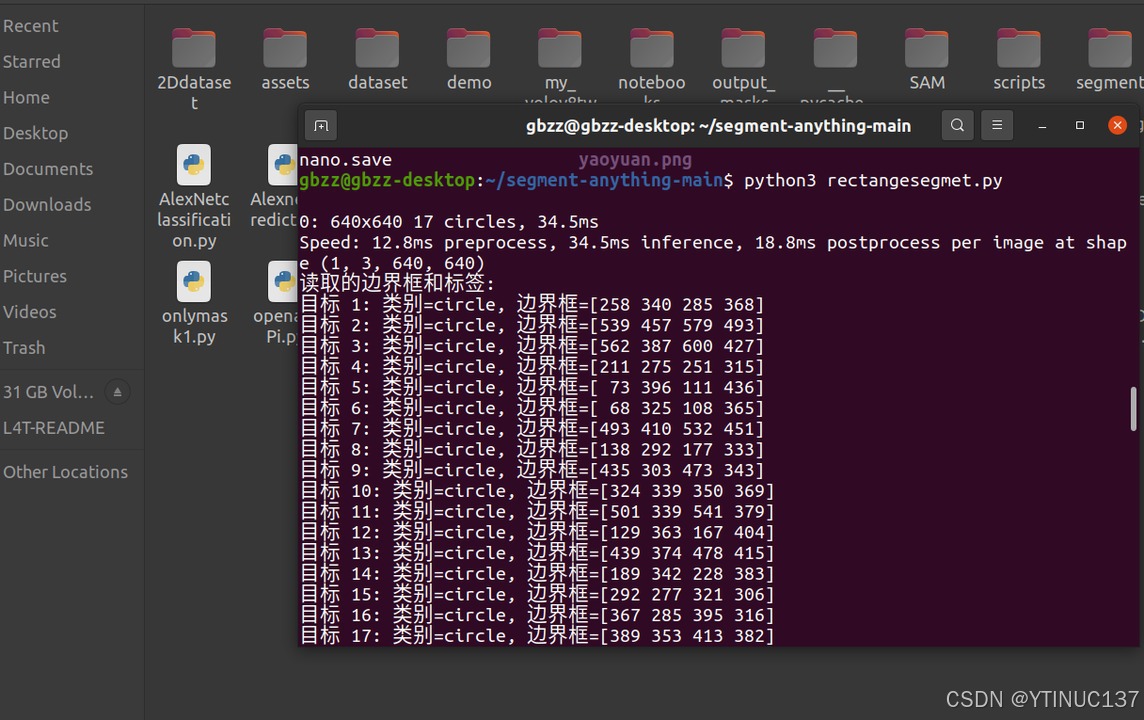

















 110
110

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









